langchain0.3教程:从0到1打造一个智能聊天机器人
在上一篇文章《大模型开发之langchain0.3(一):入门篇》 中已经介绍了langchain开发框架的搭建,最后使用langchain实现了HelloWorld的代码案例,本篇文章将从0到1搭建带有记忆功能的聊天机器人。
一、gradio
我们可以使用gradio“画”出类似于chatgpt官网的聊天界面,gradio的特点就是“快”,不用考虑html怎么写,css样式怎么写,该怎样处理按钮的响应。。这一切都被gradio处理完了,我们只需要使用即可。
gradio官网:https://www.gradio.app/
官网首页上列举了几种典型的gradio使用场景,其中一种正是我们想要的chatbot的使用场景:
找到左下方对应的源码链接,复制到我们的项目:
import time
import gradio as gr
# 生成器函数,用于模拟流式输出
def slow_echo(message, history):
for i in range(len(message)):
time.sleep(0.05)
yield "You typed: " + message[: i + 1]
demo = gr.ChatInterface(
slow_echo,
type="messages",
flagging_mode="manual",
flagging_options=["Like", "Spam", "Inappropriate", "Other"],
save_history=True,
)
if __name__ == "__main__":
demo.launch()
我们安装好最新版本的gradio就可以成功运行以上代码了:
pip install gradio==5.23.1
二、聊天机器人实现
根据上一节内容,将大模型的输出给到gradio即可,完整实现代码如下:
