梯度提升树GBDT总结
提升树的学习优化过程中,损失函数平方损失和指数损失时候,每一步优化相对简单,但对于一般损失函数优化的问题,Freidman提出了Gradient Boosting算法,其利用了损失函数的负梯度在当前模型的值:
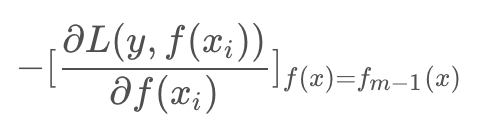
作为回归问题提升树算法的残差近似值,去拟合一个回归树。
函数空间的数值优化
优化目标是使得损失函数最小,(N是样本集合大小):

GBDT是一个加法模型: fm(x) 是每一次迭代学习的到树模型

对于其每一步迭代:
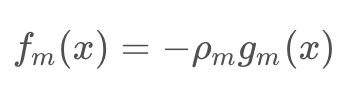
其中
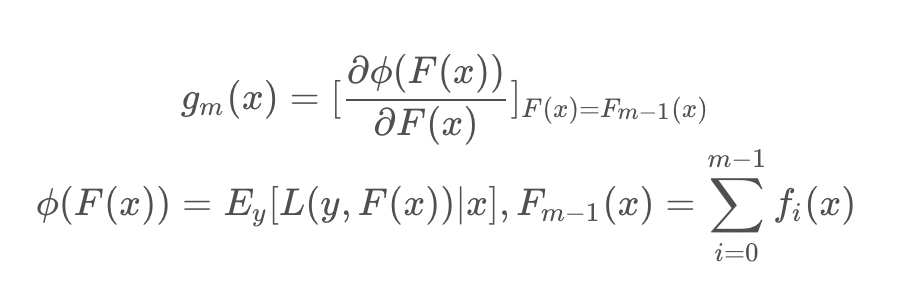
其实 L(y,F(x)) 就是损失函数,Φ(F(x)) 是当前x下的损失期望,gm(x) 是当前x下的函数梯度。最终 fm(x) 学习的是损失函数在函数空间上的负梯度。
对于权重 ρm 通过线性搜索求解:
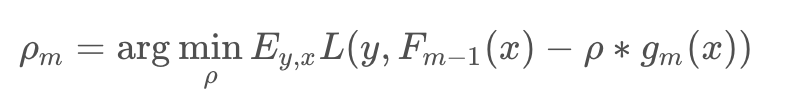
理解:每一次迭代可以看做是采用梯度下降法对最优分类器 F*(x) 的逐渐比较,每一次学习的模型 fm(x) 是梯度,进过M步迭代之后,最后加出来的模型就是最优分类器的一个逼近模型,所以 fm(xi) 使用单步修正方向 -gm(xi):
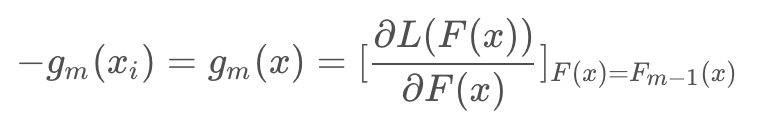
这里的梯度变量是函数,是在函数空间上求解(这也是后面XGBoost改进的点),注意以往算法梯度下降是在N维的参数空间的负梯度方向,变量是参数。这里的变量是函数,更新函数通过当前函数的负梯度方向来修正模型,使它更优,最后累加的模型近似最优函数。
算法描述
输入:训练数据集 T={(x1,y1),(x2,y2),···,(xN,yN)}
输出:回归树 fM(x)
1. 初始化

