ID3算法(MATLAB)
ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
①对当前样本集合,计算所有属性的信息增益;
②选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集;
③若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集递归调用本算法。
结合餐饮案例实现ID3的具体实施步骤。
T餐饮企业作为大型的连锁企业,生产的产品种类比较多,另外涉及的分店所处的位置也不同、数目也比较多。对于企业的高层来讲,了解周末和非周末销量是否有大的区别,以及天气、促销活动等因素是否能够影响门店的销量这些信息至关重要。因此,为了让决策者准确地了解和销量有关的一系列影响因素,需要构建模型来分析天气、是否周末和是否有促销活动对其销量的影响,下面以单个门店来进行分析。
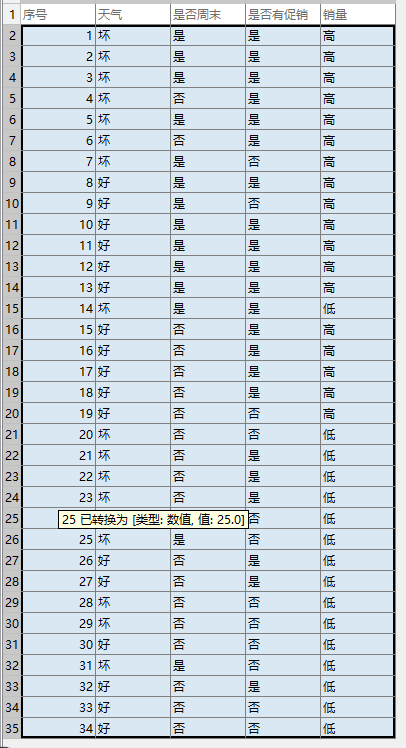
①计算总的信息熵,其中数据中总记录数为34,而销售数量为“高”的数据有18,“低”的有16。$$I(18,16)=-\frac{18}{34} \log _{2} \frac{18}{34}-\frac{16}{34} \log _{2} \frac{16}{34}=0.997503$$
②计算每个测试属性的信息熵。
对于天气属性,其属性值有“好”和“坏”两种。
其中天气为“好”的条件下,销售数量为“高”的记录为11,销售数量为“低”的记录为6,可表示为(11,6);
天气为“坏”的条件下,销售数量为“高”的记录为7,销售数量为“低”的记录为10,可表示为(7,10)。
$$\begin{array}{*{20}{l}}
{I(11,6) = - \frac{{11}}{{17}}{{\log }_2}\frac{{11}}{{17}} - \frac{6}{{17}}{{\log }_2}\frac{6}{{17}} = 0.936667}\\
{I(7,10) = - \frac{7}{{17}}{{\log }_2}\frac{7}{{17}} - \frac{{10}}{{17}}{{\log }_2}\frac{{10}}{{17}} = 0.977418}\\
{E\left( {天气} \right) = \frac{{17}}{{34}}I(11,6) + \frac{{17}}{{34}}I(7,10) = 0.957043}
\end{array}$$
对于是否周末属性,其属性值有“是”和“否”两种。
其中是否周末属性为“是”的条件下,销售数量为“高”的记录为11,销售数量为“低”的记录为3,可表示为(11,3);
是否周末属性为“否”的条件下,销售数量为“高”的记录为7,销售数量为“低”的记录为13,可表示为(7,13)。
$$\begin{array}{*{20}{l}}
{\begin{array}{*{20}{l}}
{I(11,3) = - \frac{{11}}{{14}}{{\log }_2}\frac{{11}}{{14}} - \frac{3}{{14}}{{\log }_2}\frac{3}{{14}} = 0.749595}\\
{I(7,13) = - \frac{7}{{20}}{{\log }_2}\frac{7}{{20}} - \frac{{13}}{{20}}{{\log }_2}\frac{{13}}{{20}} = 0.934068}
\end{array}}\\
{E\left( {是否周末} \right) = \frac{{14}}{{34}}I(11,3) + \frac{{20}}{{34}}I(7,13) = 0.858109}
