java-集合学习-底层实现
集合分为两大类:
Collection集合: 单个存储
Map集合: 按<键,值>对的形式存储, <员工姓名,工资>
Collection类关系图
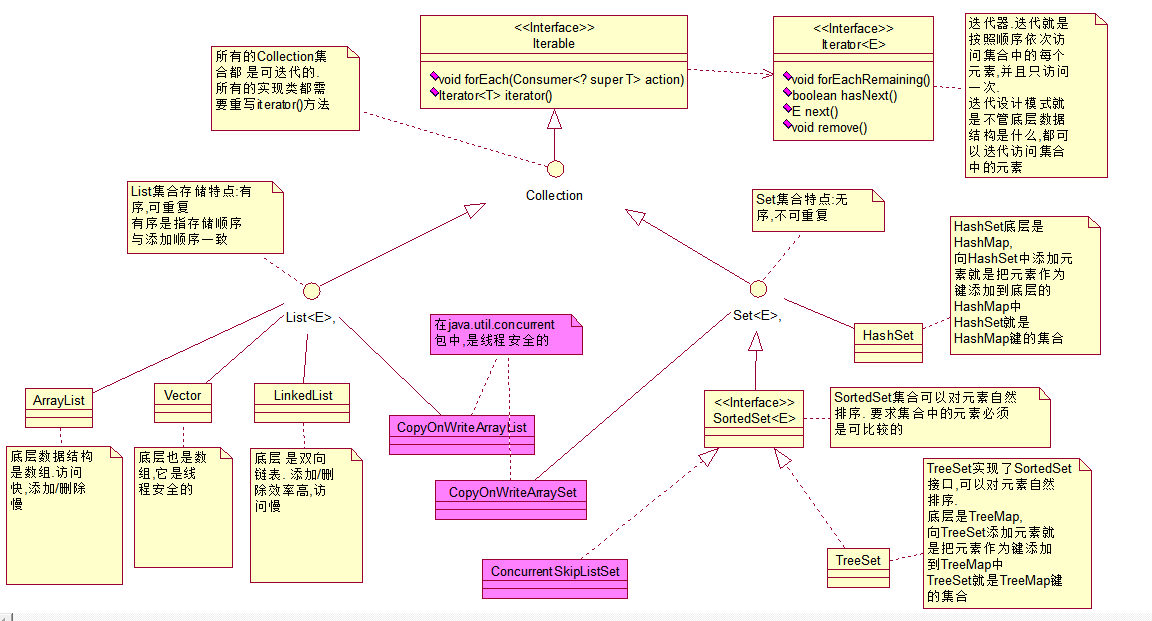
Collection常见方法
|
|
|
|
|
addAll |
|
|
clear |
|
|
|
|
|
isEmpty |
|
iterator |
|
|
|
|
|
|
removeAll |
|
|
size |
|
Object |
toArray |
|
|
toArray |
-------------------------------------------------------------
List接口继承了Collection接口. Collection的所有操作List都可以继承到
List存储特点:
有序,可重复
List集合为每个元素指定一个索引值,增加了针对索引值的操作
add(index, o) remove(index) get(index) set(index, o)
sort( Comparator )
》》》》》》》》》》》》》》
ArrayList与Vector
1) 底层是数组, 访问快,添加删除慢
2) ArrayList不是线程安全的,Vector是线程安全的
3) ArrayList初始化容量: 10 , Vector初始化容量: 10
4) 扩容ArrayList按1.5倍, Vector按2倍大小扩容
---------------------------------------------------------------------------
Set集合
无序, 存储顺序可能与添加顺序不一样
不能存储重复的数据
---------------------------------------------------------------
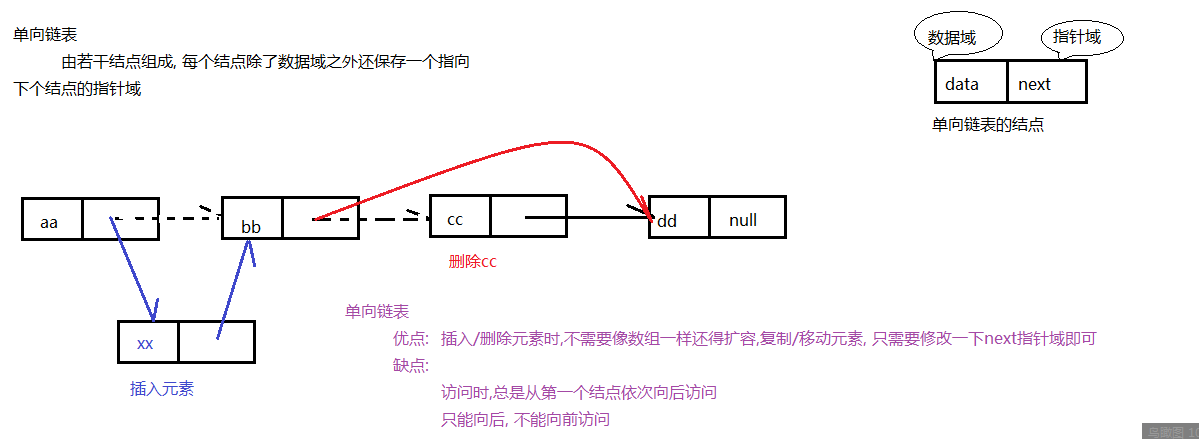
单向链表
由若干个节点组成,每个节点除了数据域之外还保存一个指向下个节点的指针域。
优点:
插入/删除元素时,不需要像数组一样还得扩容、复制/移动元素,只需要修改一下next指针域即可。
缺点:
访问时,总是从第一个结点依次向后访问,只能向后访问,不能向前访问。
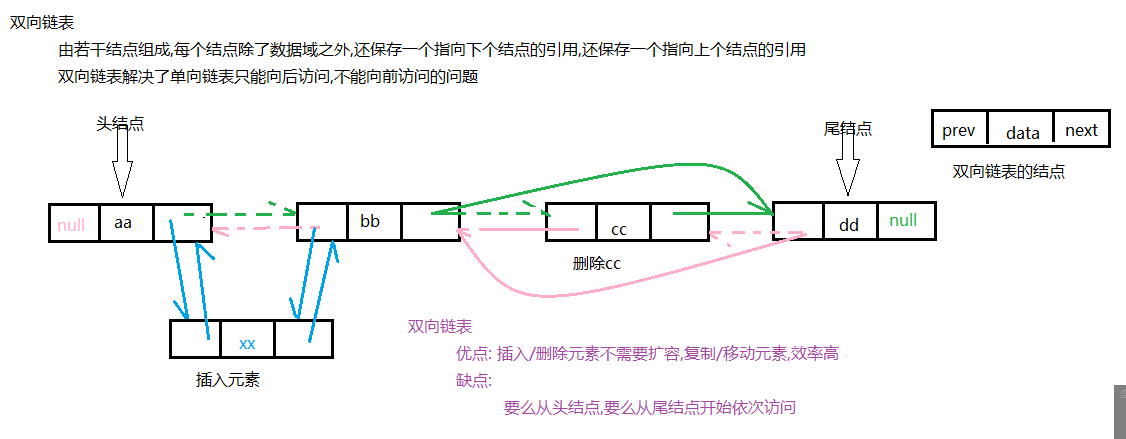
双向链表
LinkedList底层采用双向链表
使用LinkedList模拟栈结构。栈结构特点:后进先出。
Push()
Pop()
使用LinkedList,模拟队列。队列:先进先出。
Offer()
Poll();
单项链表示例图:
双向链表示例图:
--------------------------------------------------------------
HashSet
* 1)底层是HashMap
