awk 常用选项及数组的用法和模拟生产环境数据统计
awk 常用选项总结

在 awk 中使用外部的环境变量 (-v)
awk -v num2="$num1" -v var1="$var" 'BEGIN{print num2,var1}'

-f 选项 文件中读取表达式
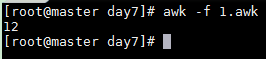
1.awk
BEGIN{
str="I hava a tream"
location=index(str,"ea")
print location
}
awk -f 1.awk
2.wak
BEGIN{
str="Transaction 243 Start,Event ID:9002"
count=sub(/[0-9]+/,"$",str)
print str
}

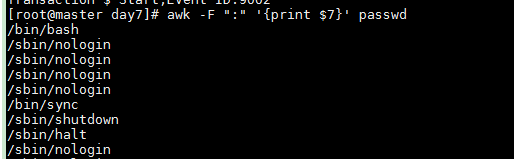
-F 指定分隔符
awk -F ":" '{print $7}' passwd
显示版本号
awk -V

awk中数组的用法及模拟生产环境数据统计
shell中的数组的用法:
- shell数组中的下标是从0开始的
array=("Allen" "Mike" "Messi" "Jerry" "Hanmeimei" "Wang")
打印元素: echo ${array[2]}
打印元素个数: echo ${#array[@]}
打印某个元素长度: echo ${#array[3]}
给元素赋值: array[3]=ui;
删除元素: unset array[2];unset array # 删除数组
分片访问: echo ${array[@]:1:3}
元素内容替换: ${array[@]/e/E} 只替换第一个e;${array[@]//e/E} 替换所有的e
数组的遍历:
for a in ${array[@]}
do
echo $a
done
awk中数组的用法:
- 在awk中,使用数组时,不仅可以使用1.2..n作为数组小标,也可以使用字符串作为数组下标
典型常用例子:
统计主机上所有的tcp链接状态数,按照每个tcp状态分类
netstat -an | grep tcp | awk '{arr[$6]++}END{for (i in arr) print i,arr[i]}'

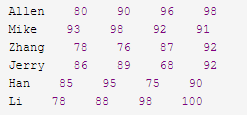
计算横向数据综合,计算纵向数据总和
statics.awk
BEGIN{
printf "%-30s%-30s%-30s%-30s%-30s%-30s\n","Name","Yuwen","Math","English","Physical","total"
}
{
total=$2+$3+$4+$5
yuwen_sum+=$2
math_sum+=$3
english_sum+=$4
physical_sum+=$5
printf "%-30s%-30d%-30d%-30d%-30d%-30d\n",$1,$2,$3,$4,$5,total
}
END{
printf "%-30s%-30d%-30d%-30d%-30d\n","every_total",yuwen_sum,math_sum,english_sum,physical_sum
}
awk -f statics.awk student.txt
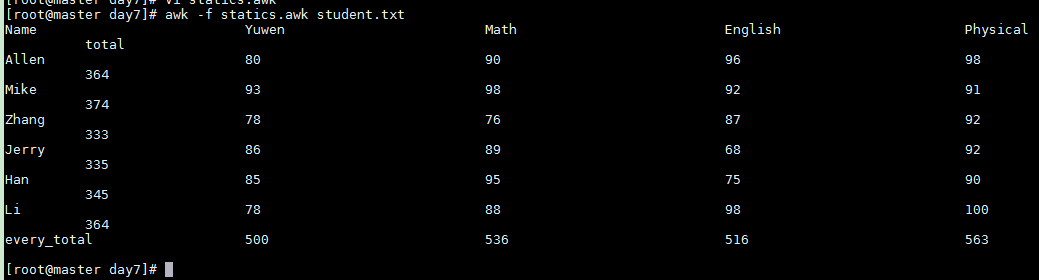
计算字符串的长度:
str="test string"
echo ${#str}

修改数组元素
array=("Allen" "Mike" "Messi" "Jerry" "Hanmeimei" "Wang")
array[1]="Jerry"
echo ${array[@]}

删除第3个元素
echo ${array[@]}
unset array[2]
echo ${array[@]}

在数组中删除下标为1的元素,即Mike被删除,再次删除下标为1的元素,发现数组不变,说明数组虽然删除了元素,下标还是不变保存在内存中
array=("Allen" "Mike" "Messi" "Jerry" "Hanmeimei" "Wang")
unset array[1]
echo ${array[*]}

分片访问,数组为1的开始遍历3个元素
array=("Allen" "Mike" "Messi" "Jerry" "Hanmeimei" "Wang")
echo ${array[@]:1:3}

