RAGflow搭建text-to-sql的AI研发助手
一、概述
text-to-sql 技术允许用户通过自然语言提问,系统自动将其转换为 SQL 语句并执行,大大降低了数据查询的门槛,提高了工作效率。
text-to-sql 技术在数据分析、智能客服、数据可视化等领域都有着广泛的应用前景。例如,在企业的日常运营中,业务人员可以直接通过自然语言询问 “上个月各地区的销售额是多少”,而无需关心复杂的数据库表结构和 SQL 语法,就能快速获取所需数据。
text-to-sql 方案往往依赖大模型微调,这对于中小企业来说,不仅需要投入大量的时间和计算资源,还面临着数据隐私和安全等问题,应用成本极高。那么,有没有一种更简单、高效的方法来搭建 text-to-sql 系统呢?答案就是使用 RAGflow。
text-to-sql 的实现原理
text-to-sql 的核心是将自然语言转换为 SQL 语句,这一过程涉及多个关键步骤。首先是自然语言理解,需要运用词法分析、句法分析和语义分析等多种自然语言处理(NLP)技术。词法分析将输入的文本分割成一个个单词或标记(token),并标注每个标记的词性。对于句子 “查询销售额大于 100 万的订单信息”,词法分析会把它分割为 “查询”“销售额”“大于”“100 万”“的”“订单”“信息” 等标记,并明确每个标记的词性。句法分析则是分析句子的语法结构,确定各个成分之间的关系,比如通过依存句法分析或成分句法分析构建出句子的语法树,帮助理解句子语义。语义分析是理解句子的实际含义,将自然语言表达的语义映射到数据库的概念和操作上,像识别出 “查询” 表示执行查询操作,“销售额大于 100 万” 表示筛选条件。
在理解自然语言文本的语义后,就要进行模式匹配与映射,即将自然语言中的语义与数据库的模式进行匹配。数据库模式包含表名、列名、数据类型等信息,系统需要依据自然语言文本中的关键词和语义,找到对应的数据库表和列。“订单信息” 可能对应数据库中的 “orders” 表,“销售额” 可能对应 “orders” 表中的 “sales_amount” 列。