* 2)向HashSet添加元素就是把该元素作为键添加到底层的HashMap中
* 3) HasetSet就是HashMap键的集合
* 4) 存储在HashSet中的元素, 需要重写equals()/hashCode()方法
2 TreeSet
TreeSet实现了SortedSet接口,可以对集合中的元素自然排序, 要求元素必须是可比较的
1) 在TreeSet构造方法中指定Comparator比较器
2) 如果没有Comparator比较器,元素的类实现Comparable接口
* TreeSet
* 1)TreeSet集合可以对元素排序, 要求元素必须是可比较的
* (1)在构造方法中指定Comparator比较器
* (2)如果没有Comparator,元素的类需要实现Comparable接口
* TreeSet是先选择Comparator,
在没有Comparator的情况下,再找Comaprable
* 2)TreeSet底层是TreeMap
* 3)向TreeSet添加元素就是把元素作为键添加到底层的TreeMap中
* 4)TreeSet就是TreeMap键的集合
TreeSet
可以对元素排序,要求元素必须是可以比较的。
TreeSet是先选择Comparator,没有Comparator再选择
Comparable。
TreeSet的底层是TreeMap
TreeSet如果比较两个元素相同,只能存在一个。
要非常注意,比较方法。TreeSet集合根据Comparator/Comparable的比较结果是否为0,来判断元素是否为同一个元素的。
==================================
3.5 Collection小结
Collection单个存储
基本操作:
add(o), remove(o), contains(o), size(),
iterator() hasNext(), next(), remove()
----List
特点:
有序,存储顺序与添加顺序一样
可重复,可以存储重复的数据
为每个元素指定一个索引值
新增的操作:
add(inex, o ), remove(index), get(index), set(index, newValue)
sort(Comparator)
--------ArrayList
底层是数组, 访问快,添加删除慢
初始化容量:10
扩容: 1.5 倍
--------Vector
底层是数组, 它是线程安全的, ArrayList不是线程安全的
初始化容量: 10
扩容: 2倍
--------LinkedList
底层是双向链表, 添加/删除效率高,访问慢
新增的操作:
addFirst(o) / addLast(o)removeFirst()/removeLast()
getFirst()/getLast()
push(o)/pop()
offer(o)/poll()
*******应用场景***************************************************
存储可以重复的数据选择List集合
