074 hbase与mapreduce集成
一:运行给定的案例
1.获取jar包里的方法

2.运行hbase自带的mapreduce程序
lib/hbase-server-0.98.6-hadoop2.jar
3.具体运行
注意命令:mapredcp。
HADOOP_CLASSPATH是当前运行时需要的环境。

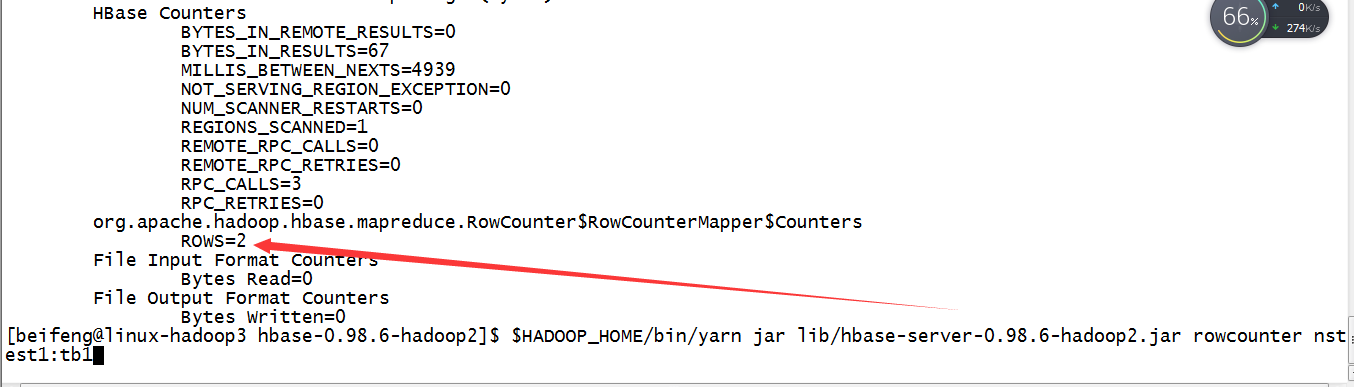
4.运行一个小方法
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar rowcounter nstest1:tb1
二:自定义hbase的数据拷贝
1.需求
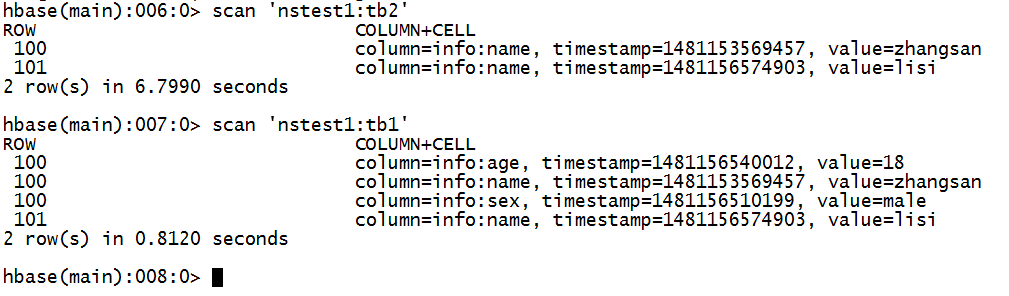
将nstest1:tb1的数据info:name列拷贝到nstest1:tb2
2.新建tb2表

