EM 算法(三)-GMM
高斯混合模型
混合模型,顾名思义就是几个概率分布密度混合在一起,而高斯混合模型是最常见的混合模型;
GMM,全称 Gaussian Mixture Model,中文名高斯混合模型,也就是由多个高斯分布混合起来的模型;
概率密度函数为
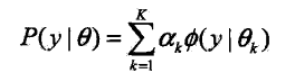
K 表示高斯分布的个数,αk 表示每个高斯分布的系数,αk>0,并且 Σαk=1,
Ø(y|θk) 表示每个高斯分布,θk 表示每个高斯分布的参数,θk=(uk,σk2);
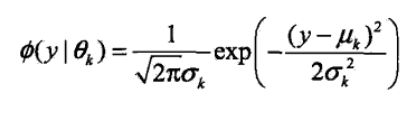
举个例子
男人和女人的身高都服从各自的高斯分布,把男人女人混在一起,那他们的身高就服从高斯混合分布;
高斯混合模型就是用混合在一起的身高数据,估计男人和女人各自的高斯分布
小结
GMM 实际上分为两步,第一步是选择一个高斯分布,如男人数据集,这里涉及取到某个分布的概率,αk,
然后从该分布中取一个样本,等同于普通高斯分布
GMM 常用于聚类,也就是把每个概率密度分布聚为一类;如果概率密度分布为已知,那就变成参数估计问题
EM 解释 GMM
EM 的核心是 隐变量 和 似然函数

