cache基础
cache是系统中的一块快速SRAM,价格高,但是访问速度快,可以减少CPU到main memory的latency。
cache中的术语有:
1) Cache hits,表示可以在cache中,查找到相应地址的entry。
2) Cache Miss,表示在cache中,找不到相应地址的entry。
3) Snoop,cache不断监视transaction的地址线,来不间断的检查地址地址是否在cache中。
4) Snarf,从main memory中读出数据,同时更新cache中的旧值,称为Snarf。
5) Dirty Data,cache中的数据,是最新的,但是main memory中的数据还未更新,称cache中的数据为dirty。Stale Data类似。
arm架构中的cache架构是harvard结构的,分为data cache和inst cache。
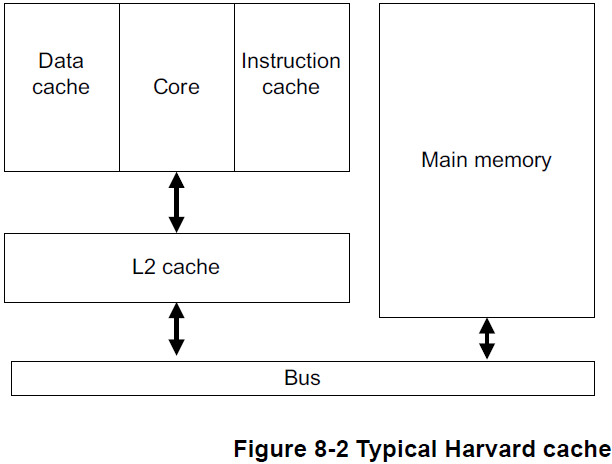
其中L1 cache,一般直接集成到core中,大小多是2-way,4-way,16KB和32KB,cache line一般是32byte或者64byte。
可以实现为VIPT或者PIPT。
L2 cache,可以集成到core中,也可以单独作为一个external block,大小多是8-way以上,256KB,512KB,1M等,cache line也是32byte,64byte。
一般实现为PIPT。
cache的架构,分为read architecture,write policy,allocation policy。
1) read分为,Look Aside和Look Through,
Look Aside,main memory和cache都在同一时间,看到同一bus上的trans。
优点:减少了cache miss下的 memory访问时间,
缺点:在一个core访问main memory时,另一个core不能访问cache。
Look Through,
不管是哪一种的read architecture,cache miss之后,从main memory中得到的value都会被Snarf到cache中。
2) write policy,
write-back时,将数据写到cache中,cache就像一个buffer,在evict一个新的cache entry时,才会将cache写会main memory。
存在cache和main memory的consistency问题。需要进行cache maintenance操作(如cache line置换,mmu page置换修改等),
主要分为cache invalid(舍弃cache中的值,将valid flag置零)和cache update操作(更新main memory的值为cache中的值)。
write-Through时,读写性能要低一些,但是main memory中都是最新的value。不存在cache和main memory的一致性问题。
3) cache miss之后,是否allocate新的entry:
