hadoop中的JournalNode
1.在HADOOP扮演的角色
JournalNode是在MR2也就是Yarn中新加的,journalNode的作用是存放EditLog的,
在MR1中editlog是和fsimage存放在一起的然后SecondNamenode做定期合并,Yarn在这上面就不用SecondNamanode了.
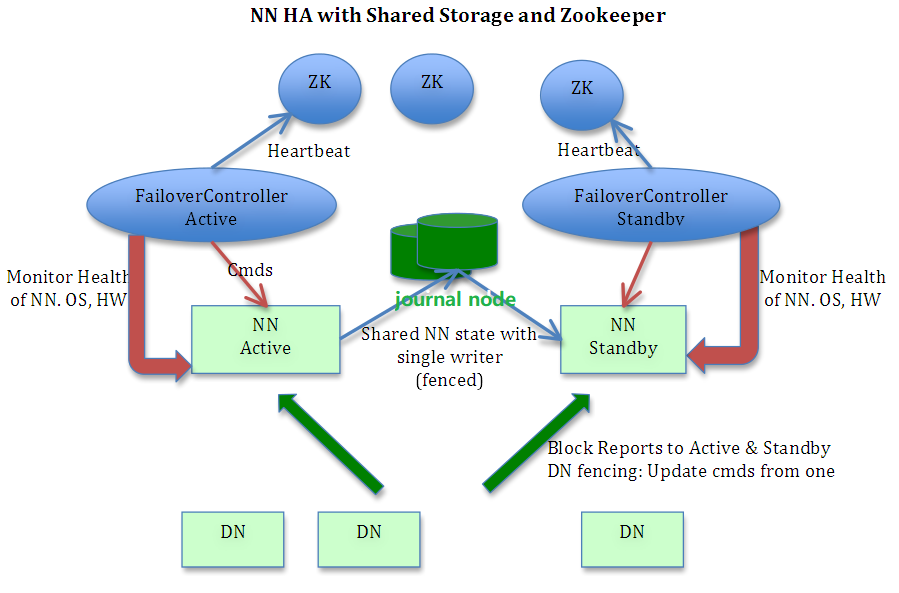
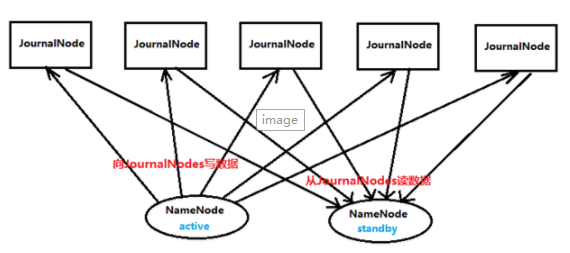
Active Namenode与StandBy Namenode之间的就是JournalNode,作用相当于NFS共享文件系统.Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步.
配置文件是;hdfs-site.xml文件负责

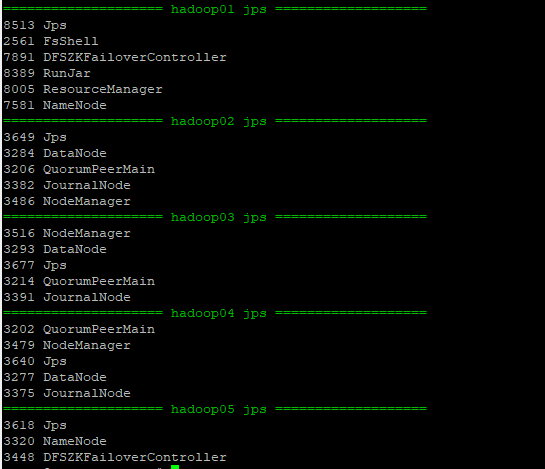
最后进程JPS如下图:
2.作用
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。
standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
3.资源配置
NameNode服务器:运行NameNode的服务器应该有相同的硬件配置。
* JournalNode服务器:运行的JournalNode进程非常轻量,可以部署在其他的服务器上。注意:必须允许至少3个节点。当然可以运行更多,但是必须是奇数个,如3、5、7、9个等等。
当运行N个节点时,系统可以容忍至少(N-1)/2(N至少为3)个节点失败而不影响正常运行。
在HA集群中,standby状态的NameNode可以完成checkpoint操作,因此没必要配置Secondary NameNode、CheckpointNode、BackupNode。如果真的配置了,还会报错。
hadoop中的JournalNode的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- Hadoop中客户端和服务器端的方法调用过程
1.Java动态代理实例 Java 动态代理一个简单的demo:(用以对比Hadoop中的动态代理) Hello接口: public interface Hello { void sayHello(S ...
