Hadoop_16_MapRduce_MapTask并行度(切片)的决定机制
MapTask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度那么,mapTask并行实例是否越多
越好呢?其并行度又是如何决定呢?Mapper数量由输入文件的数目、大小及配置参数决定;
MapReduce将作业的整个运行过程分为两个阶段:Map阶段Reduce阶段。
Map阶段由一定数量的Map Task实例组成,例如:
- 输入数据格式解析:InputFormat
- 输入数据处理:Mapper
- 本地规约:Combiner(相当于local reducer,可选)
- 数据分组:Partitioner
Reduce阶段由一定数量的Reduce Task实例组成,例如:
- 数据远程拷贝
- 数据按照key排序
- 数据处理:Reducer
- 数据输出格式:OutputFormat
1.MapReduce的Map阶段:
1.1.从HDFS读取数据:
一个job的Map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据
划分成逻辑上的多个split),然后每一个split分配一个MapTask并行实例处理,即就是到底启动多少个MapTask实例就意味着将
数据切成多少份(一个切片对应一个MapTask实例)
切片逻辑及形成的切片规划List描述文件,由 FileInputFormat 实现类的getSplits()方法完成:流程如下:
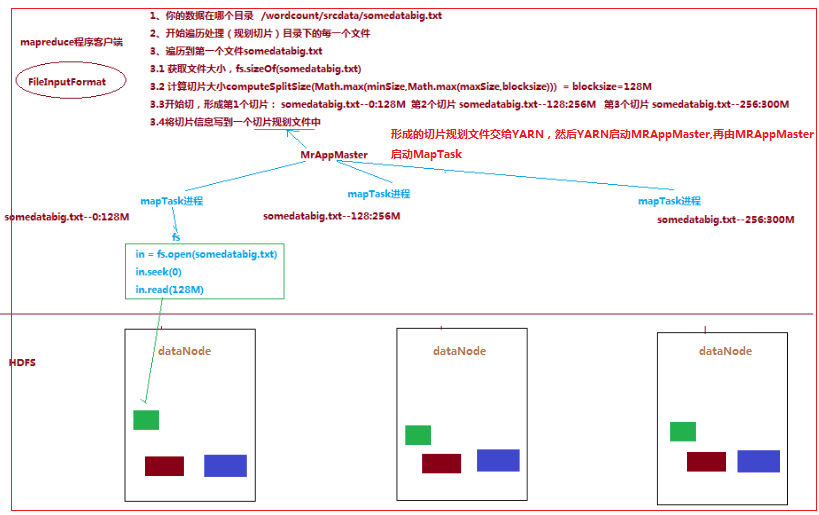
1.1.1.FileInputFormat中默认的切片机制:
a) 简单地按照文件的内容长度进行切片
b) 切片大小,默认等于block大小
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
file1.txt 320M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10M
1.1.2.FileInputFormat中切片大小的参数配置:
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize));
切片主要由这几个值来运算决定
|
minsize:默认值:1 配置参数: mapreduce.input.fileinputformat.split.minsize |
|
maxsize:默认值:Long.MAXValue 配置参数:mapreduce.input.fileinputformat.split.maxsize |
|
blocksize |
因此,默认情况下,切片大小=blocksize
maxsize(切片最大值):
参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minsize (切片最小值):
参数调的比blockSize大,则可以让切片变得比blocksize还大
1.5 ReduceTask并行度的决定
ReduceTask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量
的决定是可以直接手动设置:
//默认值是1,手动设置为4
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask
尽量不要运行太多的reducetask。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小
这个对于小集群而言,尤其重要。
Hadoop_16_MapRduce_MapTask并行度(切片)的决定机制的更多相关文章
- iOS通过切片仿断点机制上传文件
项目开发中,有时候我们需要将本地的文件上传到服务器,简单的几张图片还好,但是针对iPhone里面的视频文件进行上传,为了用户体验,我们有必要实现断点上传.其实也不是真的断点,这里我们只是模仿断点机制. ...
- MapReduce-TextInputFormat 切片机制
MapReduce 默认使用 TextInputFormat 进行切片,其机制如下 (1)简单地按照文件的内容长度进行切片 (2)切片大小,默认等于Block大小,可单独设置 (3)切片时不考虑数据集 ...
- job任务执行流程与分区机制
job任务执行流程 1.run job阶段 ①收集整个job的环境信息(比如通过conf设定的参数,还有mapperClass,reducerClass,以及输出kv类型) ...