read-allocated;读操作miss之后,先从main memory中读取数据给core,之后在进行cache line snarf。
write-allocated;在write miss之后,需要先进行burst read,进行cache line snarf,之后进行write back操作(一般与write back一起使用)。
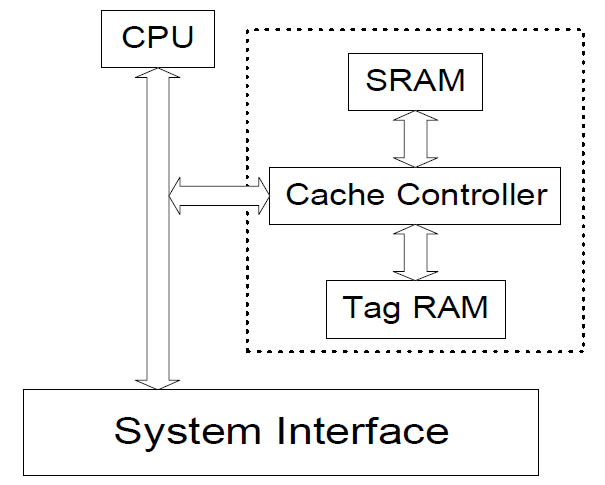
cache block会被分为三个functional blocks,Data RAM,TAG RAM,Cache Controller。每个cache 单元需要保存address,data,status等信息,所以cache真正的大小会比data ram大很多。
1) cache controller也会根据memory request是否是cacheable的来进行cache的寻址操作。
2) tag cache,主要存储VA,PA的地址索引。平时所指的cache size并不包含tag ram的大小。
3) offset寻址具体的word,index寻址某一个way,也就是某一个cache line,tag主要做地址校对,最终选择tag匹配的那一个set。
在set-associate结构的cache中,main memory中所有index相同的地址,都只能放在对应的way中。
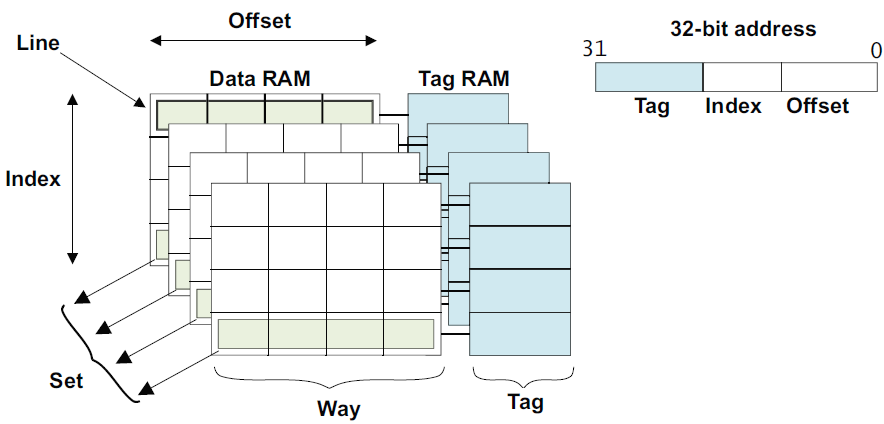
Cache的organization:
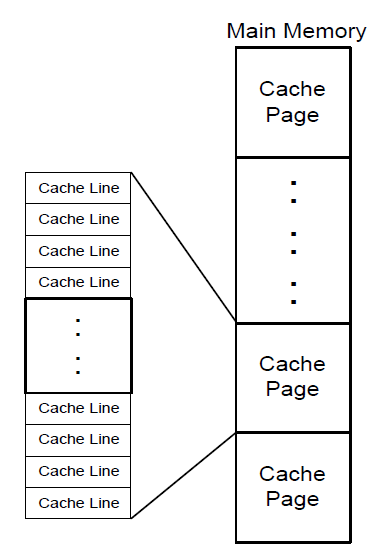
1) Cache Page,main memory中被等大小的分为的piece,称为cache pages。
cache page的大小,不但与总的cache size有关,与cache的organization也有关。
2) Cache line,cache page中更小的单元,cache缓存的最小单位。
cache的组织结构有三种,
1) 分为full-Associative,全相联映射。没有cache page的概念,每个cache line直接对应到随机的某个memory line中。
缺点是,TAG ram会比较大,索引会比较慢,一般应用在cache较小的地方,如tlb或者predict buffer中。
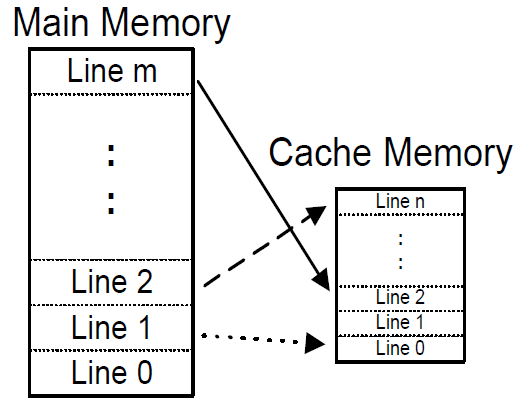
2) Direct-Map,直接映射,也称为1-way associative,main memory分为多个cache page,中的第n line,必须放在cache page的第n行。
复杂度不高,但是,性能很差,常常需要evict其他的cache line,不够灵活。
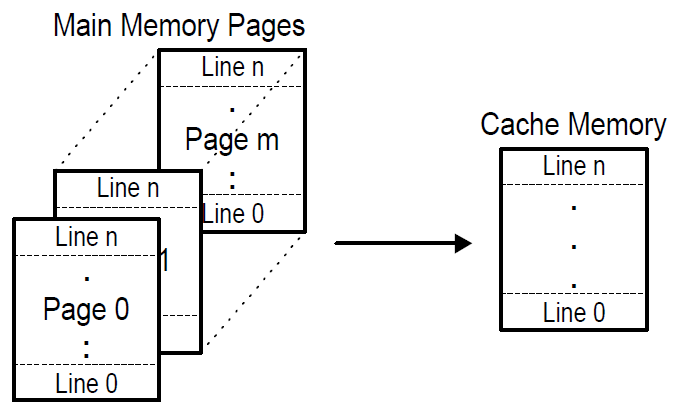
3) N-way Set-Associative,组映射,比如2-way,4-way等,还有一个Set的概念,表示cache page的行数。
每个组分为N份,N称为cache way。每个cache way内部的映射,就与direct mapping相同,