如果以查询访问为主,选择ArrayList
如果频繁的进行添加/删除操作,选LinkedList
如果开发多线程程序,选择juc包中的CopyOnWriterArrayList
-------注意------------------------------------------------------------------------------------------------
List集合,在contains(o), remove(o)操作时,需要比较元素,调用equals()方法
如果在List存储自定义类型数据,需要重写equals()/hashCode()
----Set
特点:
无序:存储顺序与添加顺序可能不一样
不可重复,存储的数据不允许重复
--------HashSet
底层是HashMap
向HashSet添加元素就是把该元素作为键添加到底层的HashMap中
HashSet就是HashMap键的集合
--------TreeSet
TreeSet实现了SortedSet接口,可以对元素自然排序,要求元素必须 是可比较的
(1)在构造方法中指定Comaparator比较器
(2)没有Comaprator,需要让元素的类实现Comaparable接口
TreeSet是先选择Comparator,在没有Comparator的情况下,再选择Comparable
TreeSet底层是TreeMap
向TreeSet添加元素就是把该元素作为键添加到底层的TreeMap中
TreeSet就是TreeMap键的集合
******应用场景*******************************************************
如果存储不重复的元素使用Set集合
如果不需要排序就使用HashSet
如果需要排序就选择TreeSet
-----注意--------------------------------------------------------------------------------------------------
HashSet中的元素需要重写equals()/hashCode()方法
TreeSet集合中判断是否相同的元素, 根据Comparator/Comparable比较结果是否为0来判断
===========================================
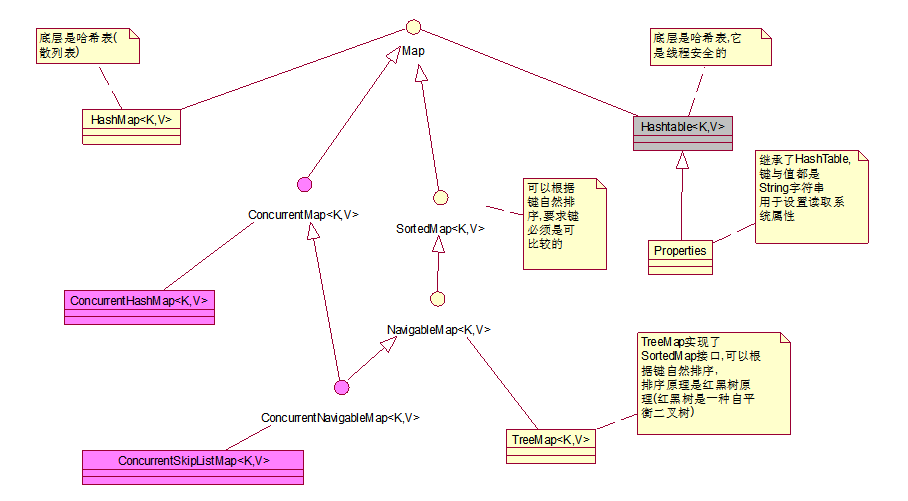
Map是以键值对存储数据
如<员工姓名,工资>, <学生姓名,成绩>…
-----------------------------------------------------
|
|
clear |
|
|
containsKey |
|
|
containsValue |
|
entrySet |
|
|
|
|
|
|
forEach |
|
|
isEmpty |
