Hadoop-No.5之压缩
Hadoop存储数据时需要着重考虑的一个因素就是压缩.这里不仅要满足节省存储空间的需求,也要提升数据处理性能.在处理大量数据时,消耗最大的是磁盘和网络的I/O,所以减少需要读取或者写入磁盘的数据量就能大大缩短整体处理时间.这包括数据源的压缩,它也包括数据处理过程(如MapReduce任务)中产生的中间数据的压缩.尽管压缩会增加CPU负载,但是大多数情况下,I/O上的节省仍然大于增加的CPU负载
压缩能够极大地优化处理性能,但是Hadoop支持的压缩格式并不都是可以分片的.MapReduce框架先将数据分片,然后在输入多个任务,所以不支持分片的压缩格式对于数据的高效处理极为不利.如果文件不可分片,哪就意味着需要将整个文件输入到一个单独的MapReduce任务,根本无法利用Hadoop提供的大规模并行以及数据本地化优势.因此,在选择压缩格式与文件格式时,是否支持分片是一个重要的考虑因素.
Snappy
Snappy是Google开发的一种压缩编解码器,用于实现高速压缩,适当兼顾压缩率.虽然压缩率不算突出,但是Snappy能够较好的平衡压缩速度和大小.Snappy的处理性能显著优于其他压缩格式.值得注意到是,使用Snappy压缩的文件不是可分片的,所以他要与容器格式(如SequenceFile和Avro)联合使用
LZO
与Snappy类似,LZO也具有较好的压缩速度,单压缩率略显平庸.与Snappy不同的是,使用LZO压缩的文件可分片,不过这里要求建立索引.如果纯文本文件不存储到容器格式中,那么使用LZO是一个不错的选择.有一点需要注意的是,LZO的许可协议不允许将其打包到Hadoop中进行分发,因此需要单独安装.Snappy则不同,它可以与Hadoop一起分发.
Gzip
Gzip的压缩性能非常好,平均来讲,可以达到Snappy的2.5倍.但是他的写入速度不如Snappy,平均为Snappy的一半.在读取性能上.Gzip通常与Snappy相差不.Gzip同样是不可分片的,所以应该与容器格式联合使用呢.请注意,Gzip处理数据有时回避Snappy慢,原因在于Gzip压缩文件需要的数据块较少,所以处理限购他那个数据所需的任务就更少,因此,使用Gzip时选择较小的数据块,可以达到更好的性能.
bzip2
bzip2的压缩性能很优越,但是处理性能明显比其他压缩编解码格式(如Snappy)要差.与Snappy与Gzip不同,bzip2本身为可分片式.通常来说bzip2会比Gzip慢10倍.因此bzip2在Hadoop中并不是理想的编辑阿妈格式,除非主要的需求就是减少存储空间占用量,例如在线归档时使用的Hadoop的场景
压缩算法推荐
一般来说,在与容器文件格式(Avro,SequenceFile等)一起使用时,任何压缩格式都可以是分片式的,因为容器文件格式能够单独压缩记录构成的数据块,也可以进行记录级的压缩.如果在压缩整个文件时没有使用容器文件格式,那么就需要使用本身支持可分片的压缩格式,比如在数据块之间插入同步标记的Bzip2
以下是在Hadoop中进行压缩的一些建议.
- 开启MapReduce中间数据的输出压缩.这样可以减少需要读取和写入磁盘的中间数据,进而提高了性能.
- 注意数据是如何排序的.通常来讲,数据应当排序,相似的数据要放在一起,这样压缩效率更高.
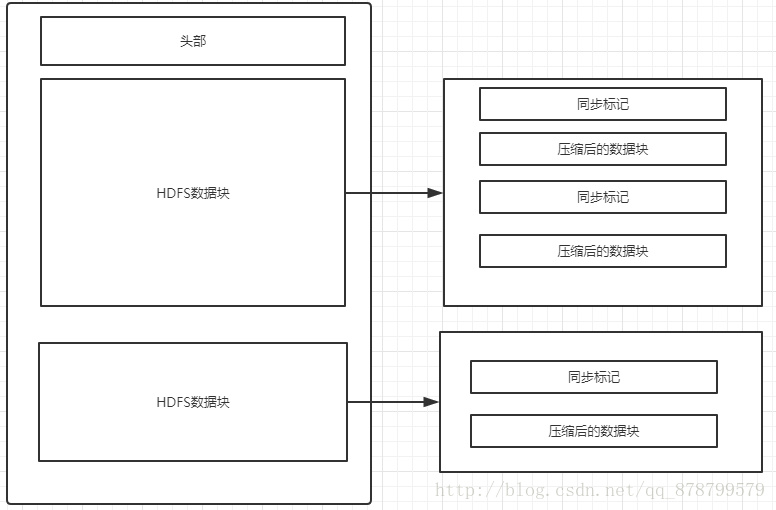
- 考虑使用支持可分片的压缩算法的紧凑文件格式,如Avro.下图展示了使用不可分片压缩算法的Avro或SequenceFile支持文件分片的方法.
Hadoop-No.5之压缩的更多相关文章
- hadoop深入研究:(七)——压缩
转载请标明出处:hadoop深入研究:(七)——压缩 文件压缩主要有两个好处,一是减少了存储文件所占空间,另一个就是为数据传输提速.在hadoop大数据的背景下,这两点尤为重要,那么我现在就先来了解下 ...