set到main memory的映射,随意,与full-associative相同。
所以一块main memory,首先随意映射一块地址到set中,然后每个set在平分为几个way,直接查找几个way即可。
way中的line 映射,是一一对应的,不能够随意破坏行的顺序。
2 way的映射图:
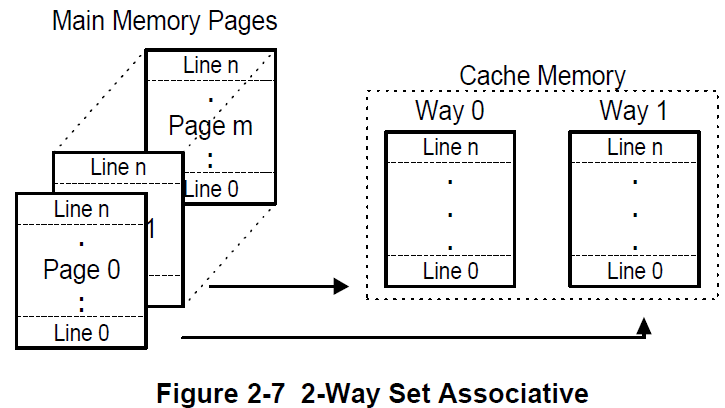
在使用N-Ways Set-Associative时,这是一种阵列的表现方式:
一个组里有N行,其实是N个set,但是set中的每一行与main memory分的cache page中的行数是一样的。
cache首先被分为多个Set,S等于1时,也就是1个Set,这时,等同于Direct-Associative。
N等于1时,也就是说1个Way,这时,等同于Full Mapped。
cache的大小等于cache_line_size * way_num * set_num
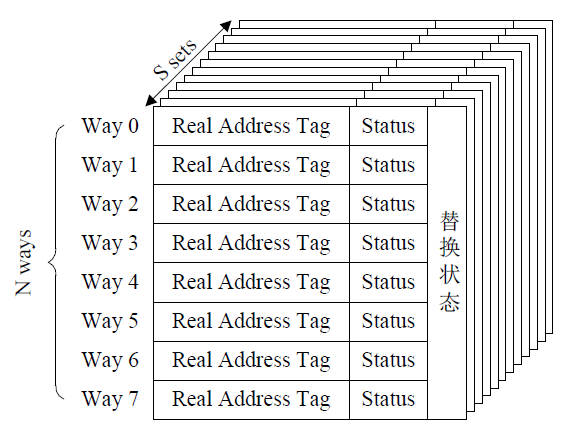
cache line的结构:
1) data段存放cache line中的数据,大小通常为32byte或64byte,一个bus的wrap操作。
2) status段,存放cache的状态,可以是MOESI等。
3) Tag段,存放部分物理地址信息,可能包含虚拟地址信息,(VA的Cache索引可以与VA的地址转换同时进行)
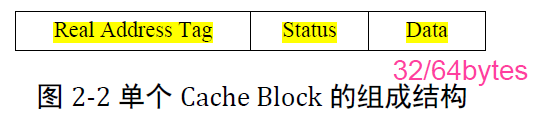
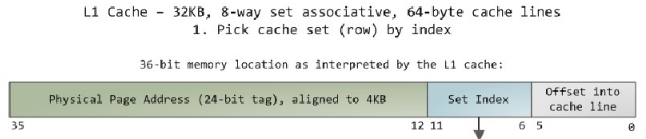
PA地址的cache索引,最低位是word的寻址,之后是way(cache line)的寻址,再之后才是tag的寻址;
cache hier的问题:在不同的微架构中,L1与L2的关系可以是inclusive的,也可以是exclusive的,
inclusive cache:相同的data可以存放在Both L1和L2中。
exclusive cache:相同的data只能放在L1或者L2中,不能同时存在。
目前一般使用inclusive cache类型,每次cache miss,可以从下一级的cache中寻找,load。而exclusive cache,每次cache miss,只能去main memory中load。
但是exclusive cache比较节省cache size。
cache基础的更多相关文章
- Cache基础知识OR1200在ICache一个简短的引论
以下摘录<步骤吓得核心--软-core处理器的室内设计与分析>一本书 12.1 Cache基本知识 12.1.1 Cache的作用 处理器的设计者通常会声称其设计的处理器一秒钟能做多少次乘 ...
- OpenRisc-41-or1200的cache模块分析
引言 为CPU提供足够的,稳定的指令流和数据流是计算机体系结构设计中两个永恒的话题.为了给CPU提供指令流,需要设计分支预测机构,为了给CPU提供数据流,就需要设计cache了.其实,无论是insn还 ...