import gradio as gr
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-4o", model_provider="openai")
def do_response(message, history):
resp = model.invoke(message)
return resp.content
demo = gr.ChatInterface(
do_response,
type="messages",
flagging_mode="manual",
flagging_options=["Like", "Spam", "Inappropriate", "Other"],
save_history=True,
)
if __name__ == "__main__":
demo.launch()
代码运行结果如下所示:
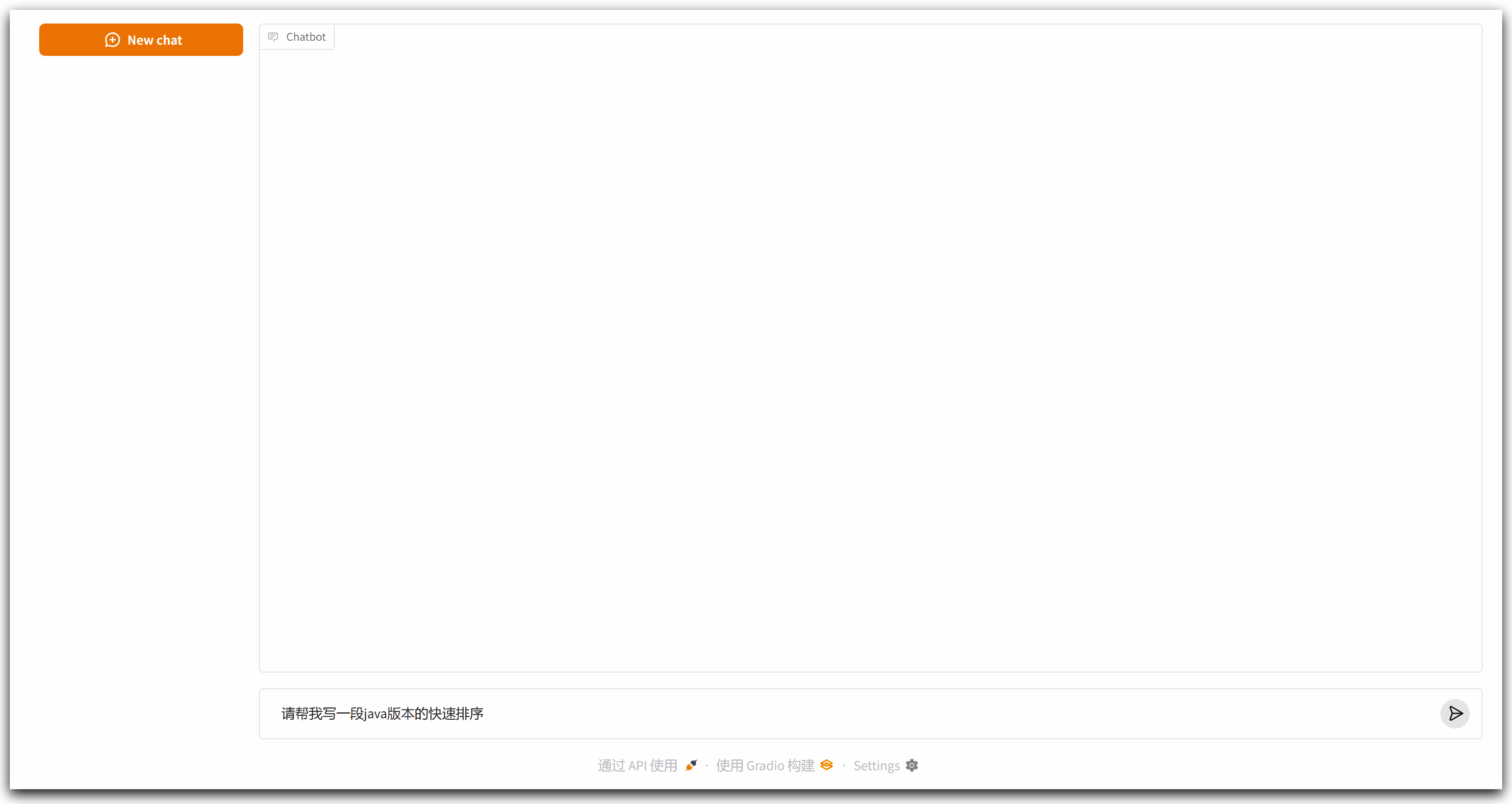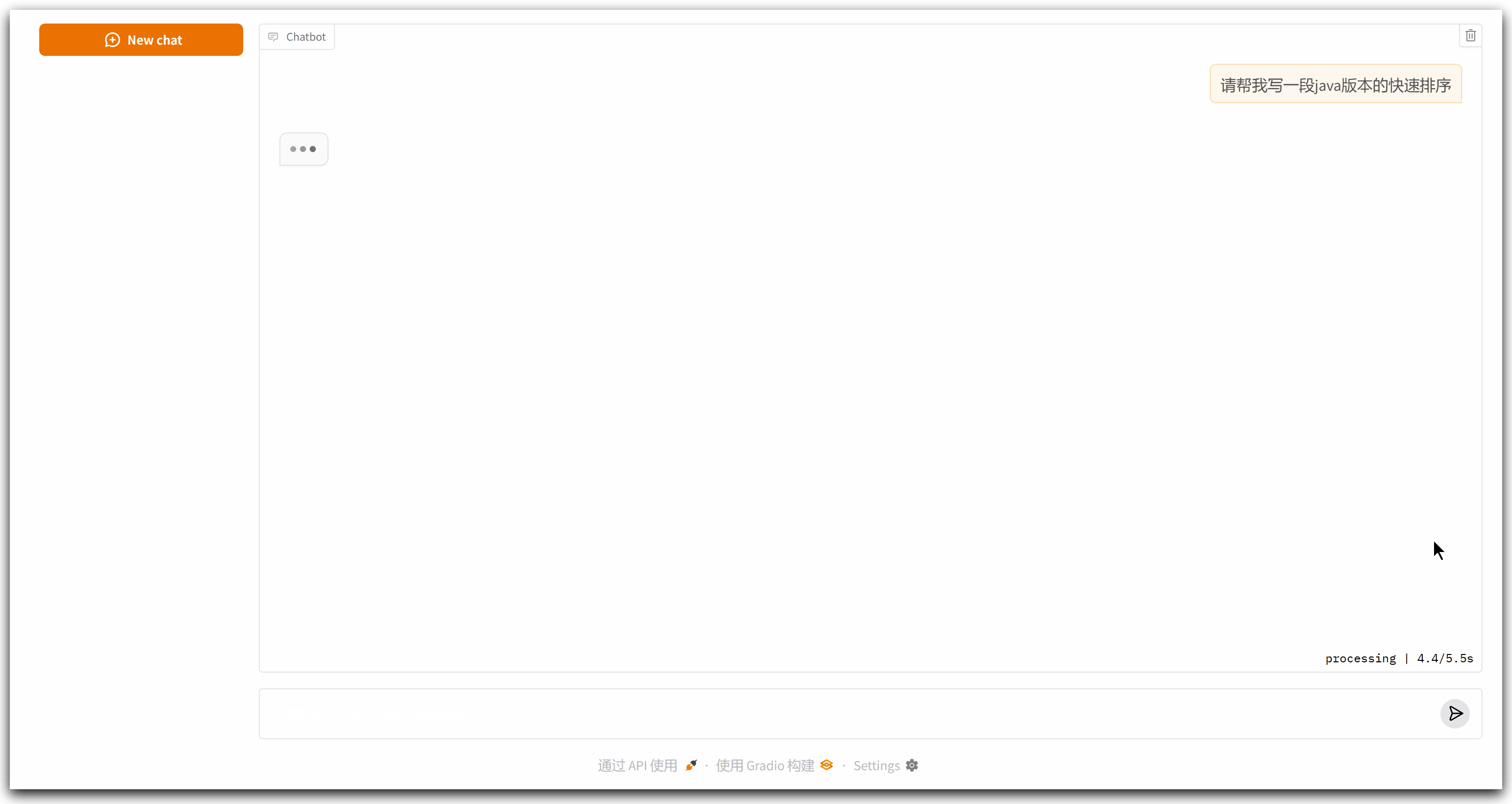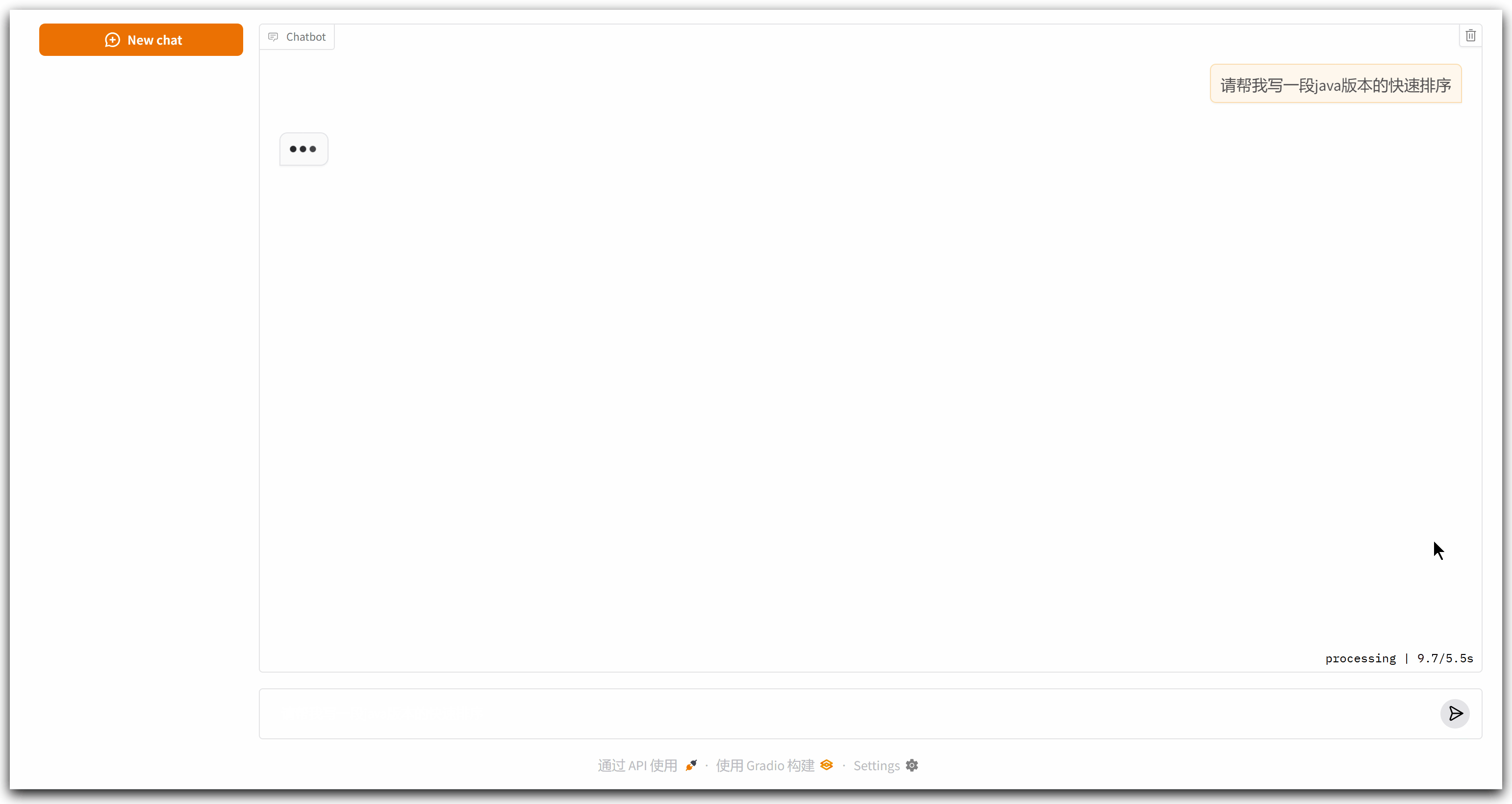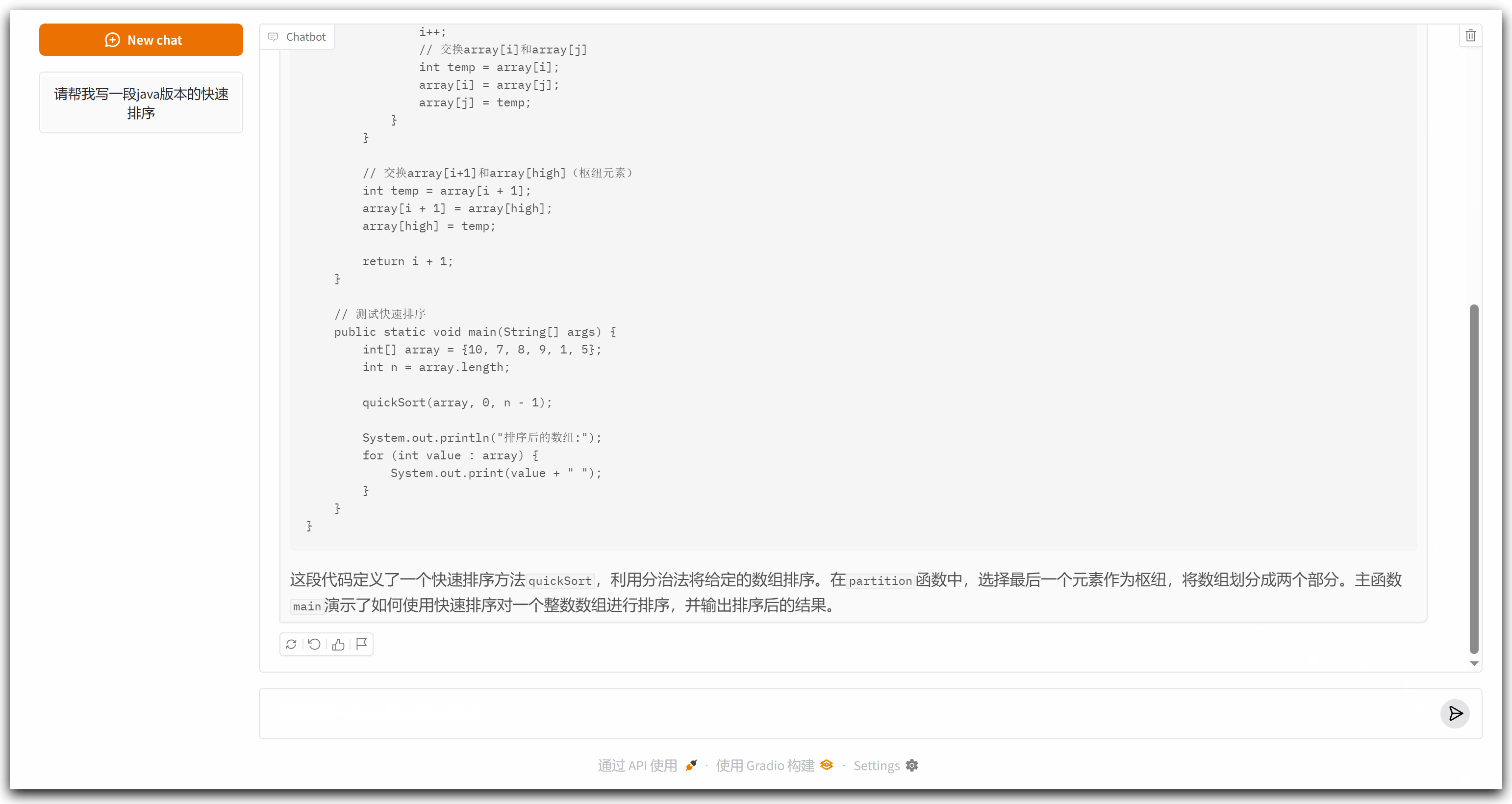
可以看到,响应时间比较长,足足有十秒钟,在这期间看不到中间的过程,只在最后一次性输出了最终内容,对于用户来说很不友好。
接下来将它改造成流式输出。
优化一:流式输出
想要改造流式输出,首先得大模型支持流式输出,再者改造gradio,让它支持流式输出显示。
关于模型的流式输出文档:https://python.langchain.com/docs/how_to/streaming_llm/
关于gradio的流式输出显示文档:https://www.gradio.app/guides/creating-a-chatbot-fast#streaming-chatbots
