mysql 缓存机制
了解mysql缓存吗(顺丰)
mysql缓存机制就是缓存sql 文本及缓存结果,用KV形式保存再服务器内存中,如果运行相同的sql,服务器直接从缓存中去获取结果,不需要在再去解析、优化、执行sql。 如果这个表修改了,那么使用这个表中的所有缓存将不再有效,查询缓存值得相关条目将被清空。表中得任何改变是值表中任何数据或者是结构的改变,包括insert,update,delete,truncate,alter table,drop table或者是drop database 包括那些映射到改变了的表的使用merge表的查询,显然,者对于频繁更新的表,查询缓存不合适,对于一些不变的数据且有大量相同sql查询的表,查询缓存会节省很大的性能。
命中条件
缓存存在一个hash表中,通过查询SQL,查询数据库,客户端协议等作为key,在判断命中前,mysql不会解析SQL,而是使用SQL去查询缓存,SQL上的任何字符的不同,如空格,注释,都会导致缓存不命中。如果查询有不确定的数据like now(),current_date(),那么查询完成后结果者不会被缓存,包含不确定的数的是不会放置到缓存中。
工作流程
1.服务器接收SQL,以SQL和一些其他条件为key查找缓存表
2.如果找到了缓存,则直接返回缓存
3.如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等。
4.执行完SQL查询结果以后,将SQL查询结果缓存入缓存表
缓存失败
当某个表正在写入数据,则这个表的缓存(命中缓存,缓存写入等)将会处于失效状态,在Innodb中,如果某个事务修改了这张表,则这个表的缓存在事务提交前都会处于失效状态,在这个事务提交前,这个表的相关查询都无法被缓存。
缓存的内存管理
缓存会在内存中开辟一块内存(query_cache_size)来维护缓存数据,其中大概有40K的空间是用来维护缓存数据的元数据的,例如空间内存,例如空间内存,数据表和查询结果映射,SQL和查询结果映射的。
mysql将这个大内存块分为小内存块(query_cache_min_res_unit),每个小块中存储自身的类型、大小和查询结果数据,还有前后内存块的指针。
mysql需要设置单个小存储块大小,在SQL查询开始(还未得到结果)时就去申请一块内存空间,所以即使你的缓存数据没有达到这个大小也需要这个大小的数据块去保存(like linux filesystem’s block)。如果超出这个内存块的大小,则需要再申请一个内存块。当查询完成发现申请的内存有富余,则会将富余的内存空间是放点,这就会造成内存碎片的问题,见下图
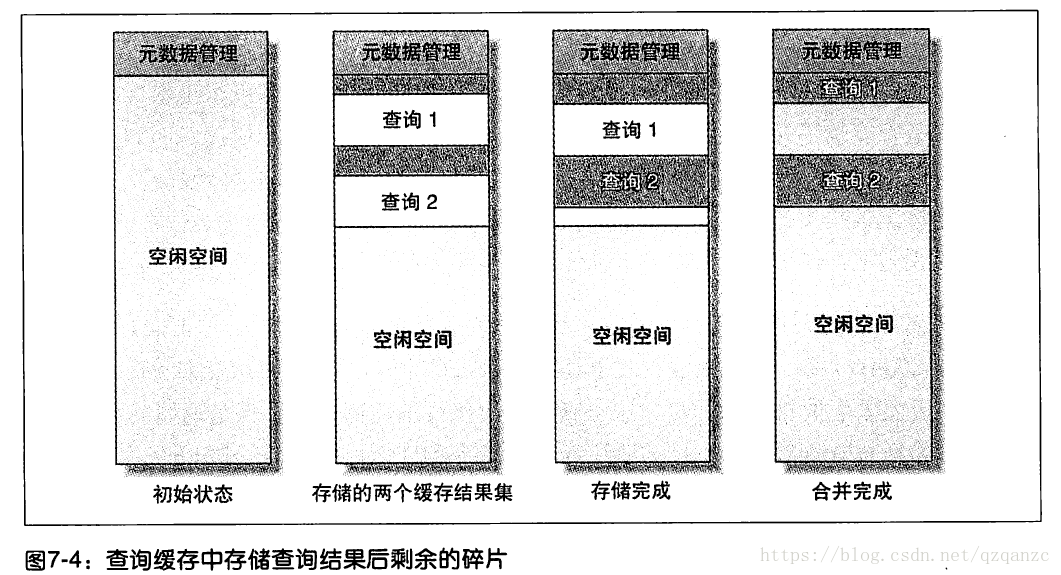
缓存的使用时机
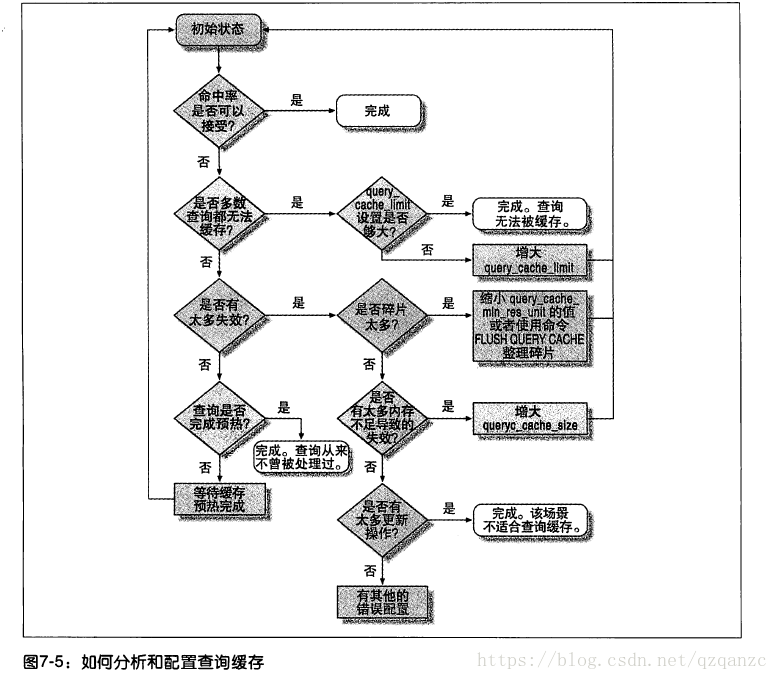
衡量打开缓存是否对系统有性能提升是一个很难的话题
- 通过缓存命中率判断, 缓存命中率 = 缓存命中次数 (Qcache_hits) / 查询次数 (Com_select)
- 通过缓存写入率, 写入率 = 缓存写入次数 (Qcache_inserts) / 查询次数 (Qcache_inserts)
