cache基础
cache是系统中的一块快速SRAM,价格高,但是访问速度快,可以减少CPU到main memory的latency。
cache中的术语有:
1) Cache hits,表示可以在cache中,查找到相应地址的entry。
2) Cache Miss,表示在cache中,找不到相应地址的entry。
3) Snoop,cache不断监视transaction的地址线,来不间断的检查地址地址是否在cache中。
4) Snarf,从main memory中读出数据,同时更新cache中的旧值,称为Snarf。
5) Dirty Data,cache中的数据,是最新的,但是main memory中的数据还未更新,称cache中的数据为dirty。Stale Data类似。
arm架构中的cache架构是harvard结构的,分为data cache和inst cache。
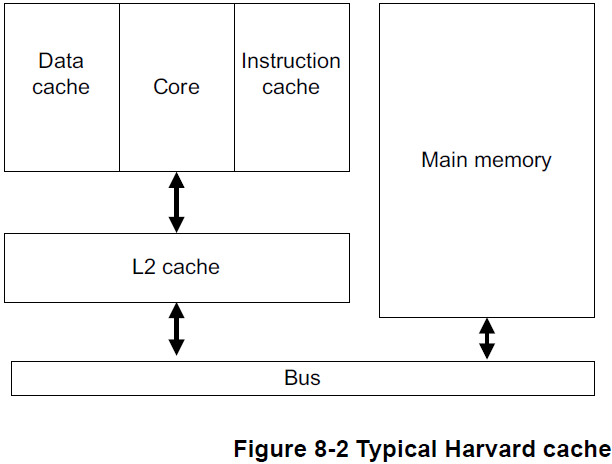
其中L1 cache,一般直接集成到core中,大小多是2-way,4-way,16KB和32KB,cache line一般是32byte或者64byte。
可以实现为VIPT或者PIPT。
L2 cache,可以集成到core中,也可以单独作为一个external block,大小多是8-way以上,256KB,512KB,1M等,cache line也是32byte,64byte。
一般实现为PIPT。
cache的架构,分为read architecture,write policy,allocation policy。
1) read分为,Look Aside和Look Through,
Look Aside,main memory和cache都在同一时间,看到同一bus上的trans。
优点:减少了cache miss下的 memory访问时间,
缺点:在一个core访问main memory时,另一个core不能访问cache。
Look Through,
不管是哪一种的read architecture,cache miss之后,从main memory中得到的value都会被Snarf到cache中。
2) write policy,
write-back时,将数据写到cache中,cache就像一个buffer,在evict一个新的cache entry时,才会将cache写会main memory。
存在cache和main memory的consistency问题。需要进行cache maintenance操作(如cache line置换,mmu page置换修改等),
主要分为cache invalid(舍弃cache中的值,将valid flag置零)和cache update操作(更新main memory的值为cache中的值)。
write-Through时,读写性能要低一些,但是main memory中都是最新的value。不存在cache和main memory的一致性问题。