简单来说,gradio的流式输出很简单,将do_response方法改造成生成器函数即可
import time
import gradio as gr
def slow_echo(message, history):
for i in range(len(message)):
time.sleep(0.3)
yield "You typed: " + message[: i+1]
gr.ChatInterface(
fn=slow_echo,
type="messages"
).launch()
而stream方法支持流式输出,使用示例如下所示:
from langchain_openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-instruct", temperature=0, max_tokens=512)
for chunk in llm.stream("Write me a 1 verse song about sparkling water."):
print(chunk, end="|", flush=True)
两者结合起来,改造后的流式输出代码如下所示:
import gradio as gr
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-4o", model_provider="openai")
def response(message, history):
resp = ""
for chunk in model.stream(message):
resp = resp + chunk.content
yield resp
demo = gr.ChatInterface(
fn=response,
type="messages",
flagging_mode="manual",
flagging_options=["Like", "Spam", "Inappropriate", "Other"],
save_history=True,
)
if __name__ == '__main__':
demo.launch()
运行结果:
这样就实现了流式输出。
但是这个程序还有问题:它没有记忆功能,如下所示
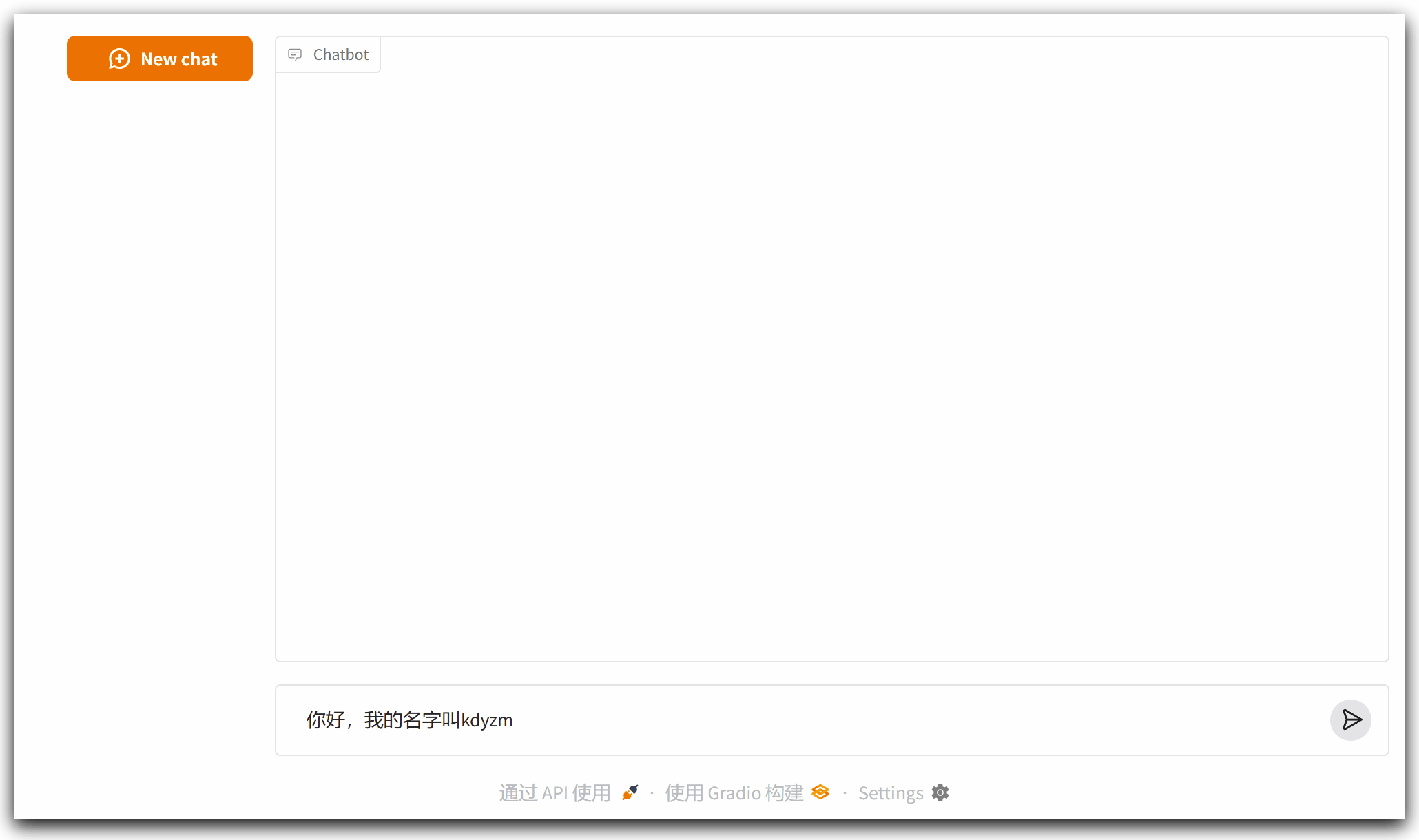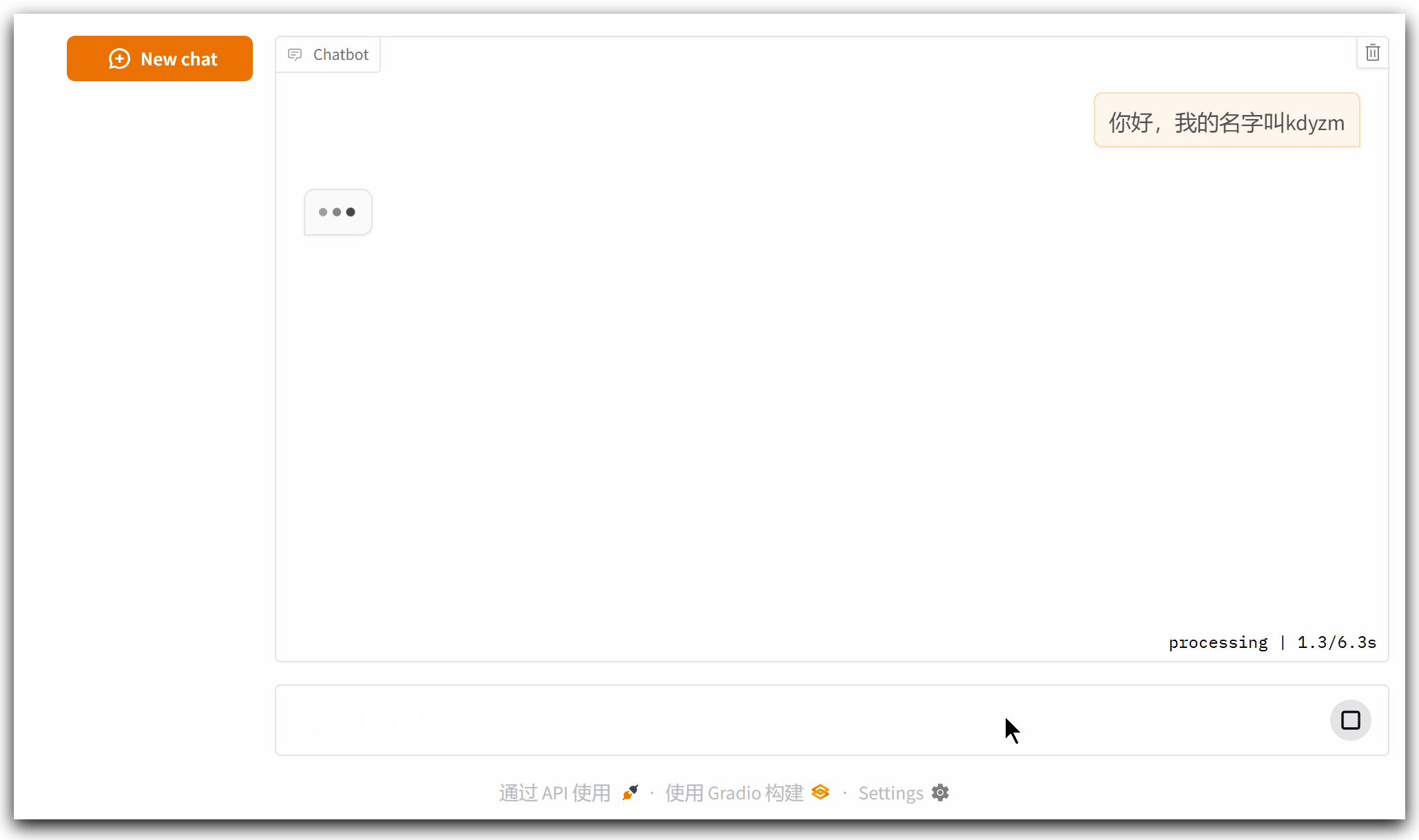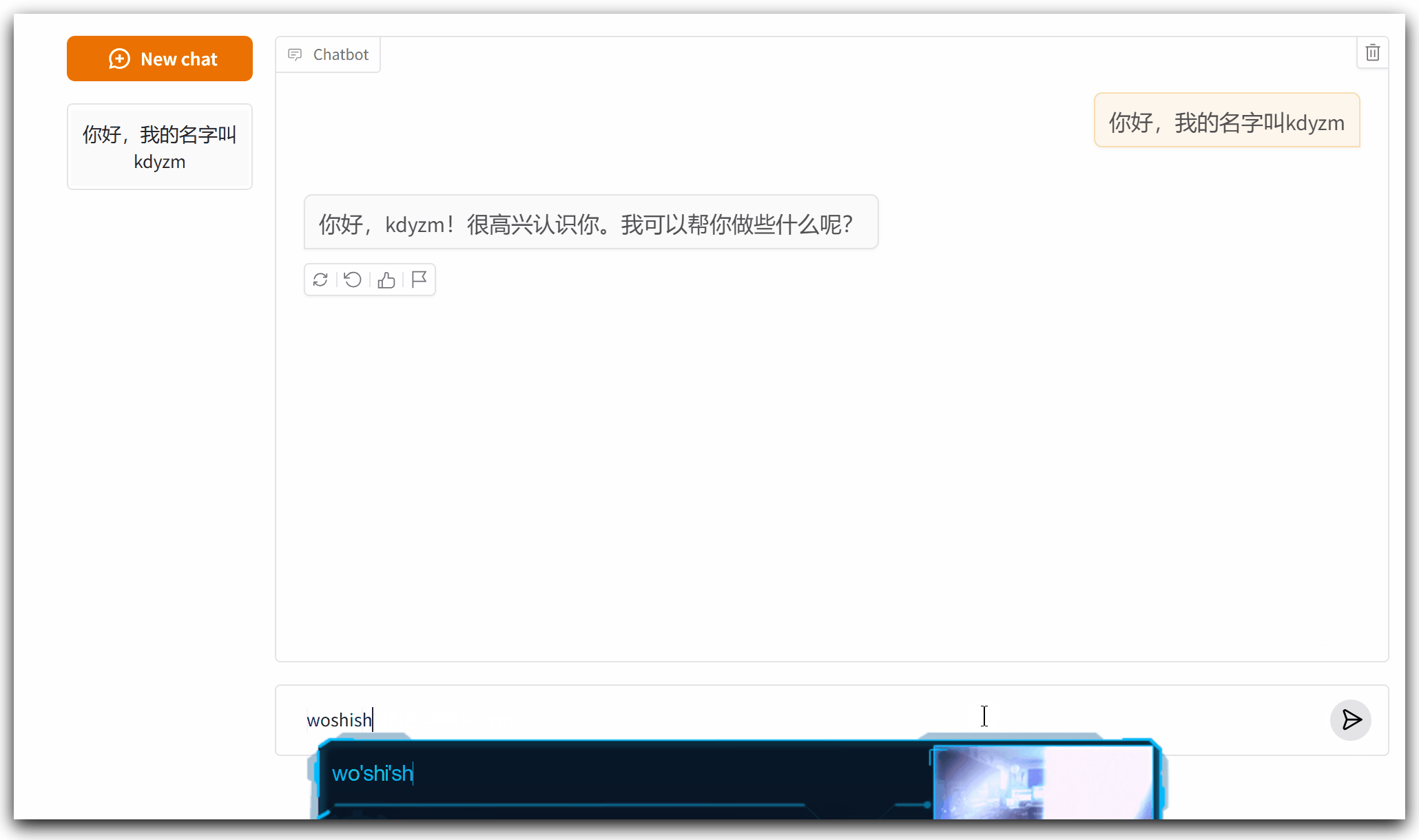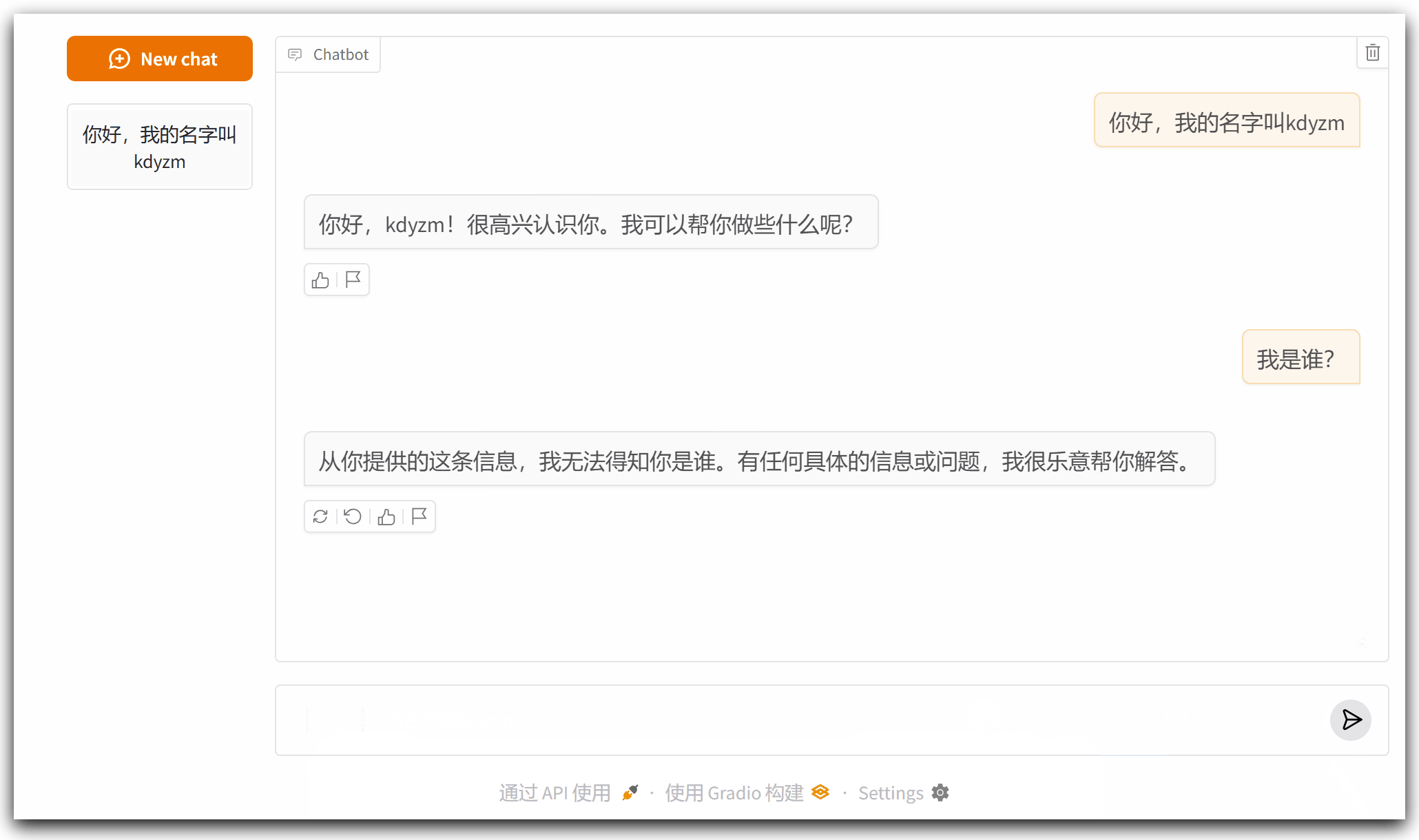
接下来对它继续优化,加上记忆功能
优化二:上下文记忆功能
在改造之前,需要先了解几个概念:Chat history、Messages
大模型之所以有记忆功能,是因为每次和大模型对话,都会将历史记录一起送给大模型。
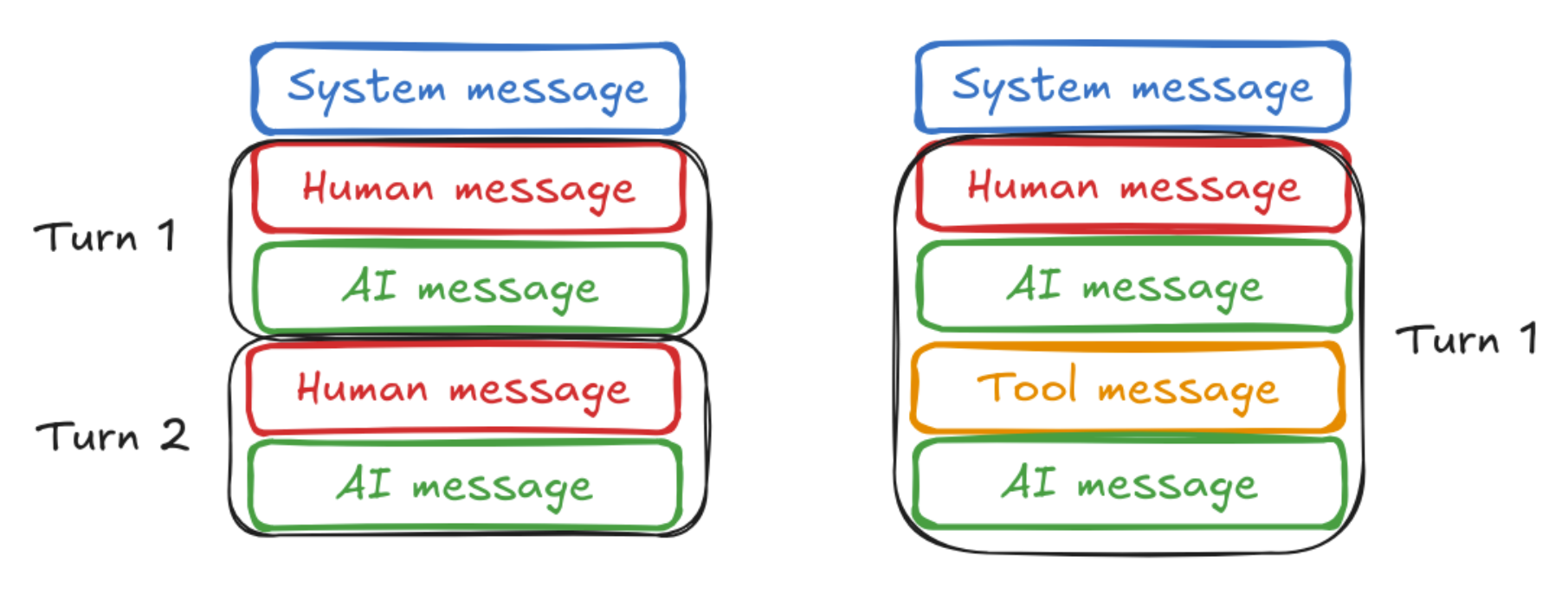
和大模型的交互的过程中,最常见的有三种消息类型:System Message、Human Message、AI Message。
| 消息类型 | 释义 |
|---|---|
| System Message | 就是开始对话之前对大模型的引导信息,比如“你是一个智能助手,回答用户信息请使用中文”,这样让大模型“扮演”某种角色。 |
| Human Message | 我们提出的问题 |
| AI Message | 大模型响应的问题。 |
这三种消息被langchain封装成了不同的类以方便使用:SystemMessage、HumanMessage、AIMessage
那如何将对话历史记录告诉大模型呢?