最后一步是 SQL 生成,根据前面的分析和映射结果,结合 SQL 语言的语法规则和数据库的具体要求,生成对应的 SQL 语句。对于 “查询销售额大于 100 万的订单信息”,生成的 SQL 语句可能是 “SELECT * FROM orders WHERE sales_amount > 1000000;”。
然而,在实际应用中,数据库表的元数据往往非常庞大,直接将所有元数据提供给模型会导致输入过长,影响模型性能和生成 SQL 的准确性。这时,RAG 技术就发挥了重要作用。RAGflow 通过检索增强,从海量的数据库相关知识中找到与用户问题最相关的信息,而不是将所有元数据都提供给模型。它先将数据库的元数据、历史查询语句及对应的自然语言问题等信息进行向量化处理,存储到向量数据库中。当用户提出自然语言查询时,RAGflow 会在向量数据库中检索与问题相关的信息,将这些信息作为上下文提供给大语言模型,帮助模型生成更准确的 SQL 语句。如果用户询问 “查询上季度每个客户的购买总金额”,RAGflow 会从向量数据库中检索出与 “客户购买金额”“季度查询” 等相关的历史查询示例和数据库表结构信息,这些信息作为提示,引导大语言模型生成正确的 SQL 语句,如 “SELECT customer_id, SUM (purchase_amount) FROM orders WHERE quarter = ' 上季度 ' GROUP BY customer_id;” ,从而有效解决了数据库表元数据过多带来的问题,提高了 text-to-sql 的准确性和效率。
二、数据准备
确保已经安装了RAGFlow,参考链接:https://www.cnblogs.com/xiao987334176/p/18802471
搭建 text-to-sql 的 AI 研发助手,需要准备 3 类核心知识库数据,这些数据将为模型提供必要的信息,帮助其准确理解用户的自然语言查询,并生成正确的 SQL 语句。
这里以半期考试成绩表为例子
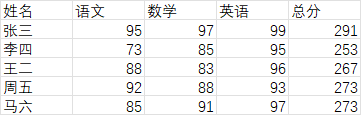
DDL知识库