3) cache miss之后,是否allocate新的entry:
read-allocated;读操作miss之后,先从main memory中读取数据给core,之后在进行cache line snarf。
write-allocated;在write miss之后,需要先进行burst read,进行cache line snarf,之后进行write back操作(一般与write back一起使用)。
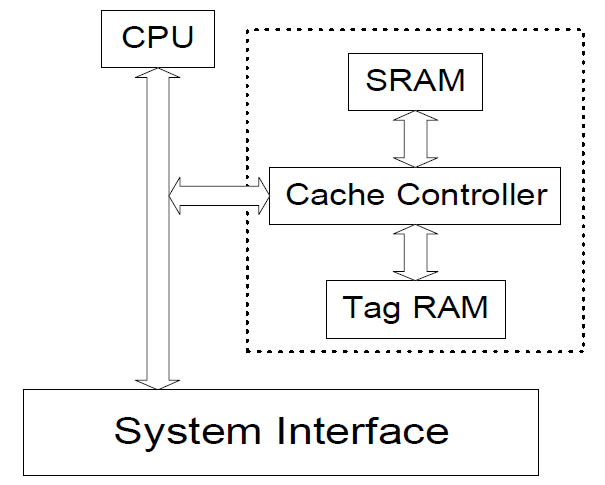
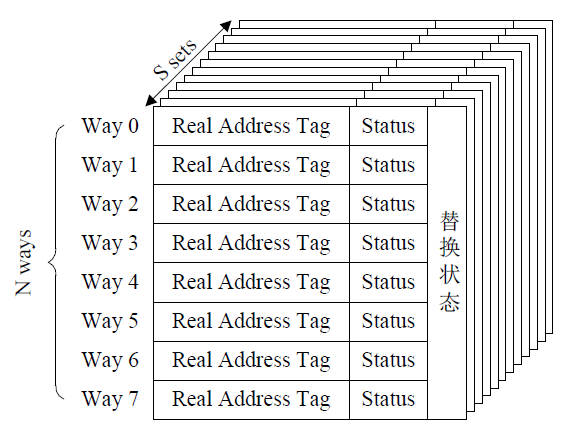
cache block会被分为三个functional blocks,Data RAM,TAG RAM,Cache Controller。每个cache 单元需要保存address,data,status等信息,所以cache真正的大小会比data ram大很多。
1) cache controller也会根据memory request是否是cacheable的来进行cache的寻址操作。
2) tag cache,主要存储VA,PA的地址索引。平时所指的cache size并不包含tag ram的大小。
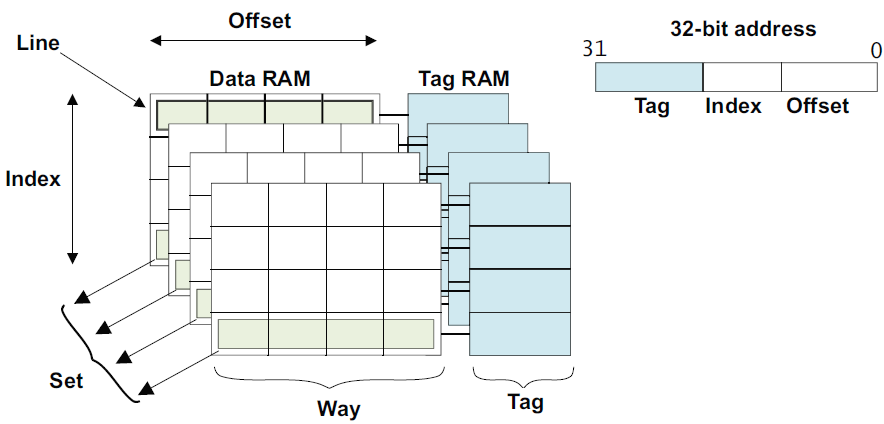
3) offset寻址具体的word,index寻址某一个way,也就是某一个cache line,tag主要做地址校对,最终选择tag匹配的那一个set。
在set-associate结构的cache中,main memory中所有index相同的地址,都只能放在对应的way中。
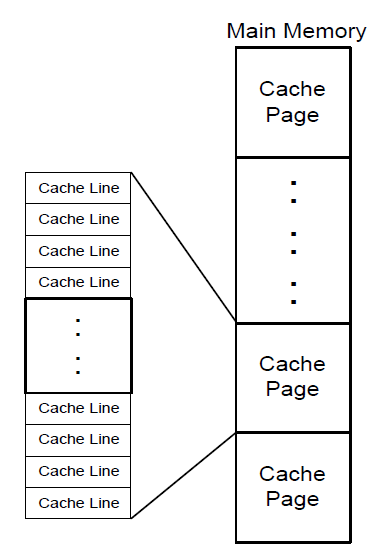
Cache的organization:
1) Cache Page,main memory中被等大小的分为的piece,称为cache pages。
cache page的大小,不但与总的cache size有关,与cache的organization也有关。
2) Cache line,cache page中更小的单元,cache缓存的最小单位。
cache的组织结构有三种,
1) 分为full-Associative,全相联映射。没有cache page的概念,每个cache line直接对应到随机的某个memory line中。
缺点是,TAG ram会比较大,索引会比较慢,一般应用在cache较小的地方,如tlb或者predict buffer中。
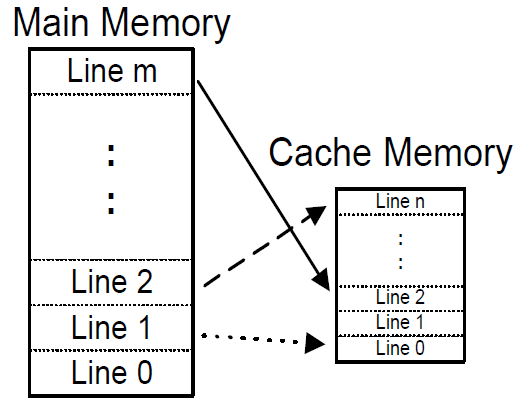
2) Direct-Map,直接映射,也称为1-way associative,main memory分为多个cache page,中的第n line,必须放在cache page的第n行。
复杂度不高,但是,性能很差,常常需要evict其他的cache line,不够灵活。
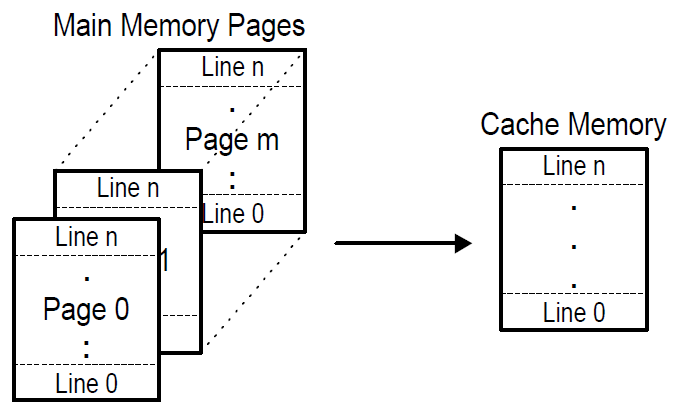