答案在于model.stream方法,stream默认我们只传输了一个字符串,也就是用户的提问消息,实际上它的类型是LanguageModelInput
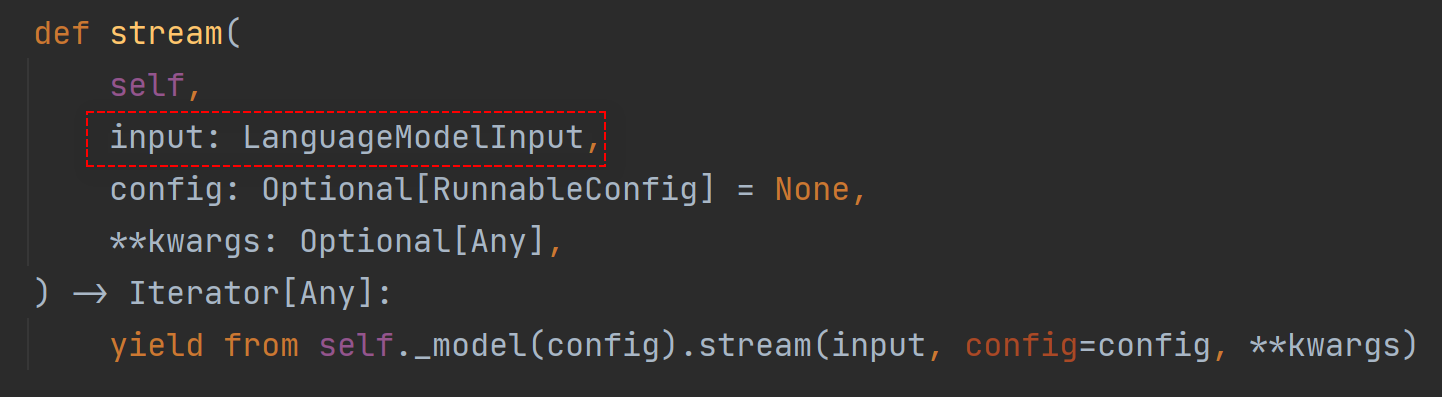
LanguageModelInput的定义如下

Union的意思就是“选择其中之一”的意思,也就是说LanguageModelInput可以是PromptValue、字符串,或者Sequence[MessageLikeRepresentation]任意之一,关键点就在于Sequence[MessageLikeRepresentation],从字面意思上来看它是一个列表类的对象,MessageLikeRepresentation的定义如下,它支持BaseMessage类型

也就是说,可以传递一个BaseMessage类型的List给stream方法,而SystemMessage、HumanMessage、AIMessage 均是BaseMessage的子类。。。一切清晰明了了,可以用一行代码实现gradio历史记录到BaseMessage列表的转换:
h = [HumanMessage(i["content"]) if i["role"] == 'user' else AIMessage(i["content"]) for i in history]
优化后的完整代码如下所示:
import gradio as gr
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, AIMessage
model = init_chat_model("gpt-4o", model_provider="openai")
def response(message, history):
h = [HumanMessage(i["content"]) if i["role"] == 'user' else AIMessage(i["content"]) for i in history]
h.append(HumanMessage(message))
resp = ""
for chunk in model.stream(h):
resp = resp + chunk.content
yield resp
demo = gr.ChatInterface(
fn=response,
type="messages",
flagging_mode="manual",
flagging_options=["Like", "Spam", "Inappropriate", "Other"],
save_history=True,
)
if __name__ == '__main__':
demo.launch()
运行结果如下:
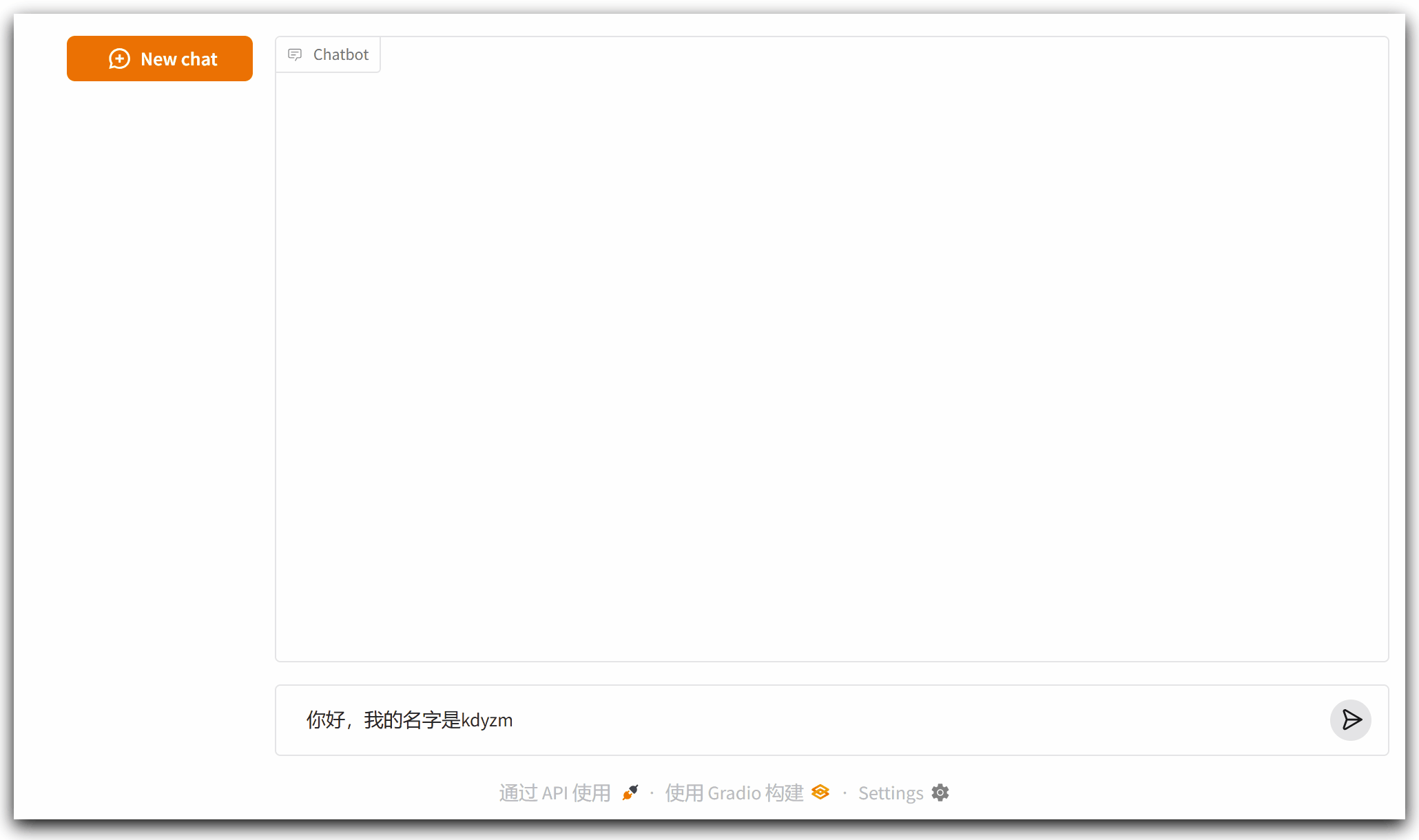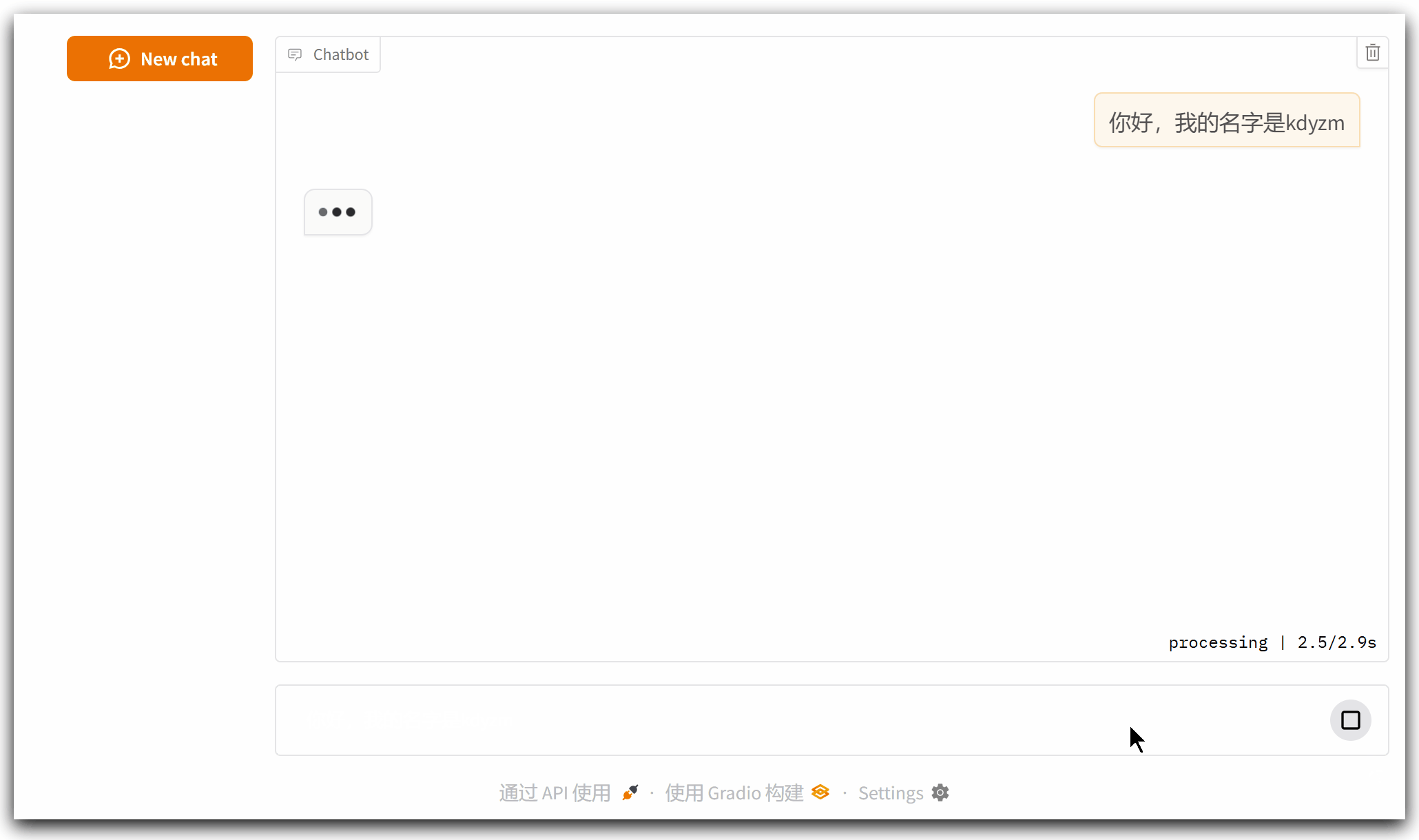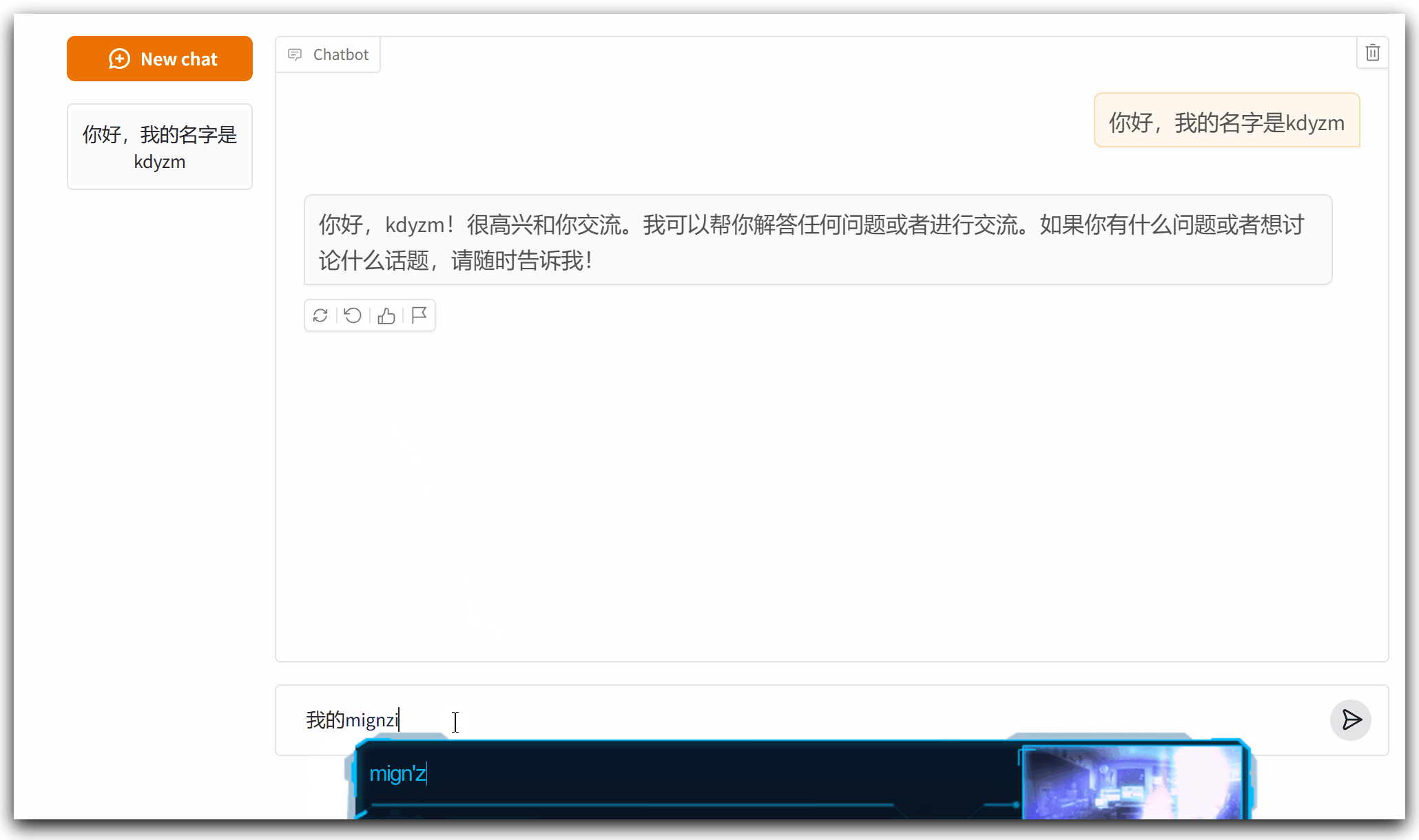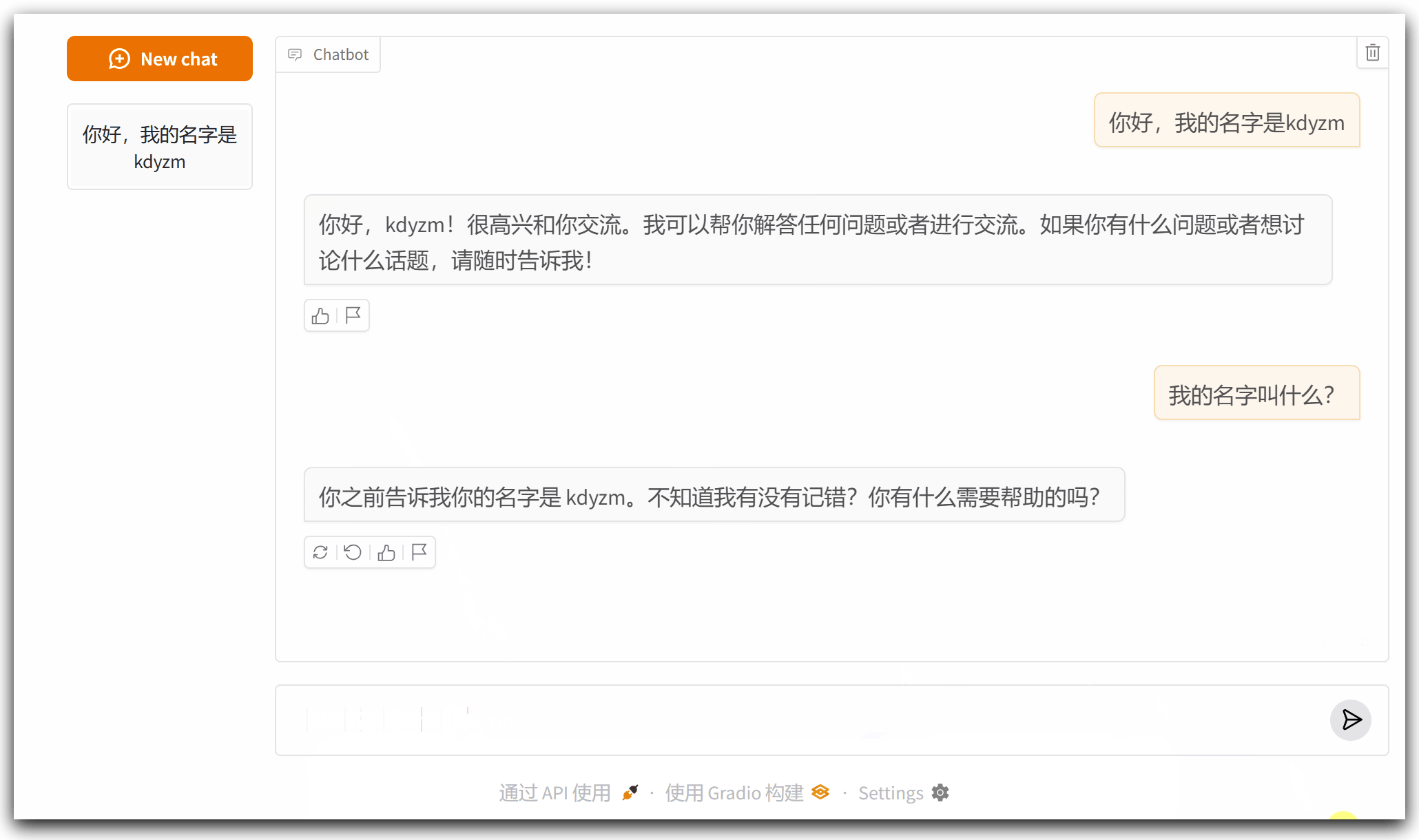
好了,到此,我们用了不到30行代码实现了一个基本的智能聊天机器人,这个程序还有什么问题需要注意的吗?我们思考一下,每次和大模型交互,都要将所有历史记录传递给大模型,这行的通吗?实际上每种大模型都有输入长度的限制,如果不加以限制的话,会很容易超出大模型能够输入字符的上限,接下来改造下这段代码,限制输入的字符数量。
优化三:限制输入长度
关于输入长度过长的优化,实际上是一个比较复杂的问题,可以参考以下官方文档:
Context Window的概念:https://python.langchain.com/docs/concepts/chat_models/#context-window