3.书写mapreduce程序
输入:rowkey,result。
package com.beifeng.bigdat; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class HBaseMRTest extends Configured implements Tool{
/**
* map
* @author *
*/
public static class tbMap extends TableMapper<ImmutableBytesWritable, Put>{ @Override
protected void map(ImmutableBytesWritable key, Result value,Context context) throws IOException, InterruptedException {
Put put=new Put(key.get());
for(Cell cell:value.rawCells()){
if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
put.add(cell);
context.write(key, put);
}
}
}
} }
/**
* reduce
* @author *
*/
public static class tbReduce extends TableReducer<ImmutableBytesWritable, Put, ImmutableBytesWritable>{ @Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values,Context context)throws IOException, InterruptedException {
for(Put put:values){
context.write(key, put);
}
} } public int run(String[] args) throws Exception {
Configuration conf=super.getConf();
Job job =Job.getInstance(conf, "hbasemr");
job.setJarByClass(HBaseMRTest.class);
Scan scan=new Scan();
TableMapReduceUtil.initTableMapperJob(
"nstest1:tb1",
scan,
tbMap.class,
ImmutableBytesWritable.class,
Put.class,
job);
TableMapReduceUtil.initTableReducerJob(
"nstest1:tb2",
tbReduce.class,
job);
boolean issucess=job.waitForCompletion(true);
return issucess?0:1;
}
public static void main(String[] args) throws Exception{
Configuration conf=HBaseConfiguration.create();
int status=ToolRunner.run(conf, new HBaseMRTest(), args);
System.exit(status);
} }
4.打成jar包
5.运行语句
加上需要的export前提。
$HADOOP_HOME/bin/yarn jar /etc/opt/datas/HBaseMR.jar com.beifeng.bigdat.HBaseMRTest
6.效果
074 hbase与mapreduce集成的更多相关文章
- HBase概念学习(七)HBase与Mapreduce集成
这篇文章是看了HBase权威指南之后,依据上面的解说搬下来的样例,可是略微有些不一样. HBase与mapreduce的集成无非就是mapreduce作业以HBase表作为输入,或者作为输出,也或者作 ...
- HBase 与 MapReduce 集成
6. HBase 与 MapReduce 集成 6.1 官方 HBase 与 MapReduce 集成 查看 HBase 的 MapReduce 任务的执行:bin/hbase mapredcp; 环 ...
- hbase与mapreduce集成
一:运行给定的案例 1.获取jar包里的方法 2.运行hbase自带的mapreduce程序 lib/hbase-server-0.98.6-hadoop2.jar 3.具体运行 4.运行一个小方法 ...
- 【HBase】HBase与MapReduce集成——从HDFS的文件读取数据到HBase
目录 需求 步骤 一.创建maven工程,导入jar包 二.开发MapReduce程序 三.结果 需求 将HDFS路径 /hbase/input/user.txt 文件的内容读取并写入到HBase 表 ...
- hbase运行mapreduce设置及基本数据加载方法
hbase与mapreduce集成后,运行mapreduce程序,同时需要mapreduce jar和hbase jar文件的支持,这时我们需要通过特殊设置使任务可以同时读取到hadoop jar和h ...
- 【HBase】HBase与MapReduce的集成案例
目录 需求 步骤 一.创建maven工程,导入jar包 二.开发MapReduce程序 三.运行结果 HBase与MapReducer集成官方帮助文档:http://archive.cloudera. ...
- 大数据技术之_11_HBase学习_02_HBase API 操作 + HBase 与 Hive 集成 + HBase 优化
第6章 HBase API 操作6.1 环境准备6.2 HBase API6.2.1 判断表是否存在6.2.2 抽取获取 Configuration.Connection.Admin 对象的方法以及关 ...
- Hbase与hive集成与对比
HBase与Hive的对比 1.Hive (1) 数据仓库 Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询. (2) 用于数据分析.清洗 ...
- 《OD大数据实战》HBase整合MapReduce和Hive
一.HBase整合MapReduce环境搭建 1. 搭建步骤1)在etc/hadoop目录中创建hbase-site.xml的软连接.在真正的集群环境中的时候,hadoop运行mapreduce会通过 ...
随机推荐
- checklistboxx 多选取值 和选中
for (int i = 0; i < cklist.Items.Count; i++) { if (cklist.GetItemChecked(i)) { //修改子菜单的父节点为此菜单的id ...
- Linux inotify功能及实现原理【转】
转自:http://blog.csdn.net/myarrow/article/details/7096460 1. inotify主要功能 它是一个内核用于通知用户空间程序文件系统变化的机制. 众所 ...
- .net active up mail 邮件发送
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threa ...
- kafka系列十、kafka常用管理命令
一.Topic管理 1.创建topic kafka-topics.sh --zookeeper 47.52.199.52:2181 --create --topic test-15 --replica ...
- 【转】assert预处理宏与预处理变量
assert assert是一个预处理宏,由预处理器管理而非编译器管理,所以使用时都不用命名空间声明,如果你写成std::assert反而是错的.使用assert需要包含cassert或assert. ...
- Word 2017 快捷键
Ctrl + D: 呼出[字体] Ctrl + S: 进行[保存] Ctrl + F: 呼出[导航] Ctrl + D: 呼出[字体] Ctrl + B: 进行[加粗] Ctrl + G: 呼出[查找 ...
- 解决重新安装sqlserver2008报错Reporting Services目录数据库文件存在的问题
删除安装目录如: D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA 目录下的reporting.mdf和日 ...
- Codeforces Round #Pi (Div. 2) C
题意 : 给你一个序列,和 K ,选3 个数,下标严格递增, 满足 为递增的等比数列, 等比为K 思路 : 先统计所有数的个数,枚举等比数列的中间数 A, 计算 A 之后的 A*K的个数, A之前的 ...
- mac安装RabbitMQ
1 下载 地址 http://www.rabbitmq.com/install-standalone-mac.html 2 rabbitmq的安装目录: /Users/ysyc1/rabbitmq_s ...
- 输入年月日判断是当年第几天(if判断)