\end{array}$$
对于是否有促销属性,其属性值有“是”和“否”两种。
其中是否有促销属性为“是”的条件下,销售数量为“高”的记录为15,销售数量为“低”的记录为7,可表示为(15,7);
其中是否有促销属性为“否”的条件下,销售数量为“高”的记录为3,销售数量为“低”的记录为9,可表示为(3,9)。
$$\begin{array}{*{20}{c}}
{I(15,7) = - \frac{{15}}{{22}}{{\log }_2}\frac{{15}}{{22}} - \frac{7}{{22}}{{\log }_2}\frac{7}{{22}} = 0.902393}\\
{I(3,9) = - \frac{3}{{12}}{{\log }_2}\frac{3}{{12}} - \frac{9}{{12}}{{\log }_2}\frac{9}{{12}} = 0.811278}\\
{E\left( {是否有促销} \right) = \frac{{22}}{{34}}I(15,7) + \frac{{12}}{{34}}I(3,9) = 0.870235}
\end{array}$$
③计算天气、是否周末和是否有促销属性的信息增益值。
天气:$0.997503-0.957043=0.04046$
是否周末:$0.997503-0.858109=0.139394$
有无促销属性:$0.997503-0.870235=0.127268$
其中,是否周末的信息增益值最大,以其为根节点,其左右分支为“是”与“否”,
④依据增益值生成决策树。
代码:
%% 使用ID3决策树算法预测销量高低
clear ;
% 参数初始化
inputfile = '../data/sales_data.xls'; % 销量及其他属性数据
%% 数据预处理
disp('正在进行数据预处理...');
[matrix,attributes_label,attributes] = id3_preprocess(inputfile);
%% 构造ID3决策树,其中id3()为自定义函数
disp('数据预处理完成,正在进行构造树...');
tree = id3(matrix,attributes_label,attributes);
%% 打印并画决策树
[nodeids,nodevalues] = print_tree(tree);
tree_plot(nodeids,nodevalues);
disp('ID3算法构建决策树完成!');

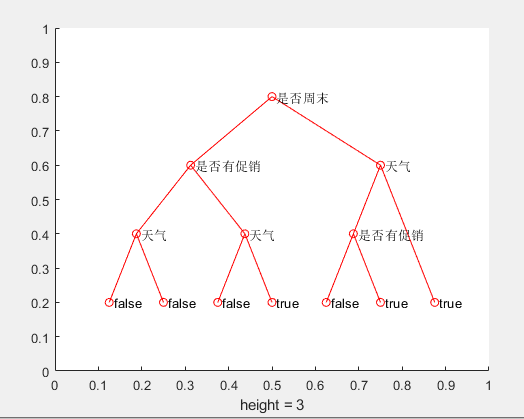
依据结果,我们可以得出以下结论:
若周末属性为“是”,天气为“好”,则销售数量为“高”;
若周末属性为“是”,天气为“坏”,促销属性为“是”,则销售数量为“高”;
若周末属性为“是”,天气为“坏”,促销属性为“否”,则销售数量为“低”;
若周末属性为“否”,促销属性为“否”,则销售数量为“低”;
若周末属性为“否”,促销属性为“是”,天气为“好”,则销售数量为“高”;
若周末属性为“否”,促销属性为“是”,天气为“坏”,则销售数量为“低”。
由于ID3决策树算法采用了信息增益作为选择测试属性的标准,会偏向于选择取值较多的即所谓的高度分支属性,而这类属性并不一定是最优的属性。同时,ID3决策树算法只能处理离散属性,对于连续型的属性,在分类前需要对其进行离散化。
ID3算法(MATLAB)的更多相关文章
- 简单易学的机器学习算法——决策树之ID3算法
一.决策树分类算法概述 决策树算法是从数据的属性(或者特征)出发,以属性作为基础,划分不同的类.例如对于如下数据集 (数据集) 其中,第一列和第二列为属性(特征),最后一列为类别标签,1表示是 ...