Memory的概念:https://langchain-ai.github.io/langgraph/concepts/memory/
trim_message的详细用法:https://python.langchain.com/docs/how_to/trim_messages/
trim_message在chatbot中的应用案例:https://python.langchain.com/docs/tutorials/chatbot/#managing-conversation-history
总结一下,用户能输入的字符长度实际上是大模型能“记住”的文本长度,如果过长,就会达到"Context Window"的极限,大模型要么删除一部分文本继续处理,要么直接抛出异常,前者会导致处理数据结果不准确,后者则会导致应用程序直接报错。
可以使用trim_message方法解决该问题,它有各种策略截取过长的输入文本,甚至可以自定义策略。比如以下使用方式:
from langchain_core.messages import trim_messages
trimmer = trim_messages(
max_tokens=300,
strategy="last",
token_counter=model,
include_system=True,
allow_partial=False,
start_on="human",
)
该案例中制定的策略是只允许输入最大300个字符,超出的字符从尾部向前查找删除,而且不允许对消息部分删除(保留问题完整性)。
完整代码如下所示:
from langchain.chat_models import init_chat_model
import gradio as gr
from langchain_core.messages import HumanMessage, AIMessage, trim_messages
model = init_chat_model("gpt-4o", model_provider="openai")
trimmer = trim_messages(
max_tokens=300,
strategy="last",
token_counter=model,
include_system=True,
allow_partial=False,
start_on="human",
)
def response(message, history):
h = [HumanMessage(i["content"]) if i["role"] == 'user' else AIMessage(i["content"]) for i in history]
h.append(HumanMessage(message))
result = trimmer.invoke(h)
//查看trim结果
print(result)
resp = ""
for chunk in model.stream(result):
resp = resp + chunk.content
yield resp
demo = gr.ChatInterface(
fn=response,
type="messages",
flagging_mode="manual",
flagging_options=["Like", "Spam", "Inappropriate", "Other"],
save_history=True,
)
if __name__ == '__main__':
demo.launch()
运行结果如下:
后台打印的被优化的消息:
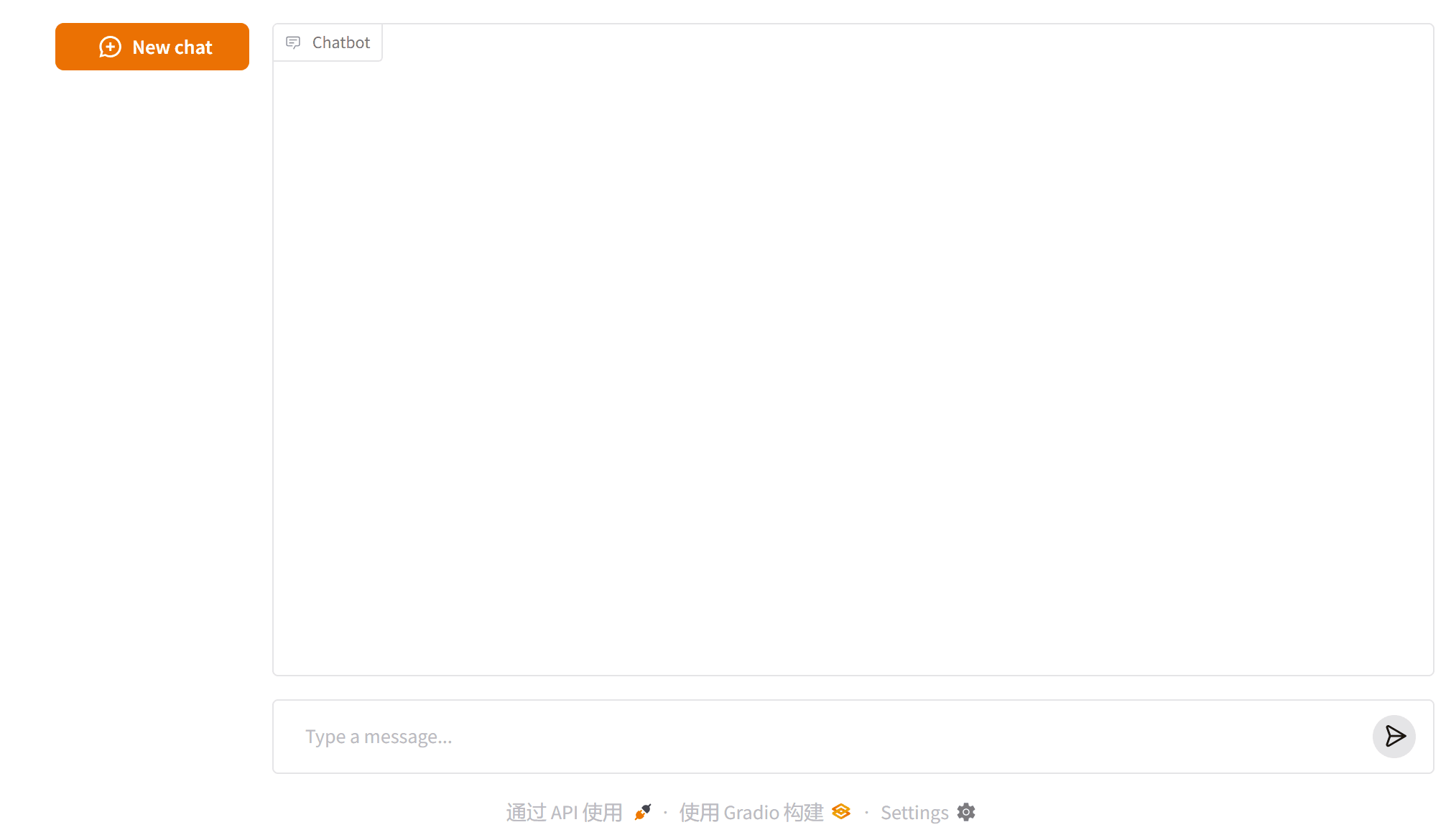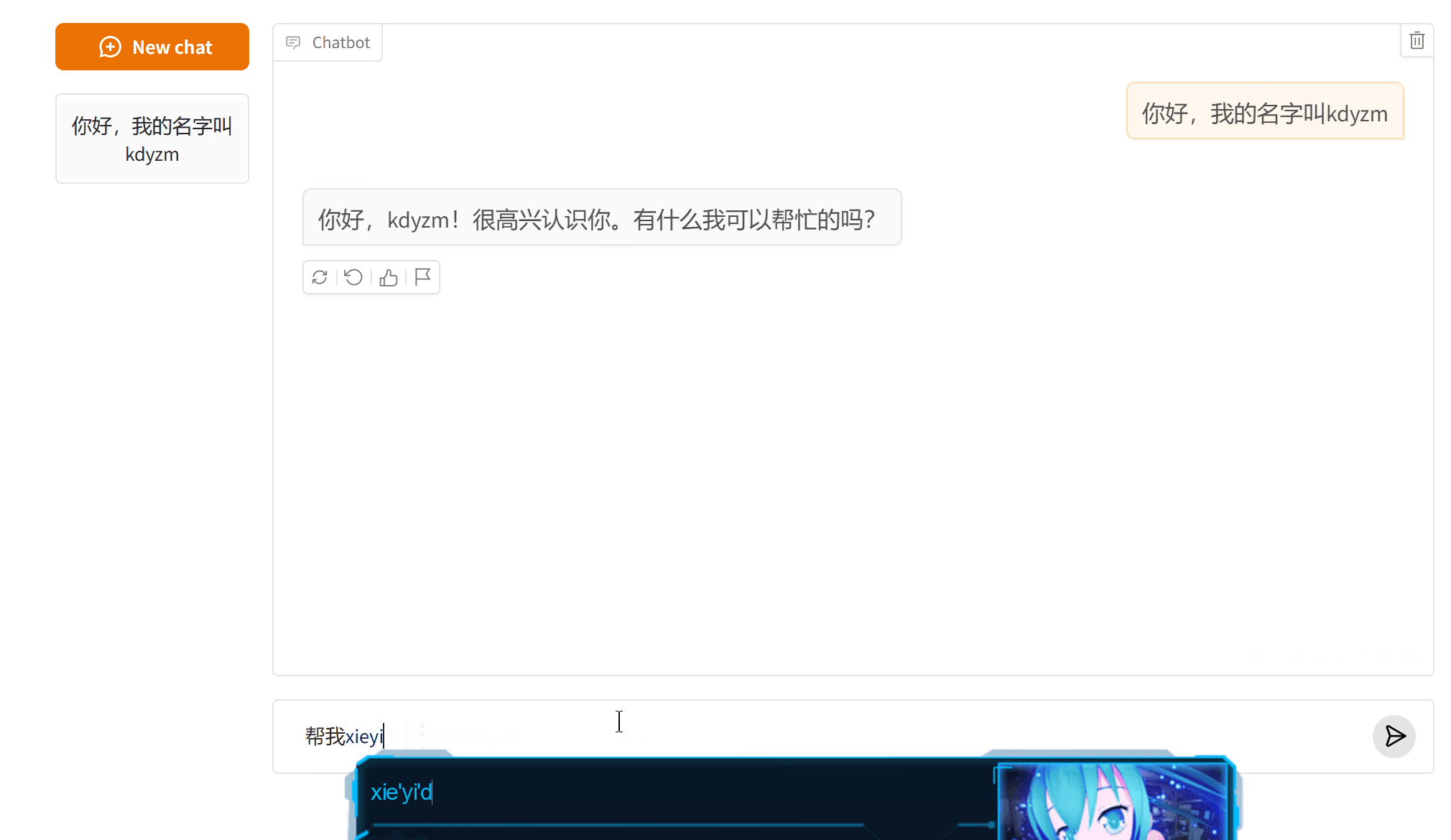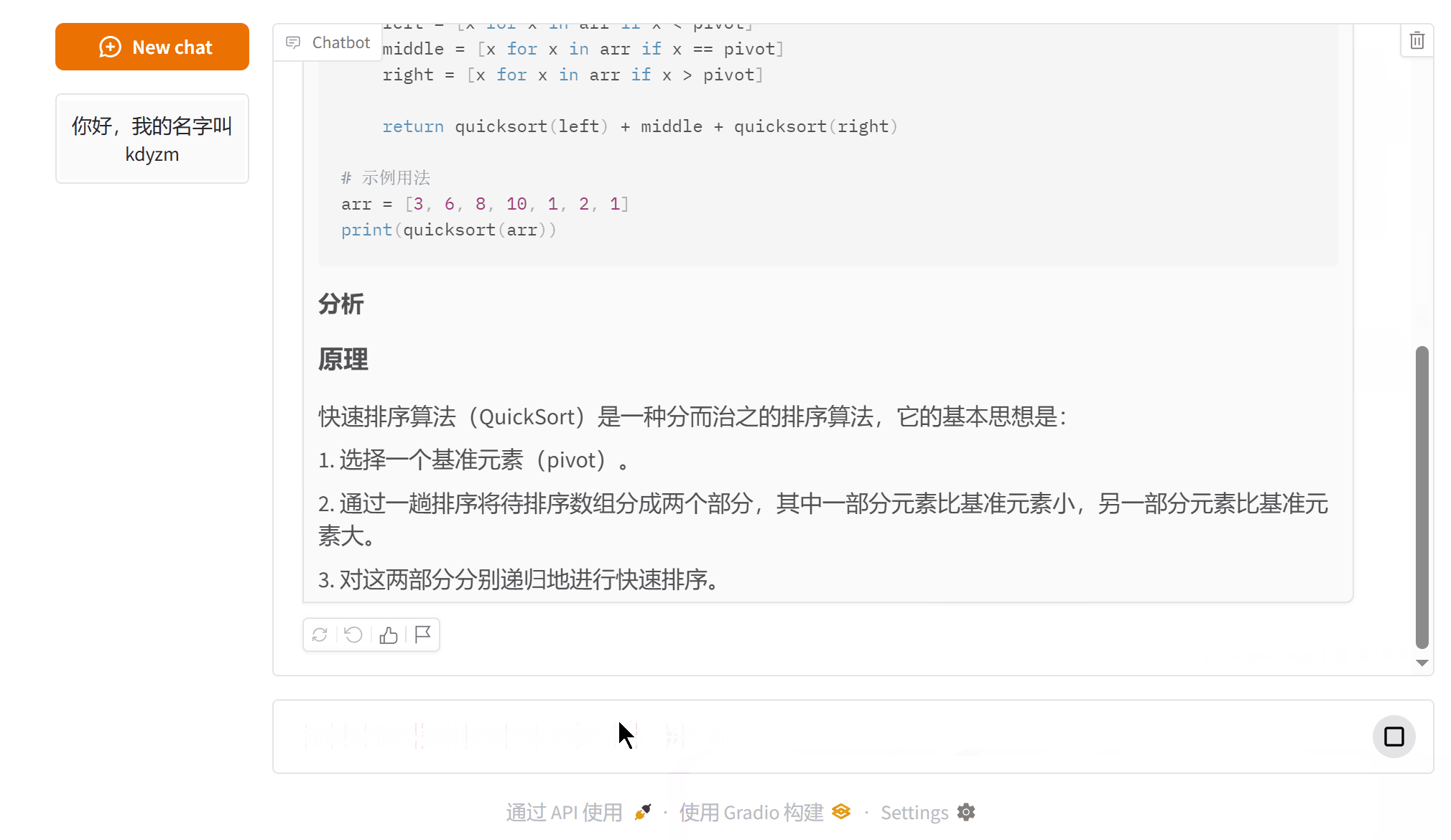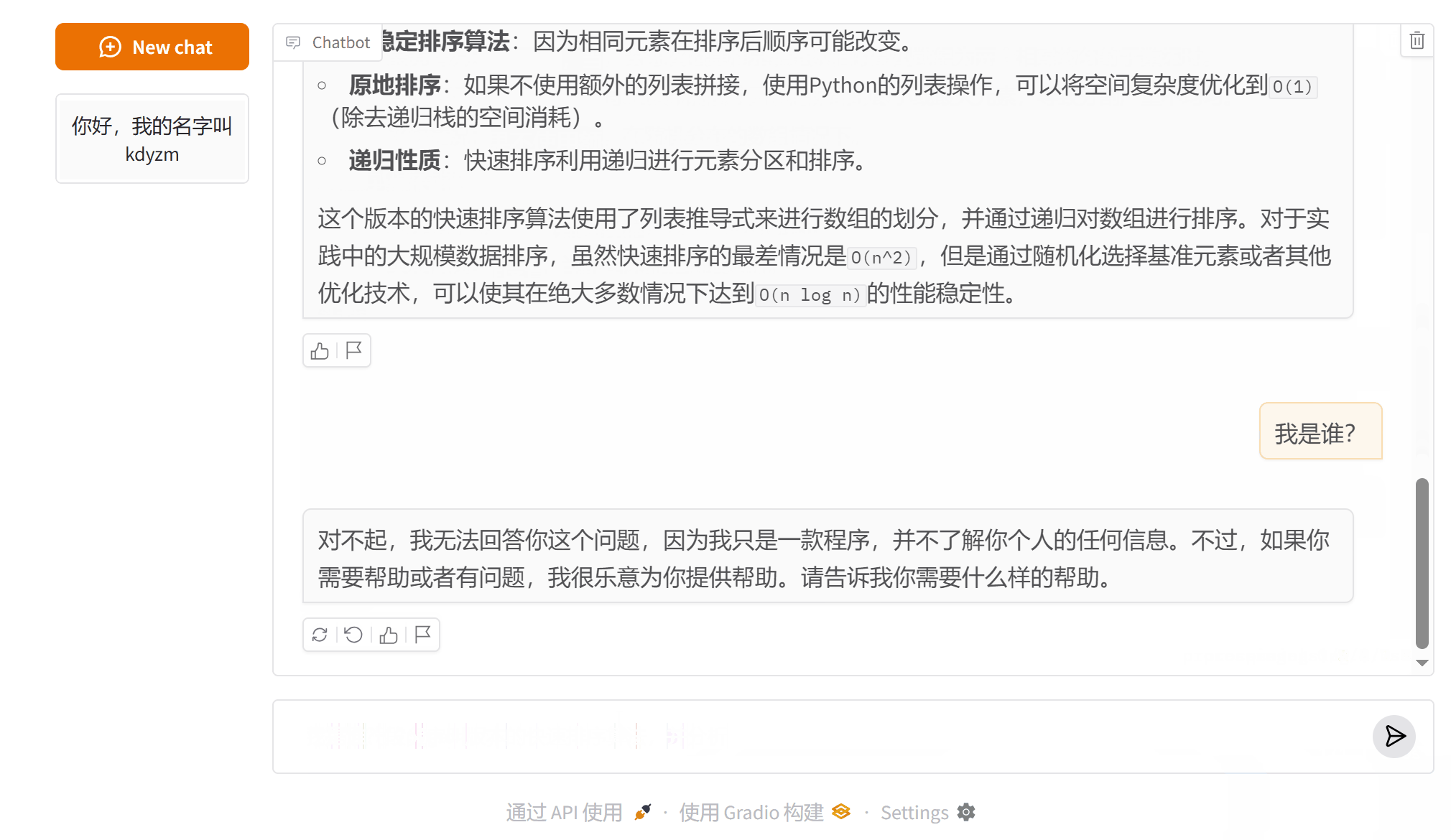