第一类是 DDL(Data Definition Language)知识库,它主要提供数据库表结构信息,包括表名、列名、数据类型以及主键、外键等约束条件。
本地新建文件ddl.txt,内容如下:
CREATE TABLE `score` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'id',
`username` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '用户名',
`chinese` int DEFAULT '0' COMMENT '语文',
`mathematics` int DEFAULT '0' COMMENT '数学',
`english` int DEFAULT '0' COMMENT '英语',
`total` int DEFAULT '0' COMMENT '总分',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='成绩表';
通过这样的 DDL 语句,我们可以清晰地了解到成绩表表包含用户 ID、用户姓名、各科成绩等字段。获取 DDL 知识库数据可以通过数据库管理工具导出数据库的表结构定义,或者直接从数据库的系统表中查询相关信息。
DB Description 知识库
第二类是 DB Description 知识库,用于说明数据库中表和列的含义,这对于模型理解数据的语义非常重要。
本地新建文件description.txt,对于上面的成绩表,描述内容如下:
###成绩表(scroe)这个表描述了学生成绩,主要包含学生的语文,数学,英语成绩。详细的字段包含如下字段: id:id,表示用户的唯一性记录。 username:用户姓名,表示学生的用户姓名 chinese:语文,表示学生的语文成绩 mathematics:数学,表示学生的数学成绩 english:英语,表示学生的英语成绩 total:总分,表示学生的总成绩
注意:字段名需要和表结构一致,如果有多个表,请依次往下写即可。
Q->SQL 知识库