- 通过 命中-写入率 判断, 比率 = 命中次数 (Qcache_hits) / 写入次数 (Qcache_inserts), 高性能MySQL中称之为比较能反映性能提升的指数,一般来说达到3:1则算是查询缓存有效,而最好能够达到10:1
缓存参数配置
- query_cache_type: 是否打开缓存
可选项
1) OFF: 关闭
2) ON: 总是打开
3) DEMAND: 只有明确写了SQL_CACHE的查询才会吸入缓存 - query_cache_size: 缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL实际分配可能跟这个数值不同(感觉这个应该跟文件系统的blcok大小有关)
- query_cache_min_res_unit: 分配内存块时的最小单位大小
- query_cache_limit: MySQL能够缓存的最大结果,如果超出,则增加 Qcache_not_cached的值,并删除查询结果
- query_cache_wlock_invalidate: 如果某个数据表被锁住,是否仍然从缓存中返回数据,默认是OFF,表示仍然可以返回
GLOBAL STAUS 中 关于 缓存的参数解释:
Qcache_free_blocks: 缓存池中空闲块的个数
Qcache_free_memory: 缓存中空闲内存量
Qcache_hits: 缓存命中次数
Qcache_inserts: 缓存写入次数
Qcache_lowmen_prunes: 因内存不足删除缓存次数
Qcache_not_cached: 查询未被缓存次数,例如查询结果超出缓存块大小,查询中包含可变函数等
Qcache_queries_in_cache: 当前缓存中缓存的SQL数量
Qcache_total_blocks: 缓存总block数
减少碎片策略
- 选择合适的block大小
- 使用 FLUSH QUERY CACHE 命令整理碎片.这个命令在整理缓存期间,会导致其他连接无法使用查询缓存
PS: 清空缓存的命令式 RESET QUERY CACHE
InnoDB与查询缓存
Innodb会对每个表设置一个事务计数器,里面存储当前最大的事务ID.当一个事务提交时,InnoDB会使用MVCC中系统事务ID最大的事务ID跟新当前表的计数器.
只有比这个最大ID大的事务能使用查询缓存,其他比这个ID小的事务则不能使用查询缓存.
另外,在InnoDB中,所有有加锁操作的事务都不使用任何查询缓存
查询必须是完全相同的(逐字节相同)才能够被认为是相同的。另外,同样的查询字符串由于其它原因可能认为是不同的。使用不同的数据库、不同的协议版本或者不同 默认字符集的查询被认为是不同的查询并且分别进行缓存。
https://blog.csdn.net/qzqanzc/article/details/80418125?utm_source=copy
mysql 缓存机制的更多相关文章
- MYSQL内存--------启动mysql缓存机制,实现命中率100% 转
虽然这个标题夸张得过了头,但此文很完整,值得学习.转自 http://www.yy520.net/read.php?278 myql优化,启动MySQL缓存机制,实现命中率100% 配置你的mysql ...