|
keySet |
|
|
|
putAll |
|
|
|
|
|
|
|
|
size |
|
values |
HashMap工作原理图:
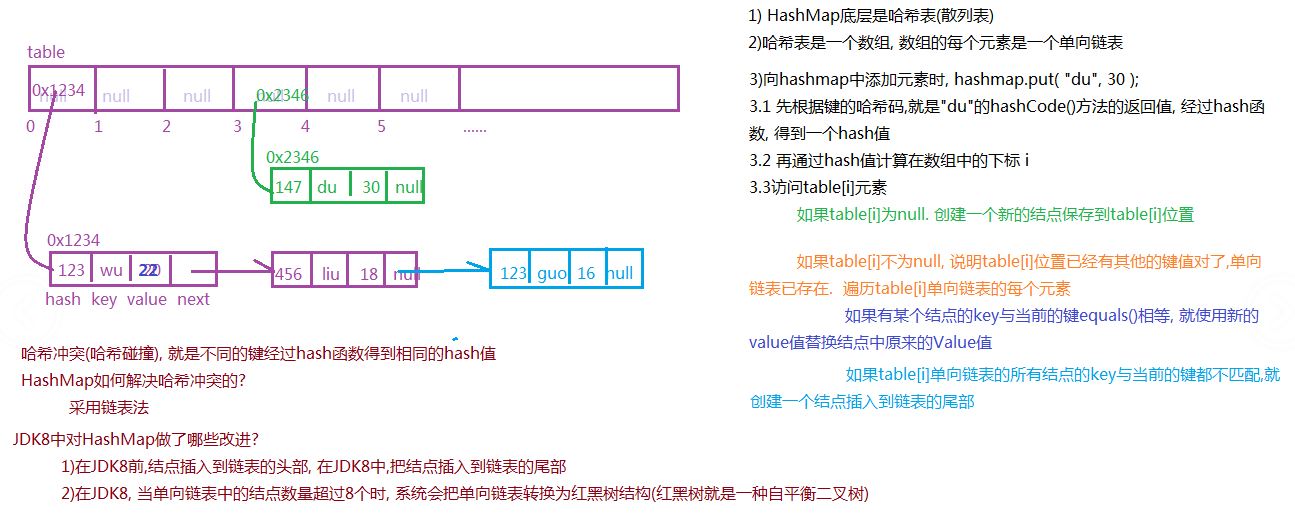
获取元素图:

HashMap
* 1)底层是哈希表,哈希表是一个数组,数组的每个元素是一个单向链表,数组元素实际存储的是单向链表第一个结点的引用
* 2)默认初始化容量: 16
* 3)默认加载因子: 0.75, 当键值对的数量大于 容量 * 加载因子时, 数组扩容
* 4)扩容:2倍
* 5)HashMap的键与值都可以为null
* 6)在定义Hashmap时,可以指定初始化容量,系统会自动调整为2的幂次方,即把17~31之间的数调整为32, 把33~63之间的数调整为64
* 为了能够快速计算数组的下标
-------------------------------
HashTable
* 1)底层是哈希表, 哈希表就是一个数组,数组的元素是一个单向链表,数组元素实际存储的是单向链表第一个结点的引用
* 2)默认初始化容量: 11
* 3)加载因子: 0.75
* 4)扩容:2倍 + 1
* 5)HashTable的键与值都不能为null
* 6)在定义时可以指定初始化容量, 不会调整大小
* 7) HashTable是线程安全的,
HashMap不是线程安全的
--------------------------------------------------------------
Properties
Properties继承了HashTable
键与值都是String字符串
经常用于设置/读取系统属性值
常用 方法:
setProperty(属性名, 属性值)
getProperty(属性名)
-----------------------------------------------------
TreeMap
* TreeMap实现了SortedMap接口,可以根据键自然排序, 要求键必须是可比较的
* 1)在构造方法中指定Comparator比较器
* 2)没有Comparator时,键要实现Comparable接口
* 对于TreeMap来说,先判断是否有Comparator,有的话就按Comparator比较; 如果没有Comaparator,系统要查看键是否实现了Comparable接口
* 对于程序员来说,一般情况下通过Comparable定义一个默认的比较规则(绝大多数使用的排序规则), 通过Comparator可以定义很多不同的排序规则
TreeMap是根据二叉树原理实现排序的
二叉树原理图示例:
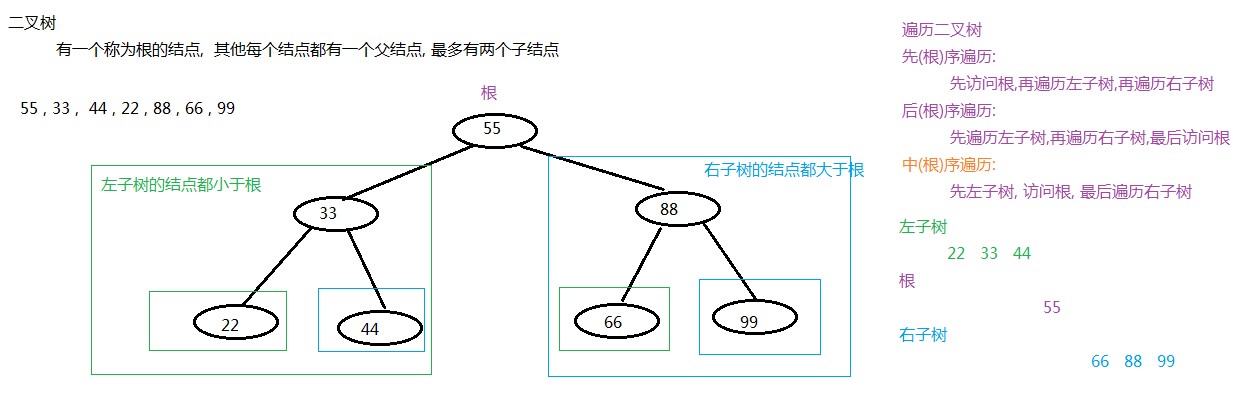
-----------------------------------------------------------------------------------------
Map小结
