Luncene学习二《搜索索引》
搜索索引的流程

第一步:创建一个Directory对象,也就是索引库存放的位置
第二步:创建一个IndexReader对象,需要指定Directory对象
第三步:创建一个indexsearcher对象,需要指定IndexReader对象
第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
第五步:执行查询.
第六步:返回查询结果。遍历查询结果并输出。
第七步:关闭IndexReader对象

// 搜索索引
@Test
public void testSearch() throws Exception {
// 第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));// 磁盘
// 第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader indexReader = DirectoryReader.open(directory);
// 第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
Query query = new TermQuery(new Term("fileName", "lucene"));
// 第五步:执行查询。
TopDocs topDocs = indexSearcher.search(query, 10);
// 第六步:返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println(fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println(fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
System.out.println("------------");
}
// 第七步:关闭IndexReader对象
indexReader.close(); }
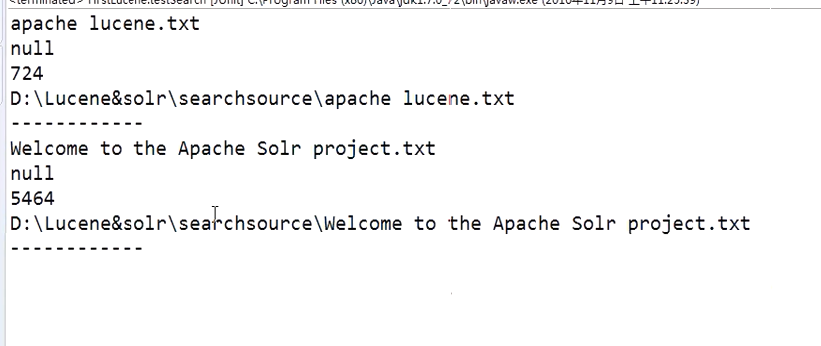
执行之后的效果
Luncene学习二《搜索索引》的更多相关文章
- MySQL学习(二)索引原理及其背后的数据结构
首先区分几个概念: 聚集索引 主索引和辅助索引(即二级索引) innodb中每个表都有一个聚簇索引(clustered index ),除此之外的表上的每个非聚簇索引都是二级索引,又叫辅助索引(sec ...
- ElasticSearch7.3学习(二十六)----搜索(Search)参数总结、结果跳跃(bouncing results)问题解析
1.preference 首先引入一个bouncing results问题,两个document排序,field值相同:不同的shard上,可能排序不同:每次请求轮询打到不同的replica shar ...
- Luncene 学习入门
Lucene是apache组织的一个用java实现全文搜索引擎的开源项目. 其功能非常的强大,api也很简单.总得来说用Lucene来进行建立 和搜索和操作数据库是差不多的(有点像),Document ...
- MySQL学习笔记(三)—索引
一.概述 1.基本概念 在大型数据库中,一张表中要容纳几万.几十万,甚至几百万的的数据,而当这些表与其他表连接后,所得到的新的数据数目更是要大大超出原来的表.当用户检索这么大量的数据时,经 ...
- Python学习二:词典基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7862377.html 邮箱:moyi@moyib ...
- MySQL实战45讲学习笔记:索引(第四讲)
一.索引模型 1.索引的作用: 索引的出现其实是为了提高数据查询的效率,就像书的目录一样 提高数据查询效率 2.索引模型的优缺点比较 二.InnoDB索引模型 1.二叉树是搜索效率最高的,但是实际上大 ...
- mysql学习笔记--数据库索引
一.索引的优点:查询速度快 二.索引的缺点: 1. 增.删.改(数据操作语句)效率低了 2. 索引占用空间 三.索引类型: 1. 普通索引 2. 唯一索引(唯一键) 3. 主键索引:只要主键就自动创建 ...
- pandas学习(创建多层索引、数据重塑与轴向旋转)
pandas学习(创建多层索引.数据重塑与轴向旋转) 目录 创建多层索引 数据重塑与轴向旋转 创建多层索引 隐式构造 Series 最常见的方法是给DataFrame构造函数的index参数传递两个或 ...
- 集成学习二: Boosting
目录 集成学习二: Boosting 引言 Adaboost Adaboost 算法 前向分步算法 前向分步算法 Boosting Tree 回归树 提升回归树 Gradient Boosting 参 ...
随机推荐
- python os.path.basename()方法
返回path最后的文件名.如果path以/或\结尾,那么就会返回空值.即os.path.split(path)的第二个元素. >>> import os >>> p ...
- PYQT5学习笔记之各模块介绍
Qtwidgets模块包含创造经典桌面风格的用户界面提供了一套UI元素的类 Qtwidegts下还有以下常用对象,所以一般使用Qtwidegts时会使用面向对象式编程 QApplication: ap ...
- ResourceBundle与Properties读取配置文件
ResourceBundle与Properties的区别在于ResourceBundle通常是用于国际化的属性配置文件读取,Properties则是一般的属性配置文件读取. ResourceBundl ...
- [转]Hive开发经验问答式总结
本文转载自:http://www.crazyant.net/1625.html 本文是自己开发Hive经验的总结,希望对大家有所帮助,有问题请留言交流. Hive开发经验思维导图 Hive开发经验总结 ...
- flask 使用Flask-SQLAlchemy管理数据库(连接数据库服务器、定义数据库模型、创建库和表)
使用Flask-SQLAlchemy管理数据库 扩展Flask-SQLAlchemy集成了SQLAlchemy,它简化了连接数据库服务器.管理数据库操作会话等各种工作,让Flask中的数据处理体验变得 ...
- Linux基础命令---join
join 找出两个文件中相同的字段,根据相同字段合并两个文件,将合并结果显示到标准输出. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.openSUSE.Fedora ...
- Jmeter压力测试和接口测试
jmeter是apache公司基于java开发的一款开源压力测试工具,体积小,功能全,使用方便,是一个比较轻量级的测试工具,使用起来非常简单.因为jmeter是java开发的,所以运行的时候必须先要安 ...
- jetbrain_ia
在激活Jetbrains旗下任意产品的时候选择激活服务器填入以下地址便可成功激活 http://idea.liyang.io 最新方法(2018.3.4) http://blog.csdn.net/w ...
- 【linux应用】将一个大文件按行拆分成小文件
例如将一个BLM.txt文件分成前缀为 BLM_ 的1000个小文件,后缀为系数形式,且后缀为4位数字形式 先利用 wc -l BLM.txt #读出BLM.txt有多少行. 再利用 split 命令 ...
- P2147 [SDOI2008]洞穴勘测(LCT)
P2147 [SDOI2008]洞穴勘测 裸的LCT. #include<iostream> #include<cstdio> #include<cstring> ...