[HumanMessage(content='你好,我的名字叫kdyzm', additional_kwargs={}, response_metadata={})]
[HumanMessage(content='你好,我的名字叫kdyzm', additional_kwargs={}, response_metadata={}), AIMessage(content='你好,kdyzm!很高兴认识你。有什么我可以帮忙的吗?', additional_kwargs={}, response_metadata={}), HumanMessage(content='帮我写一段python版本的快速排序算法,并分析', additional_kwargs={}, response_metadata={})]
[HumanMessage(content='我是谁?', additional_kwargs={}, response_metadata={})]
可以看到,第三次询问的时候,之前的消息就被删除,不再发送给大模型,这导致大模型忘记了我之前告诉它的我的名字。
最后,欢迎关注我的博客呀:
END.
langchain0.3教程:从0到1打造一个智能聊天机器人的更多相关文章
- 全网最详细中英文ChatGPT-GPT-4示例文档-智能聊天机器人从0到1快速入门——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)
目录 Introduce 简介 setting 设置 Prompt 提示 Sample response 回复样本 API request 接口请求 python接口请求示例 node.js接口请求示 ...
- AI 影评家:用 Hugging Face 模型打造一个电影评分机器人
本文为社区成员 Jun Chen 为 百姓 AI 和 Hugging Face 联合举办的黑客松所撰写的教程文档,欢迎你阅读今天的第二条推送了解和参加本次黑客松活动.文内含有较多链接,我们不再一一贴出 ...
- FastAPI(56)- 使用 Websocket 打造一个迷你聊天室
背景 在实际项目中,可能会通过前端框架使用 WebSocket 和后端进行通信 这里就来详细讲解下 FastAPI 是如何操作 WebSocket 的 模拟 WebSocket 客户端 #!usr/b ...
- 人工智能不过尔尔,基于Python3深度学习库Keras/TensorFlow打造属于自己的聊天机器人(ChatRobot)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_178 聊天机器人(ChatRobot)的概念我们并不陌生,也许你曾经在百无聊赖之下和Siri打情骂俏过,亦或是闲暇之余与小爱同学谈 ...
- ArcGIS Runtime for Android开发教程V2.0(1)基本概念
原文地址: ArcGIS Runtime for Android开发教程V2.0(1)基本概念 - ArcGIS_Mobile的专栏 - 博客频道 - CSDN.NET http://blog.csd ...
- [教程]phpwind9.0应用开发基础教程
这篇文章着重于介绍在9.0中如何开发一个插件应用的示例,step by step来了解下在9.0中一个基础的应用包是如何开发的.1.目录结构OK,首先是目录结构,下面是一个应用我们推荐的目录. 应用包 ...
- ArcGIS Runtime for Android开发教程V2.0(4)基础篇---MapView
原文地址: ArcGIS Runtime for Android开发教程V2.0(4)基础篇---MapView - ArcGIS_Mobile的专栏 - 博客频道 - CSDN.NET http:/ ...
- ArcGIS Runtime for Android开发教程V2.0(3)基础篇---Hello World Map