- 决策树ID3算法的java实现(基本试用所有的ID3)
已知:流感训练数据集,预定义两个类别: 求:用ID3算法建立流感的属性描述决策树 流感训练数据集 No. 头痛 肌肉痛 体温 患流感 1 是(1) 是(1) 正常(0) 否(0) 2 是(1) 是(1 ...
- 数据挖掘之决策树ID3算法(C#实现)
决策树是一种非常经典的分类器,它的作用原理有点类似于我们玩的猜谜游戏.比如猜一个动物: 问:这个动物是陆生动物吗? 答:是的. 问:这个动物有鳃吗? 答:没有. 这样的两个问题顺序就有些颠倒,因为一般 ...
- 决策树 -- ID3算法小结
ID3算法(Iterative Dichotomiser 3 迭代二叉树3代),是一个由Ross Quinlan发明的用于决策树的算法:简单理论是越是小型的决策树越优于大的决策树. 算法归 ...
- 机器学习笔记----- ID3算法的python实战
本文申明:本文原创,如有转载请申明.数据代码来自实验数据都是来自[美]Peter Harrington 写的<Machine Learning in Action>这本书,侵删. Hell ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 决策树笔记:使用ID3算法
决策树笔记:使用ID3算法 决策树笔记:使用ID3算法 机器学习 先说一个偶然的想法:同样的一堆节点构成的二叉树,平衡树和非平衡树的区别,可以认为是"是否按照重要度逐渐降低"的顺序 ...
- ID3算法 决策树的生成(2)
# coding:utf-8 import matplotlib.pyplot as plt import numpy as np import pylab def createDataSet(): ...
- ID3算法 决策树的生成(1)
# coding:utf-8 import matplotlib.pyplot as plt import numpy as np import pylab def createDataSet(): ...
随机推荐
- BCB 中 Application->CreateForm 和 New 的一个区别
Application->Create 和 NEW 的一个区别 最近写windows服务的时候,恰巧碰到一个问题.我建立了一个DataModal,然后在Datamodal的OnCreate 事件 ...
- 【数位DP-板子题目】HDU-3555-Bomb- [只要49]
Bomb Time Limit: / MS (Java/Others) Memory Limit: / K (Java/Others) Total Submission(s): Accepted Su ...
- Why Go? – Key advantages you may have overlooked
Why Go? – Key advantages you may have overlooked yourbasic.org/golang Go makes it easier (than Java ...
- React 新特性学习
1 context 2 contextType 3 lazy 4 suspense 5 memo 6 hooks 7 effect hooks =========== 1 Context 提供了一种方 ...
- Vuex的mapGetters方法使用报错
报错信息: ERROR in ./node_modules/babel-loader/lib!./node_modules/vue-loader/lib/selector.js?type=script ...
- django加载本地html
django加载本地html from django.shortcuts import render from django.http import HttpResponse from django. ...
- string::at
char& at (size_t pos); const char& at (size_t pos) const; #include <string>#include &l ...
- P2168 [NOI2015]荷马史诗 k叉哈夫曼树
思路:哈夫曼编码 提交:1次(参考题解) 题解:类似合并果子$QwQ$ 取出前$k$小(注意如果叶子结点不满的话要补全),合并起来再扔回堆里去. #include<cstdio> #inc ...
- 富文本编辑器直接从 word 中复制粘贴公式
在之前在工作中遇到在富文本编辑器中粘贴图片不能展示的问题,于是各种网上扒拉,终于找到解决方案,在这里感谢一下知乎中众大神以及TheViper. 通过知乎提供的思路找到粘贴的原理,通过TheViper找 ...
- java集合类-Set接口
Set集合 Set集合中的对象不按特定的方式排序,只是简单的把对象放入集合中,但是不能包含重复对象. Set集合由Set接口和Set接口的实现类组成,Set接口继承与于Collection接口 Set ...