deep_learning_CNN
AI学习笔记——卷积神经网络(CNN)
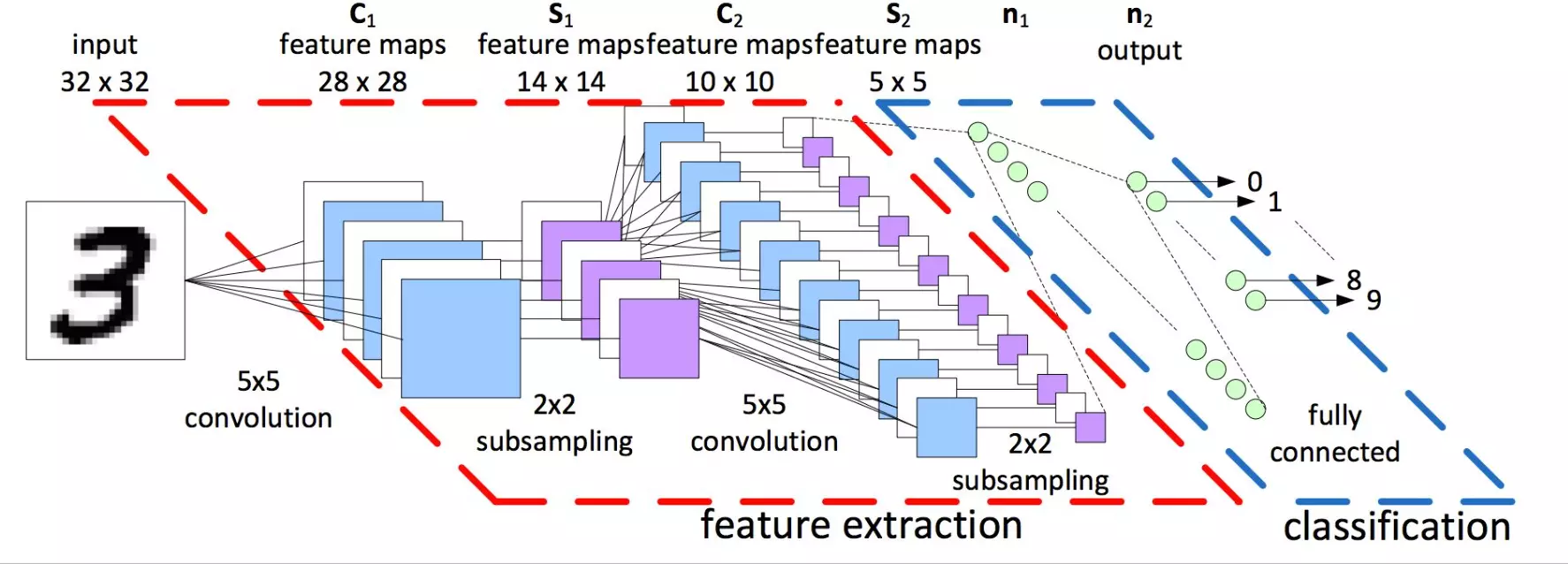
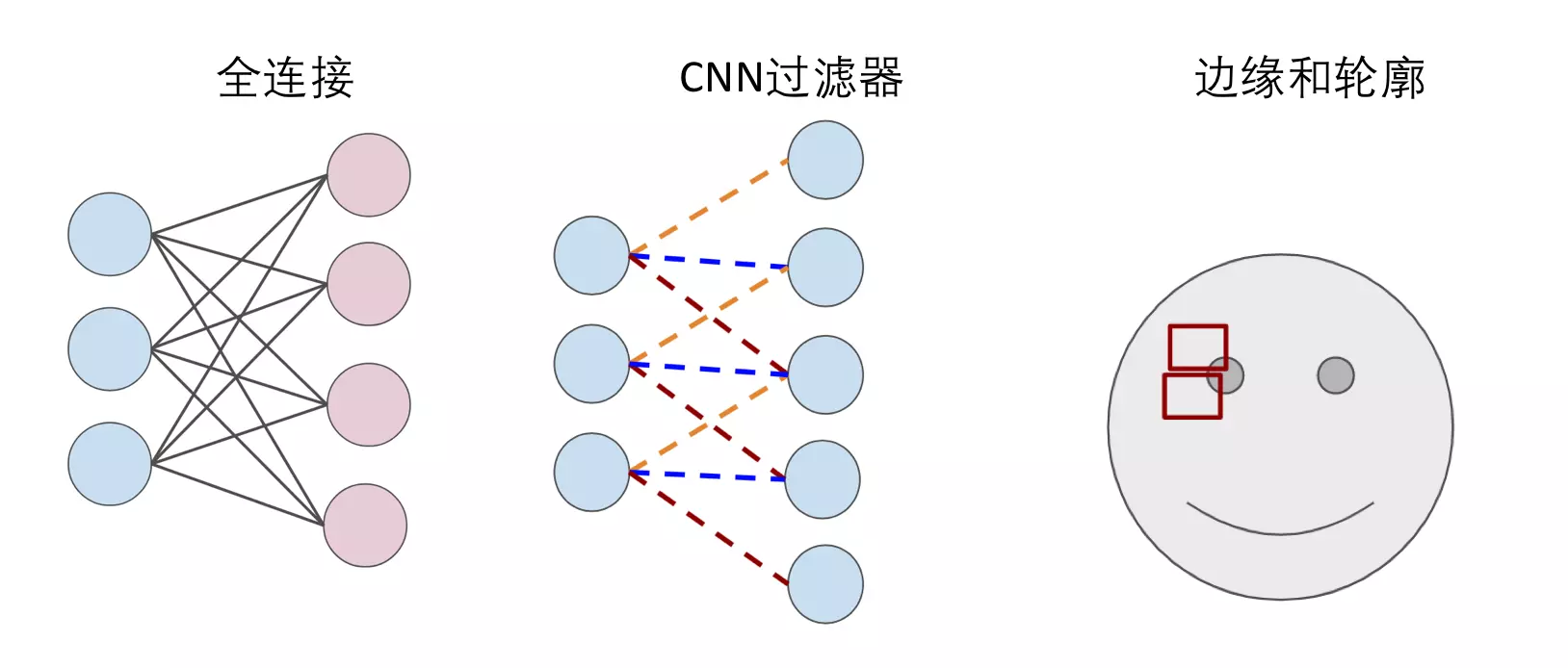
上篇文章简单地地介绍了神经网络和深度学习,在神经网络中,每一层的每个神经元都与下一层的每个神经元相连(如下图), 这种连接关系叫全连接(Full Connected)。如果以图像识别为例,输入就是是每个像素点,那么每一个像素点两两之间的关系(无论相隔多远),都被下一层的神经元"计算"了。
这种全连接的方法用在图像识别上面就显得太"笨"了,因为图像识别首先得找到图片中各个部分的"边缘"和"轮廓",而"边缘"和"轮廓"只与相邻近的像素们有关。
这个时候卷积神经网络(CNN)就派上用场了,卷积神经网络可以简单地理解为,用滤波器(Filter)将相邻像素之间的"轮廓"过滤出来。
卷积(Convolution)
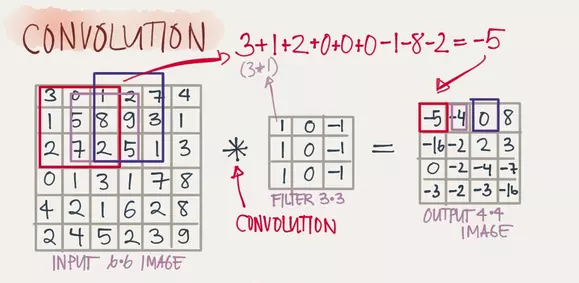
卷积的滤波器(Filter)是如何工作的呢?以下图,一个6x6的图片被一个3x3的滤波器(可以看成一个窗口)卷积为例,3x3的滤波器先和6x6的图片最左上角的3x3矩阵卷积得到结果后,再向右移一步继续卷积(窗口滑动),直到将整个图片过滤完成,输出一个4x4的矩阵(图片)。
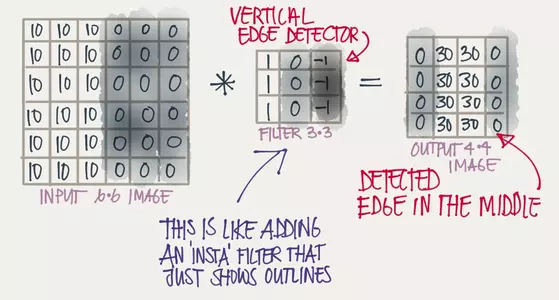
这样有什么意义呢?如果如下图所示,被卷积的图片有明显的竖直轮廓(10和0之间有一轮廓,这条轮廓需要被标记出来),用3x3的竖直轮廓滤波器卷积之后,就能发现中间那条非常明显的竖直轮廓(中间30的两个竖排矩阵将竖直的轮廓位置明显地标记了出来)。
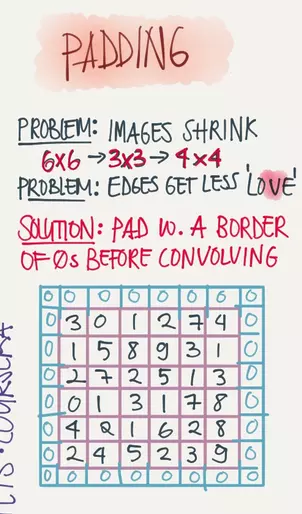
填充(Padding)