第三类是 Q->SQL 知识库,它包含了大量的参考 SQL,即自然语言问题与对应的 SQL 语句示例。
本地新建文件qa.xlsx,内如下:
| 自然语言问题 | SQl语句示例 |
| 成绩表中所有用户是哪些? | SELECT username from score |
| 成绩表中有多少条记录? | SELECT COUNT(1) from score |
| 成绩表中,语文成绩大于80的学生是哪些? | SELECT * from score WHERE chinese >=80 |
| 成绩表中,数学成绩大于80的学生是哪些? | SELECT * from score WHERE mathematics >=80 |
| 成绩表中,英语成绩大于80的学生是哪些? | SELECT * from score WHERE english >=80 |
| 成绩表中,所有成绩大于90的学生是哪些? | SELECT username from score WHERE chinese >=90 and mathematics >=90 and english >=90 |
| 成绩表中,总分最高的是哪个? | SELECT username,MAX(total) from score |
| 成绩表中,总分最低的是哪个? | SELECT username,MIN(total) from score |
这些语句主要是让大模型学习如何在有背景知识的情况下学会写SQL语句。这些叫做黄金语句,Golden statement,这些语句给的越多,大模型学习的越好,他能够回答的问题越有不会出错。正常情况下准备2000-5000个这样的SQL语句就可以了。
准备好这 3 类核心知识库数据后,我们就可以将其导入到 RAGflow 中,为后续搭建 text-to-sql 的 AI 研发助手做好充分准备。
三、配置知识库
准备好数据和环境后,我们就可以开始在 RAGflow 中配置知识库了。这一步是搭建 text-to-sql AI 研发助手的关键,知识库的质量直接影响到助手生成 SQL 语句的准确性。
上传文件