- [翻译] NumSharp的数组切片功能 [:]
原文地址:https://medium.com/scisharp/slicing-in-numsharp-e56c46826630 翻译初稿(英文水平有限,请多包涵): 由于Numsharp新推出了数 ...
- go语言教程之浅谈数组和切片的异同
Hello ,各位小伙伴大家好,我是小栈君,上次分享我们讲到了Go语言关于项目工程结构的管理,本期的分享我们来讲解一下关于go语言的数组和切片的概念.用法和区别. 在go语言的程序开发过程中,我们避免 ...
- NumSharp的数组切片功能
NumSharp的数组切片功能 原文地址:https://medium.com/scisharp/slicing-in-numsharp-e56c46826630 翻译初稿(英文水平有限,请多包涵): ...
- 手把手golang教程【二】——数组与切片
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是golang专题的第五篇,这一篇我们将会了解golang中的数组和切片的使用. 数组与切片 golang当中数组和C++中的定义类似, ...
- Go切片全解析
Go切片全解析 目录结构: 数组 切片 底层结构 创建 普通声明 make方式 截取 边界问题 追加 拓展表达式 扩容机制 切片传递的坑 切片的拷贝 浅拷贝 深拷贝 数组 var n [4]int f ...
- 大数据入门第七天——MapReduce详解(二)切片源码浅析与自定义patition
一.mapTask并行度的决定机制 1.概述 一个job的map阶段并行度由客户端在提交job时决定 而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小, ...
随机推荐
- windows10专业版激活方法
1.首先在桌面左下角的“cortana”搜索框中输入“CMD”,待出现“命令提示符”工具时,右击选择“以管理员身份”运行. 2.此时将“以管理员身份”打开“MSDOS”窗口,在此界面中,依次输出以下命 ...
- 【DSP开发技术】影响高性能DSP功耗的因素及其优化方法
影响高性能DSP功耗的因素及其优化方法 德州仪器DSP技术应用工程师 冯华亮 摘要 本文讨论影响高性能DSP功耗的因素,介绍一些DSP功耗的优化方法. 随着嵌入式应用需求的不断提高,DSP的速度也不断 ...
- pycharm2017注册码
BIG3CLIK6F-eyJsaWNlbnNlSWQiOiJCSUczQ0xJSzZGIiwibGljZW5zZWVOYW1lIjoibGFuIHl1IiwiYXNzaWduZWVOYW1lIjoiI ...
- C语言课程设计
目录 实现目的 游戏玩法介绍 实现流程与作品架构 任务列表及贡献度 总结感想 作品源码与仓库地址(附页) 资料引用与出处(附页) 实现目的 2048,作为一款极其经典的游戏,从发行到现在,已经有了极多 ...
- [转帖]「知乎知识库」— 5G
「知乎知识库」— 5G 甜草莓 https://zhuanlan.zhihu.com/p/55998832 通信 话题的优秀回答者 已关注 881 人赞同了该文章 谢 知识库 邀请~本文章是几个答 ...
- 使用pycharm开发web——django2.1.5(三)创建models并进入交互界面shell做一些简单操作
这里model可以认为是数据对象本身 相当于在写java代码时候model目录下创建的实体类,models.py 中可以包含多个实体类,感觉这个操作挺骚的 下面是polls app里面的models, ...
- JS数据拷贝
JS的拷贝可分为浅拷贝和深拷贝: 浅拷贝:如果数组元素是基本类型,就会拷贝一份,互不影响,而如果是对象或者数组,就会只拷贝对象和数组的引用,这样我们无论在新旧数组进行了修改,两者都会发生变化. 深拷贝 ...
- hdu 1024 最大m段不相交线段和
题目传送门//res tp hdu 数据范围1e6,若是开二维会爆 考虑用滚动数组优化 #include<iostream> #include<cstdio> #include ...
- easyui-combobox多选时的小问题
easyui-combobox可支持多选,仅需将multiple值设为true即可 $('#combobox').combobox({ url:url, multiple:true, separato ...
- Educational Codeforces Round 71 (Rated for Div. 2) Solution
A. There Are Two Types Of Burgers 题意: 给一些面包,鸡肉,牛肉,你可以做成鸡肉汉堡或者牛肉汉堡并卖掉 一个鸡肉汉堡需要两个面包和一个鸡肉,牛肉汉堡需要两个面包和一个 ...