- Guava Cache探索及spring项目整合GuavaCache实例
背景 对于高频访问但是低频更新的数据我们一般会做缓存,尤其是在并发量比较高的业务里,原始的手段我们可以使用HashMap或者ConcurrentHashMap来存储. 这样没什么毛病,但是会面临一个问 ...
- Cortex_m7内核cache深入了解和应用
一,cache概述 从下图可以看出,从M7内核才开始有的cache,这对于从M0,M3,M4一路走来的小伙伴来说,多了一个cache就多了一个障碍. Cortex-M7 core with 32K/3 ...
- 并发读写缓存实现机制(一):为什么ConcurrentHashMap可以这么快?
大家都知道ConcurrentHashMap的并发读写速度很快,但为什么它会这么快?这主要归功于其内部数据结构和独特的hash运算以及分离锁的机制.做游戏性能很重要,为了提高数据的读写速度,方法之一就 ...
- Retrofit的初次使用
rxretrofitlibrary是一个已经写好的网络框架库,先以本地Module导入到自己的项目中. 1.它的初始化操作大多在自定义的application中完成,如: public class A ...
- wordpress缓存插件使用提高网站速度
WordPress是世界上使用量最多的CMS,由于程序非常吃主机性能,正常情况下当页面被访问时,使用php和mysql. 因此,系统需要消耗RAM和CPU. 如果同一时间有大量访客访问,系统将使用大量 ...
- MyBatis 源码分析-项目总览
MyBatis 源码分析-项目总览 1.概述 本文主要大致介绍一下MyBatis的项目结构.引用参考资料<MyBatis技术内幕> 此外,https://mybatis.org/mybat ...
- Mybatis源码学习第六天(核心流程分析)之Executor分析
今Executor这个类,Mybatis虽然表面是SqlSession做的增删改查,其实底层统一调用的是Executor这个接口 在这里贴一下Mybatis查询体系结构图 Executor组件分析 E ...
随机推荐
- [elastic search][redis] 初试 ElasticSearch / redis
现有项目组,工作需要. http://www.cnblogs.com/xing901022/p/4704319.html Elastic Search权威指南(中文版) https://es.xiao ...
- spark学习笔记3
Spark 支持在集群范围内将数据集缓存至每一个节点的内存中,可避免数据传输,当数据需要重复访问时这个特征非常有用,例如查询体积小的“热”数据集,或是运行如 PageRank 的迭代算法.调用 cac ...
- 抽屉之Tornado实战(1)--分析与架构
抽屉之Tornado实战(1)--分析与架构 项目模拟地址:http://dig.chouti.com/ 知识点应用: AJAX 用于偷偷发请求 原生ajax jQuery ajax($.aj ...
- shiro入门实例,基于ini配置
基于ini或者关系数据库的,其实都是一样的,重要的是思想. # ==================================================================== ...
- 终于解决“Git Windows客户端保存用户名与密码”的问题(转载)
add by zhj:不建议用这种方法,建议用SSH,参见 TortoiseGit密钥的配置 http://www.cnblogs.com/ajianbeyourself/p/3817364.html ...
- 【Linux】常用指令、ps查看进程、kill杀进程、启动停止tomcat命令、查看日志、查看端口、find查找文件
1.说出 10 个 linux 常用的指令 1) ls 查看目录中的文件 2)cd /home 进入 '/ home' 目录:cd .. 返回上一级目录:cd ../.. 返回上两级目录 3)mkdi ...
- 【雅思】【写作】【大作文】Report
•Report •主要分类 •两个问题 • •1. 原因,解决办法 • •2. 原因,积极还是消极 • •3. Freestyle •报告型 •In cities and towns all over ...
- 误删除innodb ibdata数据文件
今天在群里看到有人说不熟悉innodb把ibdata(数据文件)和ib_logfile(事务日志)文件误删除了.不知道怎么解决.当时我也不知道怎么办.后来查阅相关资料.终找到解决方法.其实恢复也挺简单 ...
- chmod a+r file:给所有用户添加读的权限
chmod a+r *:用户自己使用此命令,柯给所有用户添加可读的权限 超级用户给其他用户设置权限:sudo chmod a+rx /home/user 使所有人可以访问,读取文件,bu no W ...
- 001-RESTful服务最佳实践-RestFul准则、HTTP动词表示含义、合理的资源命名、响应格式XML和JSON
一.概述 因为REST是一种架构风格而不是严格的标准,所以它可以灵活地实现.由于这种灵活性和结构自由度,对设计最佳实践也有很大的差异. API的方向是从应用程序开发人员的角度考虑设计选择. 幂等性 不 ...