- MySQL缓存机制详解(一)
本文章拿来学习用||参考资料:http://www.2cto.com/database/201308/236361.html 对MySql查询缓存及SQL Server过程缓存的理解及总结 一.M ...
- MySQL缓存机制
对MySql查询缓存及SQL Server过程缓存的理解及总结 一.MySql的Query Cache 1.Query Cache MySQL Query Cache是用来缓存我们所执行的SELE ...
- 《MySQL面试小抄》查询缓存机制终面
<MySQL面试小抄>查询缓存机制终面 我是肥哥,一名不专业的面试官! 我是囧囧,一名积极找工作的小菜鸟! 囧囧表示:小白面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点 ...
- MySQL 查询缓存机制(MySQL数据库调优)
查询缓存机制:缓存的是查询语句的整个查询结果,是一个完整的select语句的缓存结果 哪些查询可能不会被缓存 :查询中包含UDF.存储函数.用户自定义变量.临时表.mysql库中系统表.或者包含列级别 ...
- mysql中innodb引擎的mvcc机制和BufferPool缓存机制
一.MVCC (1)mvcc主要undo日志版本链和read-view一致性视图来保证多事务的并发控制,mvcc是innodb的一种特殊机制,他保证了事务四大特性之一的隔离性(原子性,一致性,隔离性) ...
- MyCat源码分析系列之——BufferPool与缓存机制
更多MyCat源码分析,请戳MyCat源码分析系列 BufferPool MyCat的缓冲区采用的是java.nio.ByteBuffer,由BufferPool类统一管理,相关的设置在SystemC ...
- mysql缓存、存储引擎
一. mysql查询缓存 查询缓存不是mysql的子系统,却是查询优化和执行子系统不可缺少的组成部分.它不仅可以缓存查询结果,还可以缓存查询结果本身.如果某个查询的结果就在缓存里, 系 ...
- 理解 QEMU/KVM 和 Ceph(1):QEMU-KVM 和 Ceph RBD 的 缓存机制总结
本系列文章会总结 QEMU/KVM 和 Ceph 之间的整合: (1)QEMU-KVM 和 Ceph RBD 的 缓存机制总结 (2)QEMU 的 RBD 块驱动(block driver) (3)存 ...
随机推荐
- Sub-Processes and Call Activities
https://www.activiti.org/userguide/#bpmnCallActivity http://www.flowable.org/docs/userguide/index.ht ...
- MySql绿色版安装配置
首先从官网下载MySQL的安装文件:http://dev.mysql.com/downloads/file.php?id=456318(直接选择No thanks, just start my dow ...
- mysql 表注释的添加、查看 、修改
表创建时添加注释: create table user( id int not null default 0 comment '用户id', account varchar(20) not nul ...
- Bootstrap 引入文件顺序及IE兼容性js
<!DOCTYPE html><html lang="zh-cn"><head> <meta charset="utf-8&qu ...
- Angular @的作用
<!DOCTYPE html><html lang="zh-cn" ng-app="myApp"><head> <me ...
- python 字符串内置方法实例
一.字符串方法总结: 1.查找: find(rfind).index(rindex).count 2.变换: capitalize.expandtabs.swapcase.title.lower.up ...
- BZOJ2124 等差子序列(树状数组+哈希)
容易想到一种暴力的做法:枚举中间的位置,设该位置权值为x,如果其两边存在权值关于x对称即合法. 问题是如何快速寻找这个东西是否存在.考虑仅将该位置左边出现的权值标1.那么若在值域上若关于x对称的两权值 ...
- BZOJ5312 冒险(势能线段树)
BZOJ题目传送门 表示蒟蒻并不能一眼看出来这是个势能线段树. 不过仔细想想也并非难以理解,感性理解一下,在一个区间里又与又或,那么本来不相同的位也会渐渐相同,线段树每个叶子节点最多修改\(\log ...
- Leetcode 217.存在重复元素 By Python
给定一个整数数组,判断是否存在重复元素. 如果任何值在数组中出现至少两次,函数返回 true.如果数组中每个元素都不相同,则返回 false. 示例 1: 输入: [1,2,3,1] 输出: true ...
- [luogu4551][POJ3764]最长异或路径
题目描述 给定一棵n个点的带权树,结点下标从1开始到N.寻找树中找两个结点,求最长的异或路径. 异或路径指的是指两个结点之间唯一路径上的所有边权的异或. 分析 处理出各个节点到根节点的异或距离,然后我 ...