1到最后
echo ${array[@]:1}

替换1个,替换所有
echo ${array[@]}
echo ${array[@]/e/E}
echo ${array[@]//e/E}

遍历数组
for a in ${array[@]};do echo $a;done
计算横向和、纵向和

awk -f stu.awk student.txt

模拟生产环境数据脚本
db.log.20190608
2019-06-08 10:31:40 15459 Batches: user Jerry insert 5504 records into datebase:product table:detail, insert 5253 records successfully,failed 251 records
2019-06-08 10:31:40 15460 Batches: user Tracy insert 25114 records into datebase:product table:detail, insert 13340 records successfully,failed 11774 records
2019-06-08 10:31:40 15461 Batches: user Hanmeimei insert 13840 records into datebase:product table:detail, insert 5108 records successfully,failed 8732 records
2019-06-08 10:31:40 15462 Batches: user Lilei insert 32691 records into datebase:product table:detail, insert 5780 records successfully,failed 26911 records
2019-06-08 10:31:40 15463 Batches: user Allen insert 25902 records into datebase:product table:detail, insert 14027 records successfully,failed 11875 records
1 统计每个人分别插入了多少条record进数据库
exam1.awk
BEGIN{
printf "%-20s%-20s\n","User","Total records"
}
{
USER[$6]+=$8
}
END{
for(u in USER)
printf "%-20s%-20d\n",u,USER[u]
}
awk -f exam1.awk db.log.20190608

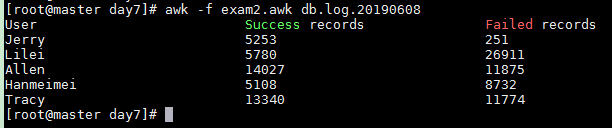
2 统计每个人分别插入成功了多少record,失败了多少record
exam2.awk
BEGIN{
printf "%-30s%-30s%-30s\n","User","Success records","Failed records"
}
{
SUCCESS[$6]+=$14
FAILED[$6]+=$17
}
END{
for(u in SUCCESS)
printf "%-30s%-30d%-30d\n",u,SUCCESS[u],FAILED[u]
}
awk -f exam2.awk db.log.20190608
3 将例子1和例子2结合起来,一起输出,输出每个人分别插入多少条数据,多少成功,多少失败,并且要格式化输出,加上标题
exam3.awk
BEGIN{
printf "%-30s%-30s%-30s%-30s\n","Name","total records","success records","failed records"
}
{
TOTAL_RECORDS[$6]+=$8
SUCCESS[$6]+=$14
FAILED[$6]+=$17
}
END{
for(u in TOTAL_RECORDS)
printf "%-30s%-30d%-30d%-30d\n",u,TOTAL_RECORDS[u],SUCCESS[u],FAILED[u]
}
awk -f exam3.awk db.log.20190608

4 在例子3的基础上,加上结尾,统计全部插入记录数,成功记录数,失败记录数
exam4_b.awk
BEGIN{
printf "%-30s%-30s%-30s%-30s\n","Name","total records","success records","failed records"
}
{
TOTAL_RECORDS[$6]+=$8
SUCCESS[$6]+=$14
FAILED[$6]+=$17
}
END{
for(u in TOTAL_RECORDS)
{
# 在统计出的结果数组中进行累加
records_sum+=TOTAL_RECORDS[u]
success_sum+=SUCCESS[u]
failed_sum+=FAILED[u]
printf "%-30s%-30d%-30d%-30d\n",u,TOTAL_RECORDS[u],SUCCESS[u],FAILED[u]
}
printf "%-30s%-30d%-30d%-30d\n","",records_sum,success_sum,failed_sum
}
awk -f exam4_b.awk db.log.20190608

方法2:
exam4.awk
BEGIN{
printf "%-30s%-30s%-30s%-30s\n","Name","total records","success records","failed records"
}
{
RECORDS[$6]+=$8
SUCCESS[$6]+=$14
FAILED[$6]+=$17
# 在原始数据中进行汇总计算
records_sum+=$8
success_sum+=$14
failed_sum+=$17
}
END{
for(u in RECORDS)
printf "%-30s%-30d%-30d%-30d\n",u,RECORDS[u],SUCCESS[u],FAILED[u]
printf "%-30s%-30d%-30d%-30d\n","total",records_sum,success_sum,failed_sum
}

5 查找丢失数据的现象,也就是成功+失败的记录数不等于一共插入的记录数,找出这些数据并显示行号和对应行的日志信息
awk '{if($8!=$14+$17) print NR,$0}' db.log.20190608