3) N-way Set-Associative,组映射,比如2-way,4-way等,还有一个Set的概念,表示cache page的行数。
每个组分为N份,N称为cache way。每个cache way内部的映射,就与direct mapping相同,
set到main memory的映射,随意,与full-associative相同。
所以一块main memory,首先随意映射一块地址到set中,然后每个set在平分为几个way,直接查找几个way即可。
way中的line 映射,是一一对应的,不能够随意破坏行的顺序。
2 way的映射图:
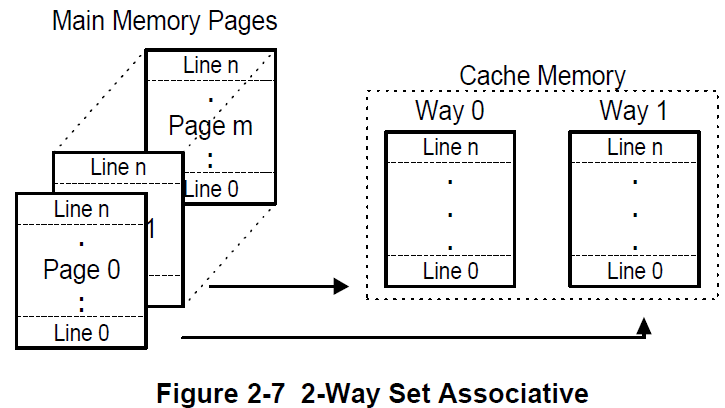
在使用N-Ways Set-Associative时,这是一种阵列的表现方式:
一个组里有N行,其实是N个set,但是set中的每一行与main memory分的cache page中的行数是一样的。
cache首先被分为多个Set,S等于1时,也就是1个Set,这时,等同于Direct-Associative。
N等于1时,也就是说1个Way,这时,等同于Full Mapped。
cache的大小等于cache_line_size * way_num * set_num
cache line的结构:
1) data段存放cache line中的数据,大小通常为32byte或64byte,一个bus的wrap操作。
2) status段,存放cache的状态,可以是MOESI等。
3) Tag段,存放部分物理地址信息,可能包含虚拟地址信息,(VA的Cache索引可以与VA的地址转换同时进行)
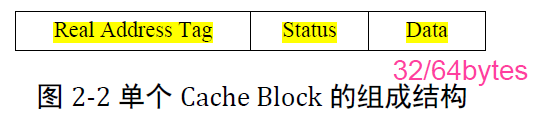
PA地址的cache索引,最低位是word的寻址,之后是way(cache line)的寻址,再之后才是tag的寻址;
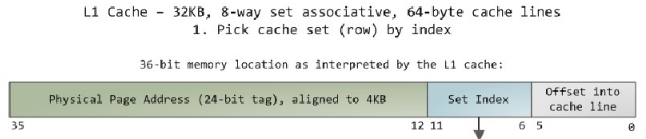
cache hier的问题:在不同的微架构中,L1与L2的关系可以是inclusive的,也可以是exclusive的,
inclusive cache:相同的data可以存放在Both L1和L2中。
exclusive cache:相同的data只能放在L1或者L2中,不能同时存在。
目前一般使用inclusive cache类型,每次cache miss,可以从下一级的cache中寻找,load。而exclusive cache,每次cache miss,只能去main memory中load。
但是exclusive cache比较节省cache size。
cache基础的更多相关文章
- Cache基础知识OR1200在ICache一个简短的引论
以下摘录<步骤吓得核心--软-core处理器的室内设计与分析>一本书 12.1 Cache基本知识 12.1.1 Cache的作用 处理器的设计者通常会声称其设计的处理器一秒钟能做多少次乘 ...