2. 对 m=1,2,…M
a. 对 i=1,2,…,N ,计算
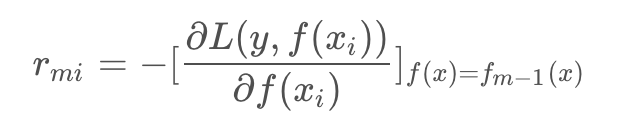
b. 对 rmi 拟合一颗回归树,得到第m棵树的叶结点区域 Rmj, j=1,2,…,J ,即一棵由J个叶子节点组成的树
c. 对 j=1,2,…,J ,计算
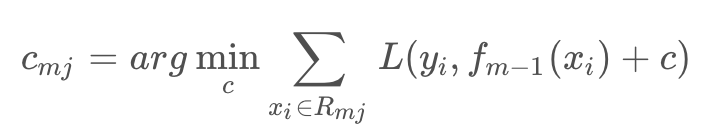
上面两步相当于回归树递归在遍历所有切分变量j和切分点s找到最优j,s,然后在每个节点区域求最优的c
d. 更新
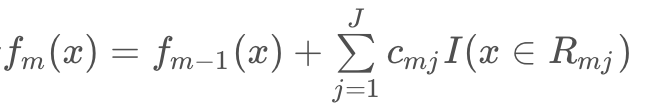
3. 得到回归树
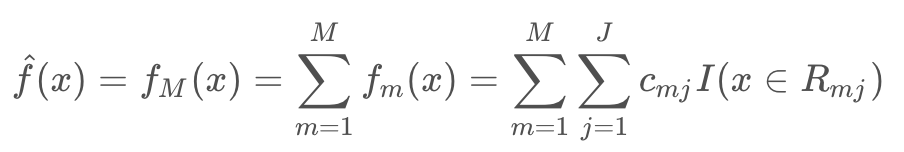
在回归树生成时,建树选择分裂点必须要遍历所有数据在每个特征的每个切分点的值,如果是连续特征就计算复杂度非常大,也是GBDT训练主要耗时所在。
参考
GBDT原理-Gradient Boosting Decision Tree
梯度提升树GBDT总结的更多相关文章
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
- 机器学习 之梯度提升树GBDT
目录 1.基本知识点简介 2.梯度提升树GBDT算法 2.1 思路和原理 2.2 梯度代替残差建立CART回归树 1.基本知识点简介 在集成学习的Boosting提升算法中,有两大家族:第一是AdaB ...
- scikit-learn 梯度提升树(GBDT)调参笔记
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- 笔记︱决策树族——梯度提升树(GBDT)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记来源于CDA DSC,L2-R语言课程所 ...
- 梯度提升树GBDT算法
转自https://zhuanlan.zhihu.com/p/29802325 本文对Boosting家族中一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 简 ...
- 机器学习(七)—Adaboost 和 梯度提升树GBDT
1.Adaboost算法原理,优缺点: 理论上任何学习器都可以用于Adaboost.但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络.对于决策树,Adaboost分类用了CART分类 ...
- 机器学习之梯度提升决策树GBDT
集成学习总结 简单易学的机器学习算法——梯度提升决策树GBDT GBDT(Gradient Boosting Decision Tree) Boosted Tree:一篇很有见识的文章 https:/ ...
随机推荐
- 关于Mybatis的几件小事(一)
一.Mybatis简介 1.Mybatis简介 MyBatis是支持定制化SQL.存储过程以及高级映射的优秀的持久层框架. MyBatis避免了几乎所有的JDBC代码和手动设置参数以及获取结果集. M ...
- React中,input外边如果包一个div,可以把input的onChange事件绑定到div上面,并且也生效
最近第一次开始学习封装组件,遇到几个比较神奇的问题. 首先就是如果input外边包一个div,如果把input的onChange事件绑定到div上,也会生效 <div onChange={(e) ...
- 简要了解web安全之sql注入
什么是sql注入? 通俗来讲就是通过 将可执行sql语句作为参数 传入查询sql 中,在sql编译过程中 执行了传入进来的恶意 sql,从而 得到 不应该查到或者不应该执行的sql语句,对网站安全,信 ...
- vue项目前端限制页面长时间未操作超时退出到登录页
之前项目超时判断是后台根据token判断的,这样判断需要请求接口才能得到返回结果,这样就出现页面没有接口请求时还可以点击,有接口请求时才会退出 现在需要做到的效果是:页面超过30分钟未操作时,无论点击 ...
- async/await 处理多个网络请求同步问题
1.async/await是基于Promise的,是进一步的一种优化,await会等待异步执行完成 getProjectTask(id){ this.axios.get('/api/v1/task/' ...
- PHP中pdo的使用
<?php /** *下面代码中information为表名 * */ //1.先要连数据库 $pdo=new PDO('mysql:host=localhost;dbname=数据库名','用 ...
- vue 之img的src是动态渲染时(即 :src=' ' )不显示 踩坑
问题: <img :src="item.image ? `../../assets/image/${item.image}` : ''" alt="image&qu ...
- Windows7用VirtualBox虚拟Ubuntu共享文件夹的终极方式
在Win7用VirtualBox虚拟机安装Ubuntu后,共享文件夹再也不用手工mount了 安装增强工具包 设置共享文件夹后 VB已经自动挂载Windows文件夹到 /media/sf_*** 目录 ...
- C和指针--动态内存分配
1.为什么需要使用动态内存分配 数组的元素存储于内存中连续的位置上,当一个数组被声明时,它所需要的内存在编译时就被分配.当你声明数组时,必须用一个编译时常量指定数组的长度.但是,数组的长度常常在运行时 ...
- css优化和重排
转:http://caibaojian.com/css-reflow-repaint.html