Map是按<键,值>对的形式存储数据
基本操作:
put(k,v) remove(k) remove(k,v)
containsKey(k) containsValue(v) get(k) size()
keySet() values() entrySet()
replace( k , v)
---- HashMap
底层是哈希表(散列表), 哈希表是一个数组,数组的每个元素是一个单向链表,数组元素其实存储的是单向链表的第一个结点的引用
初始化容量: 16
扩容: 2倍
键与值可以为null
指定初始化容量,系统会调整为2的幂次方
----HashTable
底层是哈希表(散列表), 它是线程安全的,HashMap不是线程安全的
初始化容量: 11
扩容: 2倍+1
键与值 不 可以为null
指定初始化容量,系统不调整
-------- Properties
继承了HashTable,
键与值都是String字符串
经常用来设置/读取系统属性
一般把属性保存在配置文件中, 可以通过Properties读取
----TreeMap
实现了SortedMap接口,可以根据键自然排序, 要求键必须是可比较的
1) 在构造方法中指定Comparator比较器
2) 没有Comparator时, 键要实现Comparable接口
对于 TreeMap来说,先选择Comparator,
对于 开发人员来说,一般让键实现Comparable接口定义一个默认的比较规则,通过Comparator可以定义其他不同的比较规则
TreeMap的键是根据红黑树排序的,红黑树是一种自平衡二叉树
*****应用场景**********************************************************
如果不需要根据键排序选择HashMap
如果需要键排序,选择TreeMap
开发多线程程序,一般不使用HashTable, 使用juc包中的ConcurrentHashMap,如果要根据键排序就使用juc包中的ConcurrentSkipListMap. ConcurrentHashMap采用分段锁协议,默认分为16段锁,并发效率高.
--------注意------------------------------------------------------------------------------------
HashMap,HashTable的键需要重写equals()/hashCode()
TreeMap的键是根据Comparator/Comparable的比较结果是否为0来判断是否相同的键
java-集合学习-底层实现的更多相关文章
- 转:深入Java集合学习系列:HashSet的实现原理
0.参考文献 深入Java集合学习系列:HashSet的实现原理 1.HashSet概述: HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持.它不保证set 的迭代顺序:特 ...