首先,配置 DDL 知识库。在 RAGflow 界面中,点击 “知识库”,然后选择 “创建知识库”。在弹出的创建知识库页面,为知识库命名,比如 “统一元数据库” 。

上传包含数据库表结构信息的 DDL 文件,DB Description 数据,Q->SQL 知识数据,分别对应3个文件:ddl.txt,description.txt,qa.xlsx
点击文件ddl.txt,description.txt,设置切片方法为General
点击文件qa.xlsx,切片方法为Q&A

然后分别对3个文件,进行手动解析,解析完成后,效果如下:
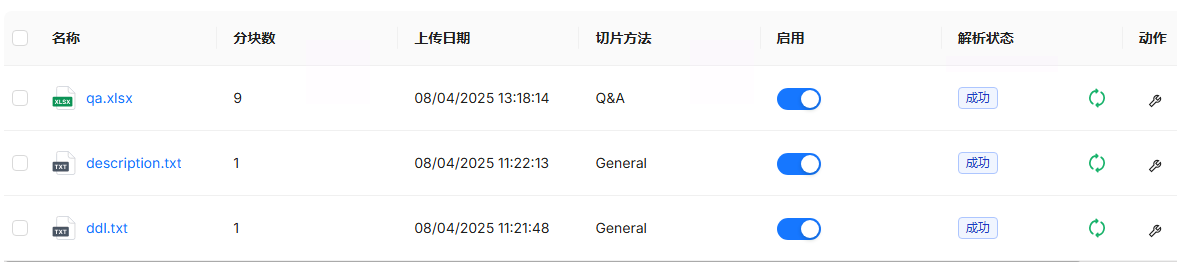
确保解释状态是成功的,数据会存储到向量数据库中,以便后续检索使用。
四、构建 TextToSQL 的 Agent
完成知识库的配置后,接下来就是构建 TextToSQL 的 Agent,它将负责接收用户的自然语言查询,并利用知识库中的信息生成相应的 SQL 语句。
在 RAGflow 界面中,找到 “Agent” 选项,点击 “Create agent”,然后选择 “Text To SQL” 。
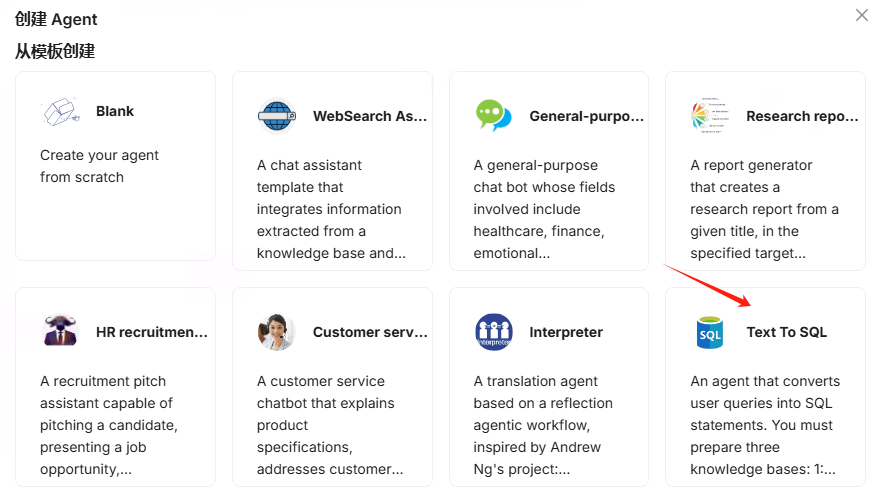
创建完成后,系统会默认生成一个 TextToSQL 的 Agent 模板。我们需要对这个模板进行一些配置,以使其能够正确地工作。
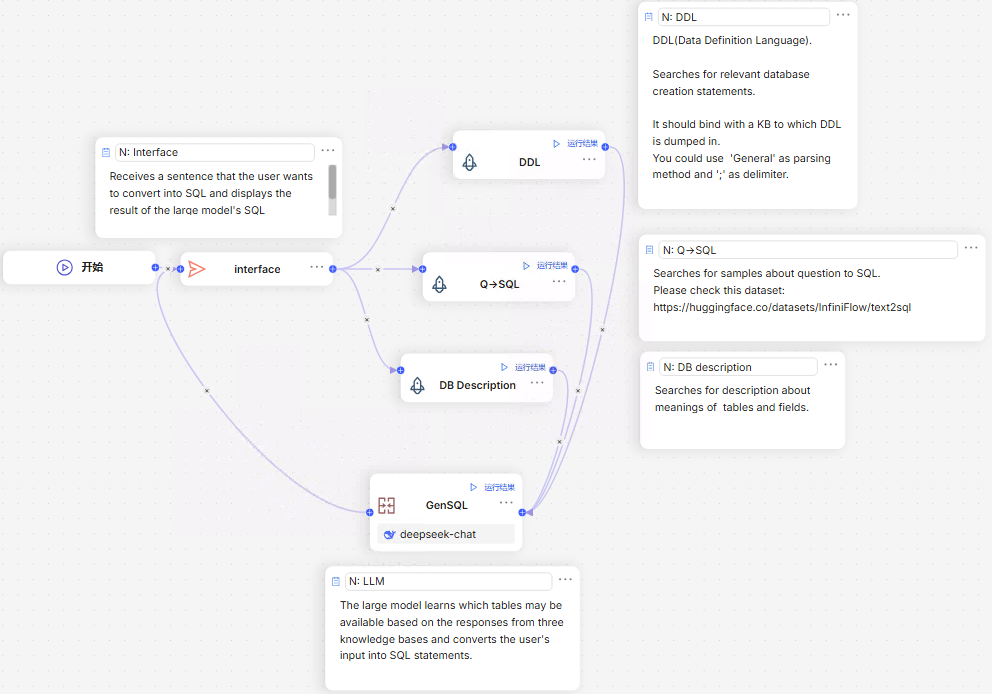
然后,对各个组件进行详细配置。在 “DDL” 组件中,选择之前创建的统一元数据库知识库,这样 Agent 在生成 SQL 语句时,就可以从该知识库中获取数据库的表结构信息。
点击DDL,添加变量interface
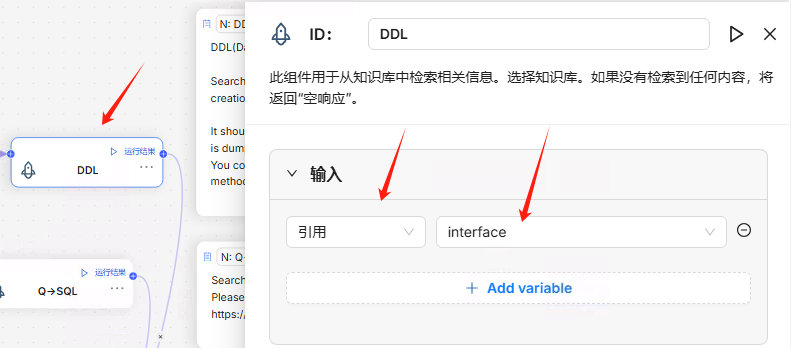
选择知识库,统一元数据库
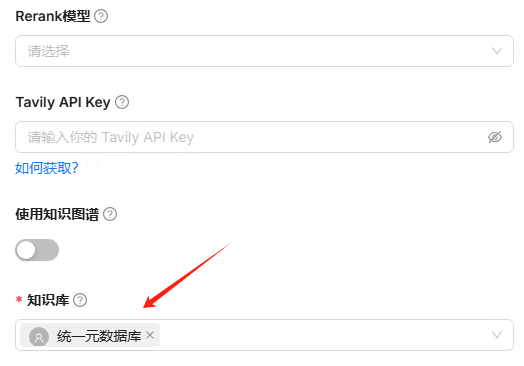
在 “Q->SQL” 组件中,选择对应的统一元数据库知识库,以便 Agent 能够参考其中的自然语言问题与 SQL 语句示例对,提高生成 SQL 语句的准确性。