- [转] - hadoop中使用lzo的压缩
在hadoop中使用lzo的压缩算法可以减小数据的大小和数据的磁盘读写时间,不仅如此,lzo是基于block分块的,这样他就允许数据被分解成chunk,并行的被hadoop处理.这样的特点,就可以让l ...
- Hadoop中WritableComparable 和 comparator
1.WritableComparable 查看HadoopAPI,如图所示: WritableComparable继承自Writable和java.lang.Comparable接口,是一个Writa ...
- hadoop中常见元素的解释
secondarynamenode 图: secondarynamenode根据文件的的大小对namenode的编辑日志和镜像日志 进行合并. 光从字面上来理解,很容易让一些初学者先入为主的认为:Se ...
- Hadoop中常用的InputFormat、OutputFormat(转)
Hadoop中的Map Reduce框架依赖InputFormat提供数据,依赖OutputFormat输出数据,每一个Map Reduce程序都离不开它们.Hadoop提供了一系列InputForm ...
- hadoop中Text类 与 java中String类的区别
hadoop 中 的Text类与java中的String类感觉上用法是相似的,但两者在编码格式和访问方式上还是有些差别的,要说明这个问题,首先得了解几个概念: 字符集: 是一个系统支持的所有抽象字符的 ...
- hadoop 中对Vlong 和 Vint的压缩方法
hadoop 中对java的基本类型进行了writeable的封装,并且所有这些writeable都是继承自WritableComparable的,都是可比较的:并且,它们都有对应的get() 和 s ...
- Hadoop中两表JOIN的处理方法(转)
1. 概述 在传统数据库(如:MYSQL)中,JOIN操作是非常常见且非常耗时的.而在HADOOP中进行JOIN操作,同样常见且耗时,由于Hadoop的独特设计思想,当进行JOIN操作时,有一些特殊的 ...
随机推荐
- 使用Docker Maven 插件进行镜像的创建以及上传至私服
1.在进行服务容器化部署的时候,需要将服务以及其运行的环境整个打包做成一个镜像,打包的过程有两种办法,第一种是首选通过maven打成jar包,然后再编写dockerfile,执行docker buil ...
- SQL 查看某个表被哪些存储过程或者视图使用
--查询某个表被哪些视图/存储过程使用(type='P':表示存储过程,type='V':表示视图) SELECT OBJECT_NAME(id) FROM syscomments WHERE id ...
- 烯烃(olefin) 题解
题面 对于每个点,我们可以用一次dfs求出这个点到以这个点为字树的最远距离和次远距离: 然后用换根法再来一遍dfs求出这个点到除这个点子树之外的最远距离: 显然的,每次的询问我们可以用向上的最大值加向 ...
- HDU - 1045 Fire Net (二分图最大匹配-匈牙利算法)
(点击此处查看原题) 匈牙利算法简介 个人认为这个算法是一种贪心+暴力的算法,对于二分图的两部X和Y,记x为X部一点,y为Y部一点,我们枚举X的每个点x,如果Y部存在匹配的点y并且y没有被其他的x匹配 ...
- linux node 安装
百度搜索出来的按照方式都是下载linux的解压包后,解压出可执行文件然后创建软连接, 我试了一下不知为何node可以创建软连接,但是npm 创建软连接执行不了 还是使用官方的安装方式成功了 https ...
- T100——菜单action控制单身栏位的修改
通过菜单ACTION来控制单身栏位内容的编辑修改: 范例axmt500: DEFINE l_xmdcua012_bk DYNAMIC ARRAY OF RECORD # ljr xmdcua012 L ...
- vue axios拦截跳转
第一步:添加需要拦截的页面 { path: '/control', name: 'Control', meta: { requireAuth: true }, 第二步:页面拦截 router.befo ...
- 在Win10上运行ESXI-Comstomer
在Win10上运行ESXI-Comstomer 来源 https://www.v-front.de/p/esxi-community-packaging-tools.html ESXi-Customi ...
- Oracle update 多字段更新
一次性update多个字段 以student表为例: -- 创建学生表 create table student ( id number, name varchar2(40), age number, ...
- Markdown之基础语法
Markdown是一种纯文本格式的标记语言.通过简单的标记语法,它可以使普通文本内容具有一定的格式 优点: 1.因为是纯文本,所以只要支持Markdown的地方都能获得一样的编辑效果,可以让作者摆脱排 ...