上面的例子用3x3的将6x6的图片过滤之后输出了一个4x4的图片,那如果我想保证输入和输出的图片尺寸一致怎么办?这个时候我们可以在原图片的边缘进行填充(Padding),以保证输入和输出的图片尺寸一致。下图就是用0在原图上Padding了一圈。
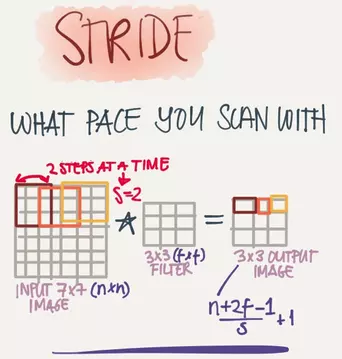
步长 (Stride)
上面提到用3x3的过滤器去卷积6x6的图片是通过窗口一步一步的移动最终将整个图片卷积完成的,实际上移动的步伐可以迈得更大,这个步伐的长度就叫做步长(Stride)。步长(Stride)和填充(Padding)的大小一起决定了输出层图像的尺寸。
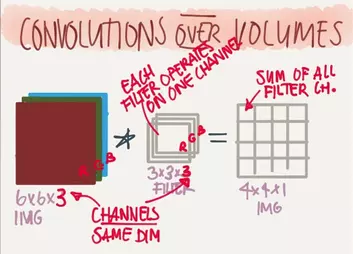
深度(Depth)
这里的深度是指输出层图片的深度,通常图片有红绿蓝(RGB)三个颜色通道(Channel),那一个滤波器也需要三层滤波器对每个颜色通道进行过滤,于是6x6x3的图片经过3x3x3的滤波器过滤之后最终会得到一个4x4x1的图片,此时输出层图片的深度就是1。
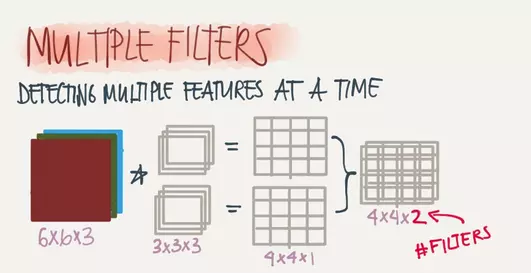
增加滤波器的个数就能增加输出层图片的深度,同时滤波器的个数也决定了输出层图片的深度(两者相等)。下图两个3x3x3的滤波器将6x6x3的图片过滤得到一个4x4x2的图片。
单层完整的CNN
全连接的DNN,每一层包含一个线性函数和一个激活函数,CNN也一样,在滤波器之后还需要一个激活层,在图像识别应用中,激活层通常用的是Relu函数。线性函数有权重W和偏置b,CNN的权重W就是滤波器的数值,偏置b可以加在Relu之后,一个完整的CNN层如下:
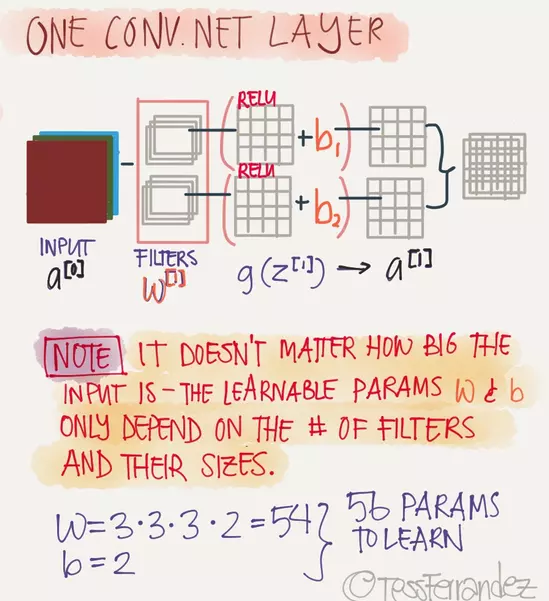
池化(Pooling)