原文地址: ArcGIS Runtime for Android开发教程V2.0(3)基础篇---Hello World Map - ArcGIS_Mobile的专栏 - 博客频道 - CSDN.NE ...
- ArcGIS Runtime for Android开发教程V2.0(2)开发环境配置
原文地址: ArcGIS Runtime for Android开发教程V2.0(2)开发环境配置 - ArcGIS_Mobile的专栏 - 博客频道 - CSDN.NET http://blog.c ...
- 《Ruby语言入门教程v1.0》学习笔记-01
<Ruby语言入门教程v1.0> 编著:张开川 邮箱:kaichuan_zhang@126.com 想要学习ruby是因为公司的自动化测试使用到了ruby语言,但是公司关于ruby只给了一 ...
随机推荐
- PaperAssistant:使用Microsoft.Extensions.AI实现
前言 上篇文章介绍了使用Semantic Kernel Chat Completion Agent实现的版本. 使用C#构建一个论文总结AI Agent 今天来介绍一下使用Microsoft.Exte ...
- 为了解决服务启动慢的问题,我为什么要给Apollo和Spring提交PR?
最近在整理之前记录的工作笔记时,看到之前给团队内一组服务优化启动耗时记录的笔记,简单整理了一下分享出来.问题原因并不复杂,主要是如何精准测量和分析,优化后如何定量测量优化效果,说人话就是用实际数据证明 ...
- MySQL架构体系-SQL查询执行全过程解析
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来 ...
- 深入浅出:Agent如何调用工具——从OpenAI Function Call到CrewAI框架
深入浅出:Agent如何调用工具--从OpenAI Function Call到CrewAI框架 嗨,大家好!作为一个喜欢折腾AI新技术的算法攻城狮,最近又学习了一些Agent工作流调用工具的文章,学 ...
- ctfshow--web7 sql注入空格过滤
?id=10//union//select//1,database(),3//%23查看库名 查看表名 -1/**/union/**/select/**/1,(select/**/group_conc ...
- 一文搞懂 结构伪类 :nth-child && :nth-of-typ
结构伪类 从使用结构伪类的选择器开始 往上一层父辈开始筛选 从使用结构伪类的选择器开始 往上一层父辈开始筛选 从使用结构伪类的选择器开始 往上一层父辈开始筛选 不是从左往右选择 不是先父辈后筛选子类 ...
- mysql异常处理的收集
今天在处理mysql的存储过程,判断游标是否到了结尾,结果让返回零行的一个查询触发了,随即从网上查阅资料收集异常异常处理. MySql错误处理(一)- SQL服务器模式 导言:MySql错误处理的基础 ...
- 微信小程序音频播放
微信小程序音频播放 // 开启播放音频 startAudio(){ const innerAudioContext = uni.createInnerAudioContext();//创建并返回内部 ...
- 如何让JS代码变的安全?
本文分享自天翼云开发者社区<如何让JS代码变的安全?>,作者:温****双 前端JS代码,直接暴露在浏览器中,任何访问者,都可以随意查看代码.这就导致代码可以被分析.复制.盗用等,进而引发 ...
- SqlServer中根据某几列获取重复的数据将其删除并保留最新一条
有时候,我们某个数据表中,可能有几列的数据都是一样的,此时我们可能想查询出这几列数据相同的所有数据行,并保留最新一条,将其他重复的数据删除. 1.ROW_NUMBER函数 假设我们有如下数据表: 此时 ...