- OpenRisc-41-or1200的cache模块分析
引言 为CPU提供足够的,稳定的指令流和数据流是计算机体系结构设计中两个永恒的话题.为了给CPU提供指令流,需要设计分支预测机构,为了给CPU提供数据流,就需要设计cache了.其实,无论是insn还 ...
- Guava Cache探索及spring项目整合GuavaCache实例
背景 对于高频访问但是低频更新的数据我们一般会做缓存,尤其是在并发量比较高的业务里,原始的手段我们可以使用HashMap或者ConcurrentHashMap来存储. 这样没什么毛病,但是会面临一个问 ...
- Cortex_m7内核cache深入了解和应用
一,cache概述 从下图可以看出,从M7内核才开始有的cache,这对于从M0,M3,M4一路走来的小伙伴来说,多了一个cache就多了一个障碍. Cortex-M7 core with 32K/3 ...
- 并发读写缓存实现机制(一):为什么ConcurrentHashMap可以这么快?
大家都知道ConcurrentHashMap的并发读写速度很快,但为什么它会这么快?这主要归功于其内部数据结构和独特的hash运算以及分离锁的机制.做游戏性能很重要,为了提高数据的读写速度,方法之一就 ...
- Retrofit的初次使用
rxretrofitlibrary是一个已经写好的网络框架库,先以本地Module导入到自己的项目中. 1.它的初始化操作大多在自定义的application中完成,如: public class A ...
- wordpress缓存插件使用提高网站速度
WordPress是世界上使用量最多的CMS,由于程序非常吃主机性能,正常情况下当页面被访问时,使用php和mysql. 因此,系统需要消耗RAM和CPU. 如果同一时间有大量访客访问,系统将使用大量 ...
- MyBatis 源码分析-项目总览
MyBatis 源码分析-项目总览 1.概述 本文主要大致介绍一下MyBatis的项目结构.引用参考资料<MyBatis技术内幕> 此外,https://mybatis.org/mybat ...
- Mybatis源码学习第六天(核心流程分析)之Executor分析
今Executor这个类,Mybatis虽然表面是SqlSession做的增删改查,其实底层统一调用的是Executor这个接口 在这里贴一下Mybatis查询体系结构图 Executor组件分析 E ...
随机推荐
- OC中如何优化代理是否响应某个方法
看以下示例代码: if([_delegate respondsToSelector: @selector(someClassDidSomething:)){ [_delegate someClassD ...
- Appium入门(8)__控件定位
部分摘自:http://www.testclass.net/appium/appium-base-find-element/ appium 通过 uiautomatorviewer.bat 工具来查看 ...
- 2017-2018-2 20165336 实验四《Android开发基础》实验报告
20165336 实验四 Android程序设计 一.实验报告封面 课程:Java程序设计 班级:1653班 姓名:康志强 学号:20165336 指导教师:娄嘉鹏 实验日期:2018年5月14日 实 ...
- Java基础知识(JAVA集合框架之List与Set)
List和Set概述数组必须存放同一种元素.StringBuffer必须转换成字符串才能使用,如果想拿出单独的一个元素几乎不可能.数据有很多使用对象存,对象有很多,使用集合存. 集合容器因为内部的数据 ...
- what's the python之面向对象
编程分为面向过程和面向对象,首先我们要了解什么是面向对象. 面向对象 面向过程就是我们之前学的内容,主要是函数式,其核心是过程,过程即解决问题的步骤,面向过程的设计就好比精心设计好一条流水线,考虑周全 ...
- Spark之数据倾斜 --采样分而治之解决方案
1 采样算法解决数据倾斜的思想 2 采样算法在spark数据倾斜中的具体操作
- js中的offsetLeft和style.left
(1)style.left是带单位"px"的,而offsetLeft没有单位,另外,style.left必须是内联样式,或者在JS中通过style.left赋值,否则取得的将为空字 ...
- Django-分页、中间件和请求的声明周期
一.分页 相关连接:https://www.cnblogs.com/kongzhagen/p/6640975.html 一.Django的分页器(paginator) 1.view.py 视图 fro ...
- PLSQL的SQL%NOTFOUND的使用场景
SELECT * INTO v_ticketStorageRow FROM BDM_TICKET_STORAGE WHERE p_startTicketNo >= START_NO_ AND p ...
- [LeetCode] 系统刷题5_Dynamic Programming
Dynamic Programming 实际上是[LeetCode] 系统刷题4_Binary Tree & Divide and Conquer的基础上,加上记忆化的过程.就是说,如果这个题 ...