【Important】数据库索引原理
为什么要给表加上主键?
为什么加索引后会使查询变快?
为什么加索引后会使写入、修改、删除变慢?
什么情况下要同时在两个字段上建索引?
想理解索引原理必须清楚一种数据结构(平衡树非二叉)也就是b tree 或者 b+ tree。有的是有哈希桶做索引的数据结构,然而主流的RDBMS都是把平衡树当做数据表默认的索引数据结构的。
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。
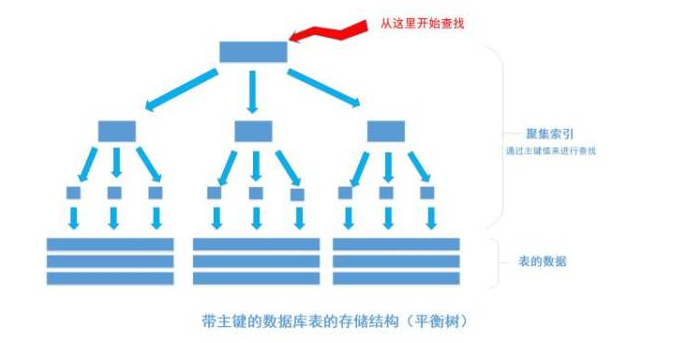
上图就是带有主键的表(聚集索引)的结构图.
其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
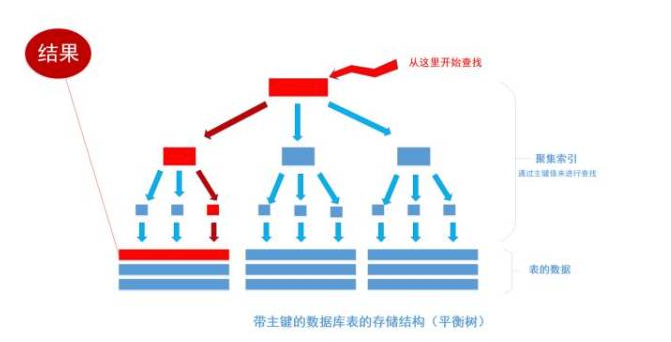
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节, 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是
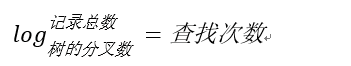
【Important】数据库索引原理的更多相关文章
- mysql进阶(二十七)数据库索引原理
mysql进阶(二十七)数据库索引原理 前言 本文主要是阐述MySQL索引机制,主要是说明存储引擎Innodb. 第一部分主要从数据结构及算法理论层面讨论MySQL数据库索引的数理基础. ...
- B-tree&B+tree&数据库索引原理
B-tree&B+tree:https://www.cnblogs.com/vianzhang/p/7922426.html 数据库索引原理:https://www.cnblogs.com/a ...
- MySQL 深入浅出数据库索引原理(转)
本文转自:https://www.cnblogs.com/aspwebchh/p/6652855.html 前段时间,公司一个新上线的网站出现页面响应速度缓慢的问题, 一位负责这个项目的但并不是搞技术 ...
- mysql数据库----索引原理与慢查询优化
一.介绍 1.什么是索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语 ...
- mysql数据库索引原理及其常用引擎对比
索引原理 树数据结构及其算法简介 B+/-树: - 多路搜索树; - 时间复杂度O(logdN);h为节点出度,d为深度 红黑树: - 节点带有颜色的平衡二叉树 - 时间复杂度O(log2N);h节点 ...
- 数据库索引原理,及MySQL索引类型(转)
在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytable表: CREATE TABLE mytable( ID INT NOT NULL, username ) NOT N ...
- (转)MySql数据库索引原理(总结性)
本文引用文章如链接: http://www.codinglabs.org/html/theory-of-mysql-index.html#more-100 参考书籍:Mysql技术内幕 本文主要是阐述 ...
- MySQL 数据库--索引原理与慢查询优化
索引的原理 本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据. 索引的数据结构 b+ ...
- MySql数据库索引原理
写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储100条记录.如果没有索引,查询将 ...
随机推荐
- iptables设置端口转发
转自:https://blog.csdn.net/sigangjun/article/details/17412821 一 从一台机到另一台机端口转发 启用网卡转发功能 #echo 1 > /p ...
- IOS 数据存储之 SQLite详解
在IOS开发中经常会需要存储数据,对于比较少量的数据可以采取文件的形式存储,比如使用plist文件.归档等,但是对于大量的数据,就需要使用数据库,在IOS开发中数据库存储可以直接通过SQL访问数据库, ...
- hadoop from rookie to ninja - 1. Basic Architecture(基础架构)
1. Daemons(守护进程) 新老架构 老的: Apache Hadoop 1.x (MRv1) 新的: Apache Hadoop 2.x (YARN)-Yet Another Resour ...
- 原创:vsphere概念深入系列五:存储
1.vSphere支持的存储文件格式: 类似于linux下挂载文件系统,需要有驱动器设备,驱动. 挂载后有挂载路径. vSphere 也是一样处理. 挂载名:挂载后可以给存储设备起名,默认为datas ...
- 关于input时间框设置了弹出选择就不能手动输入的控制
<input class="Wdate" onclick="WdatePicker({minDate:'#F{$dp.$D(\'startDate\');}',ma ...
- Golang select
Golang下select的功能和Linux IO复用中的select, poll, epoll相似,是监听 channel 操作,当 channel 操作发生时,触发相应的动作. package m ...
- Attempt to present <TestViewController2: 0x7fd7f8d10f30> on <ViewController: 0x7fd7f8c054c0> whose view is not in the window hierarchy!
当 storyboard里面的 按钮 即连接了 类文件里面的点击方法 又 连接了 storyboard里 另一个 控制器的 modal 就会出现类似Attempt to present & ...
- Charles for Mac(HTTP 监视器和网络抓包工具)破解版安装
1.软件简介 Charles 是在 Mac.Linux 或 Windows 下常用的 http 协议网络包截取工具,在平常的测试与调式过程中,掌握此工具就基本可以不用其他抓包工具了.Charle ...
- 4.翻译系列:EF 6 Code-First默认约定(EF 6 Code-First系列)
原文地址:http://www.entityframeworktutorial.net/code-first/code-first-conventions.aspx EF 6 Code-First系列 ...
- 最新以及历史各版本 .NET Framework 的下载
唔,如题,详见地址:https://www.microsoft.com/net/download/windows