用滤波器进行窗口滑动过程中,�实际上"重叠"计算了很多冗余的信息,而池化操作就是去除这些冗余信息,并加快运动。Pooling的方式其实有多种,用的最多的是max-pooling就是取一个区域中最大的值,如图将一个4x4的图片max-pooling 一个2x2的图片。
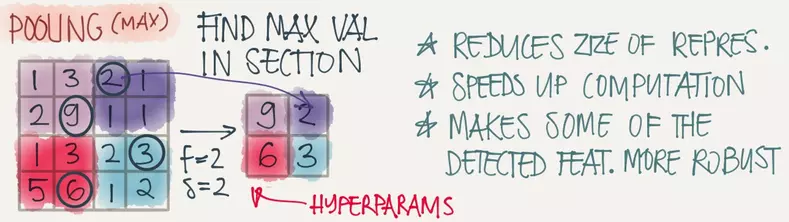
一个完整的深度CNN网络
一个完整的深度CNN网络,通常由多个卷积层加池化层和最后一个或多个完整层(Full connected(FC))构成,如图:
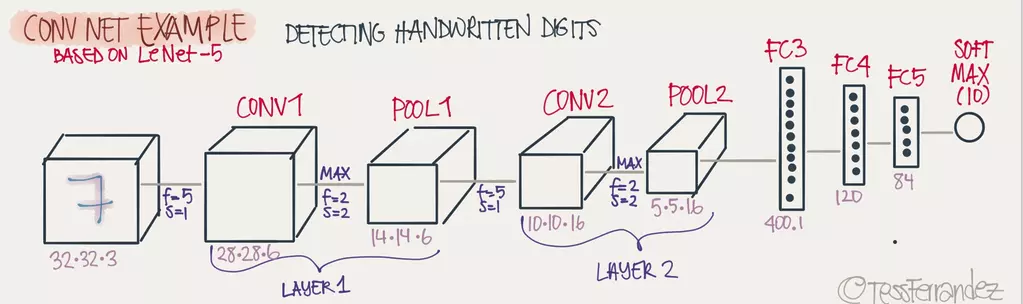
好了,深度卷积神经网络就介绍完了,中间引入了不少概念,理解了这些概念其实CNN网络也十分简单。
转自:https://www.jianshu.com/p/49b70f6480d1

deep_learning_CNN的更多相关文章
随机推荐
- Dozer映射
1.为什么要映射 一个映射的框架在一个分层的体系架构中非常有用,特别是你在创建一个抽象的分层去包装一些特殊数据的变化 vs 这些数据传输到其它层(外部服务的数据对象.领域的数据对象.数据传输对象.内部 ...
- 微服务的脚手架Jhipster使用(一)
随着微服务的普及以及docker容器的广泛应用,有传统的soa服务衍生出微服务的概念,微服务强调的是服务的独立性,屏蔽底层物理平台的差异,此时你会发现微服务跟容器技术完美契合.在此基础上衍生出的云原生 ...
- spring-kafka —— 生产者消费者重要配置
一.生产者配置 # 以逗号分隔的主机:端口对列表,用于建立与Kafka群集的初始连接 spring.kafka.producer.bootstrap-servers=TopKafka1:9092,To ...
- MYSQL理论学习
最近在复习数据库相关的知识,主要是以“SQL必知必会”这本书为参考,结合网上相关博客,记录学习的要点.本篇博客会持续更新,便于以后复习. 参考博客:http://blog4jimmy.com/2017 ...