写入文件的方式
exam5.awk
BEGIN{
}
{
if($8!=$14+$17)
print NR,$0
}
awk -f exam5.awk db.log.20190608

awk 常用选项及数组的用法和模拟生产环境数据统计的更多相关文章
- shell编程系列21--文本处理三剑客之awk中数组的用法及模拟生产环境数据统计
shell编程系列21--文本处理三剑客之awk中数组的用法及模拟生产环境数据统计 shell中的数组的用法: shell数组中的下标是从0开始的 array=("Allen" & ...
- shell编程系列20--文本处理三剑客之awk常用选项
shell编程系列20--文本处理三剑客之awk常用选项 awk选项总结 选项 解释 -v 参数传递 -f 指定脚本文件 -F 指定分隔符 -V 查看awk的版本号 [root@localhost s ...
- find一些常用参数的一些常用实例和一些具体用法和注意事项。
find一些常用参数的一些常用实例和一些具体用法和注意事项. 1.使用name选项: 文件名选项是find命令最常用的选项,要么单独使用该选项,要么和其他选项一起使用. 可以使用某种文件名模式来匹配 ...
- centos7之sed和awk常用
sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响.处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令 ...
- AWK常用技巧
1.1 介绍 awk其名称得自于它的创始人 Alfred Aho .Peter Weinberger 和 Brian Kernighan 姓氏的首个字母.实际上 AWK 的确拥有自己的语言: AWK ...
- Linux生产环境上,最常用的一套“AWK“技巧【转】
最有用系列: <Linux生产环境上,最常用的一套“vim“技巧> <Linux生产环境上,最常用的一套“Sed“技巧> <Linux生产环境上,最常用的一套“AWK“技 ...
- zip命令的常用选项
zip命令的常用选项 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 大家都知道,在linux上一切皆文件,在实际生产环境中,如果我们需要部署一些系统的服务,我们会将一些软件包提前下 ...
- FPGA综合工具--Synplify Pro的常用选项及命令
最近要用到Synplify,但以前没使用过,无基础,找到一篇帖子,隧保存下来. 本文转自:http://blog.sina.com.cn/s/blog_65fe490d0100v8ax.html Sy ...
- curl常用选项详解
curl常用选项详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 又是下班的时间了,让我们一起来学习一下今天的Linux命令吧~我一半只把自己常用的参数列出来,其他的有但是我们几 ...
随机推荐
- visual studio code 调试ROS的插件
ctrl+p搜索: ext install ros https://marketplace.visualstudio.com/items?itemName=ajshort.ros 进行安装 其他可以调 ...
- 【JAVA】java注解的自定义和使用
java注解概念 Java提供了一种原程序中的元素关联任何信息和任何数据的途径和方法 java注解介绍 常用注解 @Override:表示方法是重写的方法 @Deprecated:过时的方法 @Sup ...
- JFreechart从入门到放弃
JFreechart从入门到放弃 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 http://www.jfree.org/jfreechart/ 引言 干嘛用的 使用java画图, ...
- 转 RAC srvctl 管理命令
https://czmmiao.iteye.com/blog/1762900 https://blog.csdn.net/weeknd/article/details/72358218 ------- ...
- 【tshark tcpdump】linux网络排查
抓包: 1.tcpdump 2.tshark是wireshark的命令行版. tshark使用示例: ,实时打印当前http请求的url # tshark -s -i eth0 -n -f 'tcp ...
- zookeeper的java api操作
zookeeper的java api操作 创建会话: Zookeeper(String connectString,int sessionTimeout,Watcher watcher) Zookee ...
- Linux下的Curses库的源码下载与安装
curses库是可以在linux终端中写出字符用户界面的一个库,现在较新的版本应该是ncurses库,现在已经很少有人再去使用他了,所以想拥有这个库并且在linux下写出自己用户界面的可以参考一下本博 ...
- centos7修改yum源为阿里镜像
参考博客: https://blog.csdn.net/kxwinxp/article/details/78578492 https://blog.csdn.net/inslow/article/de ...
- CMakeLists 添加 -pthread 编译选项 undefined reference to pthread_atfork
在与 main() 函数同级的 CMakeLists 中添加如下内容(根据项目实际情况修改): cmake_minimum_required (VERSION 2.6) find_package (T ...
- python之numpy和pandas
一.numpy矩阵的拼接合并 列拼接:np.column_stack() >>> import numpy as np >>> a = np.arange(9).r ...