求导结果如下
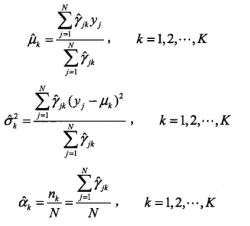
GMM 的 EM 算法

算法流程

Python 实现 GMM
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
from scipy.stats import multivariate_normal
plt.style.use('seaborn') # 生成数据
def generate_X(true_Mu, true_Var):
### 生成2000条二维模拟数据,其中400个样本来自N(μ1,var1) ,600个来自N(μ2,var2) ,1000个样本来自N(μ3,var3)
# 第一簇的数据
num1, mu1, var1 = 400, true_Mu[0], true_Var[0]
X1 = np.random.multivariate_normal(mu1, np.diag(var1), num1)
# 第二簇的数据
num2, mu2, var2 = 600, true_Mu[1], true_Var[1]
X2 = np.random.multivariate_normal(mu2, np.diag(var2), num2)
# 第三簇的数据
num3, mu3, var3 = 1000, true_Mu[2], true_Var[2]
X3 = np.random.multivariate_normal(mu3, np.diag(var3), num3)
# 合并在一起
X = np.vstack((X1, X2, X3))
# 显示数据
plt.figure(figsize=(10, 8))
plt.axis([-10, 15, -5, 15])
plt.scatter(X1[:, 0], X1[:, 1], s=5)
plt.scatter(X2[:, 0], X2[:, 1], s=5)
plt.scatter(X3[:, 0], X3[:, 1], s=5)
plt.show()
return X # 更新W
def update_W(X, Mu, Var, Pi):
n_points, n_clusters = len(X), len(Pi)
pdfs = np.zeros(((n_points, n_clusters)))
for i in range(n_clusters):
pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))
W = pdfs / pdfs.sum(axis=1).reshape(-1, 1)
return W # 更新pi
def update_Pi(W):
Pi = W.sum(axis=0) / W.sum()
return Pi # 计算log似然函数
def logLH(X, Pi, Mu, Var):
# 仅计算损失,这步可有可无
n_points, n_clusters = len(X), len(Pi)
pdfs = np.zeros(((n_points, n_clusters)))
for i in range(n_clusters):
pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))
return np.mean(np.log(pdfs.sum(axis=1))) # 画出聚类图像
def plot_clusters(X, Mu, Var, Mu_true=None, Var_true=None):
colors = ['b', 'g', 'r']
n_clusters = len(Mu)
plt.figure(figsize=(10, 8))
plt.axis([-10, 15, -5, 15])
plt.scatter(X[:, 0], X[:, 1], s=5)
ax = plt.gca()
for i in range(n_clusters):
plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'ls': ':'}
ellipse = Ellipse(Mu[i], 3 * Var[i][0], 3 * Var[i][1], **plot_args)
ax.add_patch(ellipse)
if (Mu_true is not None) & (Var_true is not None):
for i in range(n_clusters):
plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'alpha': 0.5}
ellipse = Ellipse(Mu_true[i], 3 * Var_true[i][0], 3 * Var_true[i][1], **plot_args)
ax.add_patch(ellipse)
plt.show() # 更新Mu
def update_Mu(X, W):
n_clusters = W.shape[1]
Mu = np.zeros((n_clusters, 2))
for i in range(n_clusters):
Mu[i] = np.average(X, axis=0, weights=W[:, i])
return Mu # 更新Var
def update_Var(X, Mu, W):
n_clusters = W.shape[1]
Var = np.zeros((n_clusters, 2))
for i in range(n_clusters):
Var[i] = np.average((X - Mu[i]) ** 2, axis=0, weights=W[:, i])
return Var if __name__ == '__main__':
# 生成数据
true_Mu = [[0.5, 0.5], [5.5, 2.5], [1, 7]]
true_Var = [[1, 3], [2, 2], [6, 2]]
X = generate_X(true_Mu, true_Var)
# 初始化
n_clusters = 3 # 聚类个数
n_points = len(X) # 样本数
Mu = [[0, -1], [6, 0], [0, 9]] # 3 个期望
Var = [[1, 1], [1, 1], [1, 1]] # 3 个方差
Pi = [1 / n_clusters] * 3
W = np.ones((n_points, n_clusters)) / n_clusters # 隐变量,每个样本属于每个分布的概率
Pi = W.sum(axis=0) / W.sum() # 每个分布的比率
# 迭代
loglh = []
for i in range(5):
plot_clusters(X, Mu, Var, true_Mu, true_Var)
loglh.append(logLH(X, Pi, Mu, Var))
W = update_W(X, Mu, Var, Pi)
Pi = update_Pi(W)
Mu = update_Mu(X, W)
print('log-likehood:%.3f'%loglh[-1])
Var = update_Var(X, Mu, W)
参考资料:
https://blog.csdn.net/jinping_shi/article/details/59613054
《统计学习方法》李航
EM 算法(三)-GMM的更多相关文章
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 机器学习(七)EM算法、GMM
一.GMM算法 EM算法实在是难以介绍清楚,因此我们用EM算法的一个特例GMM算法作为引入. 1.GMM算法问题描述 GMM模型称为混合高斯分布,顾名思义,它是由几组分别符合不同参数的高斯分布的数据混 ...
- 机器学习——EM算法与GMM算法
目录 最大似然估计 K-means算法 EM算法 GMM算法(实际是高斯混合聚类) 中心思想:①极大似然估计 ②θ=f(θold) 此算法非常老,几乎不会问到,但思想很重要. EM的原理推导还是蛮复杂 ...
- EM算法之GMM聚类
以下为GMM聚类程序 import pandas as pd import matplotlib.pyplot as plt import numpy as np data=pd.read_csv(' ...
- 【机器学习】GMM和EM算法
机器学习算法-GMM和EM算法 目录 机器学习算法-GMM和EM算法 1. GMM模型 2. GMM模型参数求解 2.1 参数的求解 2.2 参数和的求解 3. GMM算法的实现 3.1 gmm类的定 ...
- 6. EM算法-高斯混合模型GMM+Lasso详细代码实现
1. 前言 我们之前有介绍过4. EM算法-高斯混合模型GMM详细代码实现,在那片博文里面把GMM说涉及到的过程,可能会遇到的问题,基本讲了.今天我们升级下,主要一起解析下EM算法中GMM(搞事混合模 ...
- GMM与EM算法
用EM算法估计GMM模型参数 参考 西瓜书 再看下算法流程
- 最大熵模型和EM算法
一.极大似然已经发生的事件是独立重复事件,符合同一分布已经发生的时间是可能性(似然)的事件利用这两个假设,已经发生时间的联合密度值就最大,所以就可以求出总体分布f中参数θ 用极大似然进行机器学习有监督 ...
- PLSA及EM算法
前言:本文主要介绍PLSA及EM算法,首先给出LSA(隐性语义分析)的早期方法SVD,然后引入基于概率的PLSA模型,其参数学习采用EM算法.接着我们分析如何运用EM算法估计一个简单的mixture ...
随机推荐
- easyUI的datagrid控件日期列格式化
转自:https://blog.csdn.net/idoiknow/article/details/8136093 EasyUI是一套比较轻巧易用的Jquery控件,在使用过程中遇到一个问题,它的列表 ...
- C++入门经典-例7.3-析构函数的调用
1:析构函数的名称标识符就是在类名标识符前面加“~”.例如: ~CPerson(); 2:实例代码: (1)title.h #include <string>//title是一个类,此为构 ...
- C++入门经典-例7.2-利用构造函数初始化成员变量
1:在创建对象时,程序自动调用构造函数.同一个类中可以有多个构造函数,通过这样的形式创建一个CPerson对象,例如: CPerson p1(0,"jack",22,7000); ...
- VNC Viewer配置
VNC概述 VNC (Virtual Network Computing)是虚拟网络计算机的缩写.VNC 是一款优秀的远程控制工具软件,由著名的 AT&T 的欧洲研究实验室开发的.VNC 是在 ...
- Anaconda 改为国内镜像的方法
Anaconda的conda 特别好用 但如果用国外的镜像,慢的出奇 可以改为了国内镜像会好很多 conda config --add channels https://mirrors.tuna.ts ...
- CentOS6.5 64位下装Docker
试装,仅仅是做个记录. [root@localhost ~]# sudo tee /etc/yum.repos.d/docker.repo <<-'EOF' > ; > [do ...
- C# 中使用RegisterShellHookWindow Hook窗体创建
前言:最近在写一个桌面程序时需要全局HOOK 窗体的创建,但是在.net中SetWindowsHookEx()只可实现键盘鼠标的全局钩子,其余的全局钩子都需要使用DLL.难道就没有解决办法了么?经过长 ...
- SSD 页、块、垃圾回收
基本操作: 读出.写入.擦除: 因为NAND闪存单元的组织结构限制,单独读写一个闪存单元是不可能的.存储单元被组织起来并有着十分特别的属性.要知道这些属性对于为固态硬盘优化数据结构的过程和理解其行为来 ...
- php获取文件名和后缀名
php获取文件名 1 function retrieve($url) 2 { 3 preg_match('/\/([^\/]+\.[a-z]+)[^\/]*$/',$url,$match); 4 re ...
- 绝对好用Flash多文件大文件上传控件
本实例采用的是Uploadify上传插件,.NET程序,源程序是从网上找的,但是有Bug,已经修改好,并标有部分注释.绝对好用,支持单文件.多文件上传,支持大文件上传,已经过多方面测试,保证好用. 以 ...