- react-native-scrollable-tab-view第一次加载下划线不显示解决
今天在使用react-native-scrollable-tab-view的时候出现下划线第一次显示的时候不显示,需要点击切换才可以显示. 通过各种实践发现是0.6.7版本问题. 解决实现: reac ...
- Spark在Windows上调试
1. 背景 (1) spark的一般开发与运行流程是在本地Idea或Eclipse中写好对应的spark代码,然后打包部署至驱动节点,然后运行spark-submit.然而,当运行时异常,如空指针或数 ...
- main.js中的Vue.config.productionTip = false
开发模式:npm run dev是前端自己开发用的生产模式:npm run build 打包之后给后端放在服务端上用的Vue.config.productionTip = false1上面这行代码的意 ...
- VMware workstation安装Windows Server 2012 R2步骤详解(附下载链接)
话不多说,直接上链接.所需工具: 1.VMware workstation 14.0(版本无所谓) 附链接:https://pan.baidu.com/s/1CrH ...
- Linux安装sdkman
项目使用java的开发者一定会为新配环境变量而头大,sdkman很好的解决了系统sdk管理的痛点,仅需简单的几行命令就可以完成sdk的安装,更改默认版本.再也不用担心环境变量的问题. 安装 既然是命令 ...
- 关于python脚本头部设置#!/usr/bin/python
今天又是贼几把菜的一天0.0 读别人程序的时候看到在python文件头部设置签名,感觉贼几把酷,自己也试着在文件前段设置了一下. 设置还是蛮简单的,设置过程如图所示. 设置后如图所示: 当然你也可能看 ...