- Hadoop基础-SequenceFile的压缩编解码器
Hadoop基础-SequenceFile的压缩编解码器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Hadoop压缩简介 1>.文件压缩的好处 第一:较少存储文件占用 ...
- hadoop中MapReduce中压缩的使用及4种压缩格式的特征的比较
在比较四中压缩方法之前,先来点干的,说一下在MapReduce的job中怎么使用压缩. MapReduce的压缩分为map端输出内容的压缩和reduce端输出的压缩,配置很简单,只要在作业的conf中 ...
- 我是如何利用Hadoop做大规模日志压缩的
背景 刚毕业那几年有幸进入了当时非常热门的某社交网站,在数据平台部从事大数据开发相关的工作.从日志收集.存储.数据仓库建设.数据统计.数据展示都接触了一遍,比较早的赶上了大数据热这波浪潮.虽然今天的人 ...
- Hadoop编码解码【压缩解压缩】机制详解(1)
想想一下,当你需要处理500TB的数据的时候,你最先要做的是存储下来.你是选择源文件存储呢?还是处理压缩再存储?很显然,压缩编码处理是必须的.一段刚刚捕获的60分钟原始视屏可能达到2G,经过压缩处理可 ...
- Hadoop编码解码【压缩解压缩】机制具体解释(1)
想想一下,当你须要处理500TB的数据的时候,你最先要做的是存储下来. 你是选择源文件存储呢?还是处理压缩再存储?非常显然,压缩编码处理是必须的.一段刚刚捕获的60分钟原始视屏可能达到2G,经过压缩处 ...
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
- hive 压缩全解读(hive表存储格式以及外部表直接加载压缩格式数据);HADOOP存储数据压缩方案对比(LZO,gz,ORC)
数据做压缩和解压缩会增加CPU的开销,但可以最大程度的减少文件所需的磁盘空间和网络I/O的开销,所以最好对那些I/O密集型的作业使用数据压缩,cpu密集型,使用压缩反而会降低性能. 而hive中间结果 ...
- Hadoop压缩的图文教程
近期由于Hadoop集群机器硬盘资源紧张,有需求让把 Hadoop 集群上的历史数据进行下压缩,开始从网上查找的都是关于各种压缩机制的对比,很少有关于怎么压缩的教程(我没找到..),再此特记录下本次压 ...
- 查看hadoop压缩方式
bin/hadoop checknative 来查看我们编译之后的hadoop支持的各种压缩,如果出现openssl为false,那么就在线安装一下依赖包 bin/hadoop checknativ ...
随机推荐
- IT管理
IT管理:变更管理:1/ 简单版,效率高类似数仓拉一个相关群,先和业务确定时间,然后在群里发通知.通知模板:@所有人 通知 :hive 计算集群停30分钟 原因: 当前数据量增多,hue 查询内存不足 ...
- 【转帖】Office的光荣历史(2)
Office的光荣历史(2) https://www.sohu.com/a/201411215_657550 2017-10-31 10:57 7.MS Office 2000 (Office 9.0 ...
- Linux系列之putty远程登录
在工作中,我们通常都是通过远程操作Linux服务器的,因此必须熟悉一些远程登录的软件,在此使用的是putty,在Windows上安装putty软件,通过该软件访问Linux主机. 1.远程登录步骤 1 ...
- django F与Q查询 事务 only与defer
F与Q 查询 class Product(models.Model): name = models.CharField(max_length=32) #都是类实例化出来的对象 price = mode ...
- Java反射理解(四)-- 获取成员变量构造函数信息
Java反射理解(四)-- 获取成员变量构造函数信息 步骤 获取成员变量信息: obj.getClass() 获取类类型对象 成员变量也是对象,java.lang.reflect.Field 类中封装 ...
- git的常用指令(一)
1. 查看git远程的所有分支 git branch -a 2.查看本地已有的分支 git branch 3.本地检出一个新的分支并推送到远程仓库 一).创建本地分支 git checkout -b ...
- Java深入分析类与对象
深入分析类与对象 1,成员属性封装 在类之中的组成就是属性与方法,一般而言方法都是对外提供服务的,所以是不会进行封装处理的,而对于属性需要较高的安全性,所以往往需要对其进行保护,这个时候就需要采用封装 ...
- python之数字类型小知识
数字是表示计数的抽象事物,也是数学运算和推理的基础,所以,生活中数字是生活中无处不在的,那么,在python语言中运用数字有哪些小知识呢,不妨花点时间看一下这篇博文,牢记这些小知识. 整数类型中四种进 ...
- JavaScript中with不推荐使用,为什么总是出现在面试题中?
with的基本使用 尴尬的with关键字 一.with的基本使用 with是用来扩展语句作用域的,什么意思呢?先来看看语法和示例: 语法: with(expression){ statement } ...
- javascript是一种安全语言
一.简单JavaScript是一个基于Java基本语句和控制流的简单而紧凑的设计,这是学习Java的一个很好的过渡.它的变量类型是弱类型,而不是严格的数据类型.二.力学JavaScript是动态的,可 ...