- Java集合学习(9):集合对比
一.HashMap与HashTable的区别 HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以随机应变使用多种思路解决问题.Hash ...
- 2019/3/4 java集合学习(二)
java集合学习(二) 在学完ArrayList 和 LinkedList之后,基本已经掌握了最基本的java常用数据结构,但是为了提高程序的效率,还有很多种特点各异的数据结构等着我们去运用,类如可以 ...
- 2019/3/2周末 java集合学习(一)
Java集合学习(一) ArraysList ArraysList集合就像C++中的vector容器,它可以不考虑其容器的长度,就像一个大染缸一 样,无穷无尽的丢进去也没问题.Java的数据结构和C有 ...
- java集合学习(2):Map和HashMap
Map接口 java.util 中的集合类包含 Java 中某些最常用的类.最常用的集合类是 List 和 Map. Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含 ...
- java集合学习一
首先看一下java集合的关系图 1.1从全面了解Java的集合关系图.常见集合 list set map等其中我们最常用的 list map 结合.几天说一下常见的map.map在我工作的两年里 ...
- Java 集合学习--HashMap
一.HashMap 定义 HashMap 是一个基于散列表(哈希表)实现的键值对集合,每个元素都是key-value对,jdk1.8后,底层数据结构涉及到了数组.链表以及红黑树.目的进一步的优化Has ...
- 深入java集合学习1-集合框架浅析
前言 集合是一种数据结构,在编程中是非常重要的.好的程序就是好的数据结构+好的算法.java中为我们实现了曾经在大学学过的数据结构与算法中提到的一些数据结构.如顺序表,链表,栈和堆等.Java 集合框 ...
- Java集合学习总结
java集合 collection public interface Collection<E> extends Iterable<E> List public interfa ...
- java集合学习(1):集合框架
集合 Collection(有时候也叫container)是一个简单的对象, Java集合工具包位于Java.util包下,Java集合主要可以划分为4个部分:List列表.Set集合.Map映射.工 ...
随机推荐
- Windows安装多个版本JDK如何切换
本人电脑同时安装了jdk1.7和1.8,以下时切换jdk版本的方式: 1.修改环境变量: 2.修改注册表: 打开HKEY_LOCAL_MACHINE\SOFTWARE\JavaSoft 分别修改Jav ...
- SpringBoot搭建聚合项目-实战记录01
工具:Spring Tool Suite 4 项目搭建 1.首先建立工作集 : Configure Working Sets -> New.. ->设置名称(如project) -> ...
- 在学习python的Django\Flask\Tornado前你需要知道的,what is web?
我们都在讲web开发web开发,那到底什么是web呢? 如果你正在学习python三大主流web框架,那这些你必须要知道了 软件开发架构: C/S架构:Client/Server 客户端与服务端 ...
- Golang结构体struct的使用(结构体嵌套, 匿名结构体等)
转自: https://studygolang.com/articles/11313 golang中是没有class的,但是有一个结构体struct,有点类似,他没有像java,c++中继承的概念,但 ...
- RDP爆破方式攻击防控思路梳理
- 啃掉Hadoop系列笔记(03)-Hadoop运行模式之本地模式
Hadoop的本地模式为Hadoop的默认模式,不需要启用单独进程,直接可以运行,测试和开发时使用. 在<啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建>中若环境搭建成功,则直 ...
- SQL Server优化技巧——如何避免查询条件OR引起的性能问题
原文:SQL Server优化技巧--如何避免查询条件OR引起的性能问题 之前写过一篇博客"SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析",里面介绍了OR可能会引起 ...
- 什么是NameNode和DataNode?他们是如何协同工作的?
[学习笔记] 什么是NameNode和DataNode?他们是如何协同工作的? 马克-to-win @ 马克java社区:一个HDFS集群包含一个NameNode和若干的DataNode(start- ...
- 减2或减3(很搞的贪心)2019牛客国庆集训派对day6
题意:https://ac.nowcoder.com/acm/contest/1111/D 问你先减二x次的情况下,最少减几次3. 思路: %3不为0的要先减2,然后%3为0的要先减大的(比如9 3 ...
- django 模块创建 同步数据表 使用方法
1 配置数据库 100行左右 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', # 'NAME': 'student ...