点击Q->SQL,添加变量interface
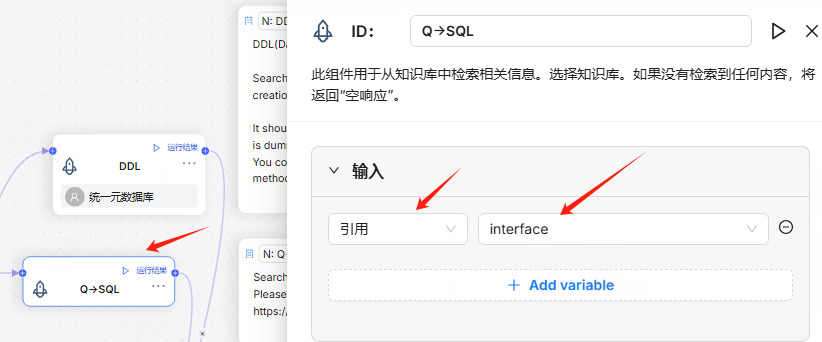
选择知识库,统一元数据库
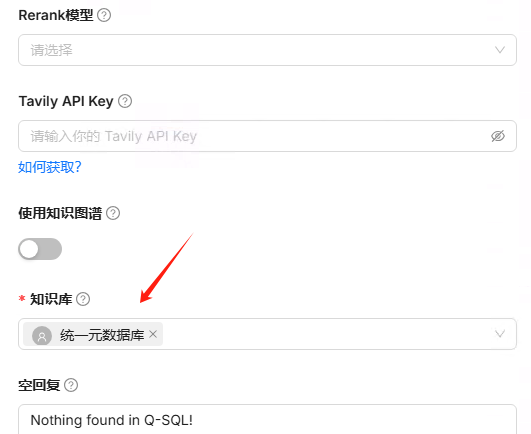
“DB_Description” 组件则选择 统一元数据库知识库,为 Agent 提供数据库表和列的语义信息,帮助其更好地理解用户的问题。
点击DB Description,添加变量interface
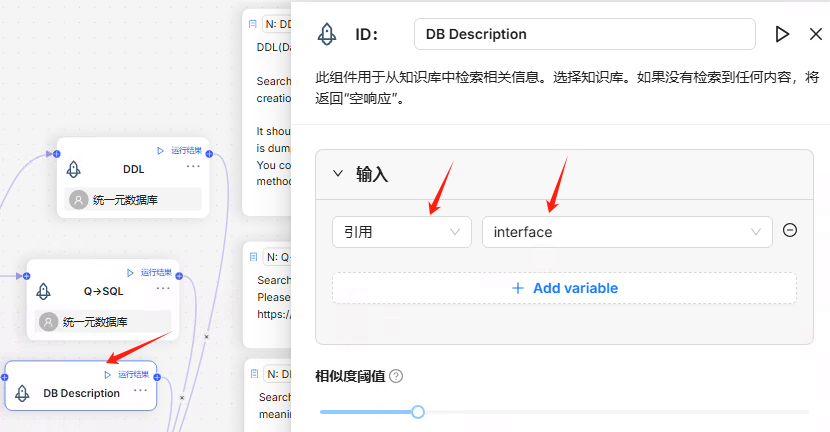
选择知识库,统一元数据库
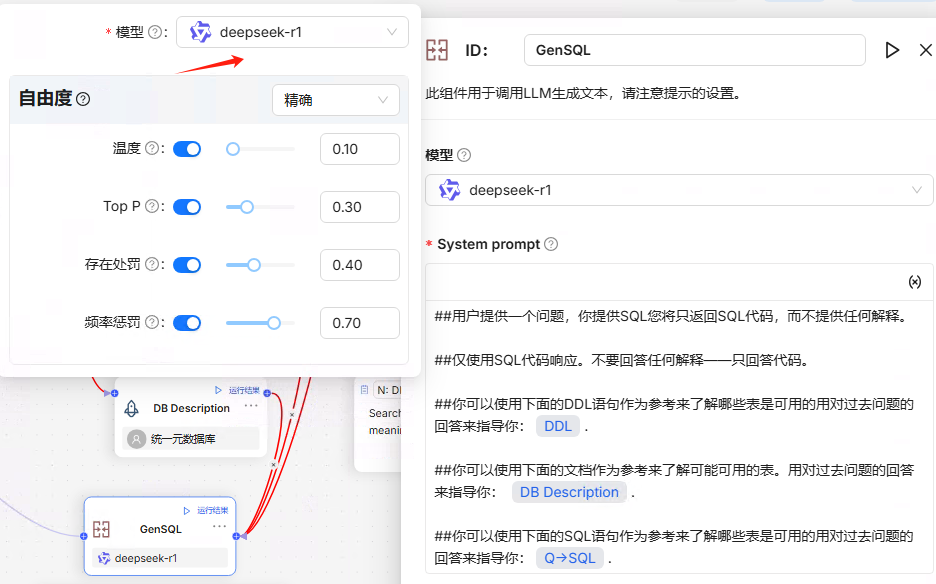
对于 “GenSQL” 组件,它负责根据用户的自然语言问题和从知识库中检索到的信息,生成 SQL 语句。这里可以根据实际需求调整一些参数,比如生成 温度、Top P等。
选择模型即可
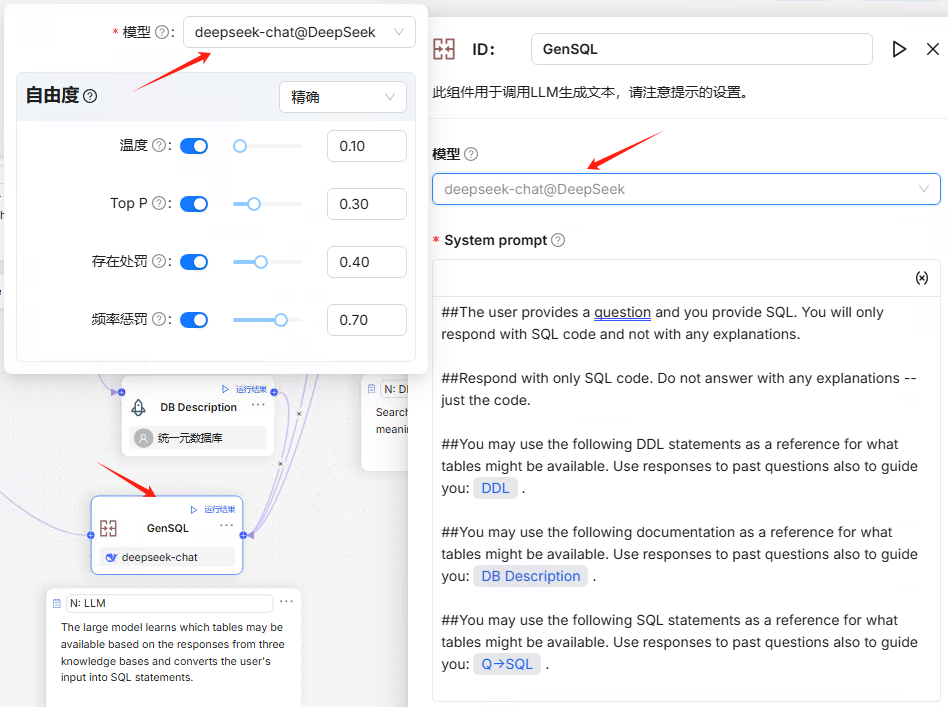
右边的提示词,是英文显示的。
如果觉得不爽,可以换成中文的,替换如下:
##用户提供一个问题,你提供SQL您将只返回SQL代码,而不提供任何解释。
##仅使用SQL代码响应。不要回答任何解释——只回答代码。
##你可以使用下面的DDL语句作为参考来了解哪些表是可用的用对过去问题的回答来指导你: {ddl_input}.
##你可以使用下面的文档作为参考来了解可能可用的表。用对过去问题的回答来指导你: {db_input}.
##你可以使用下面的SQL语句作为参考来了解哪些表是可用的用对过去问题的回答来指导你:{sql_input}.
注意,直接粘贴过去,变量显示会有问题。
点击右边的(x),替换一下即可
选择模型,deepssek-r1,自由度精确
最后点击保存
经过以上步骤,我们就成功地在 RAGflow 中搭建了一个 text-to-sql 的 AI 研发助手。接下来,就可以使用这个助手进行自然语言到 SQL 的转换,快速查询数据库中的数据了。
五、效果展示与案例分析
问题1:所有成绩大于90的学生是哪些
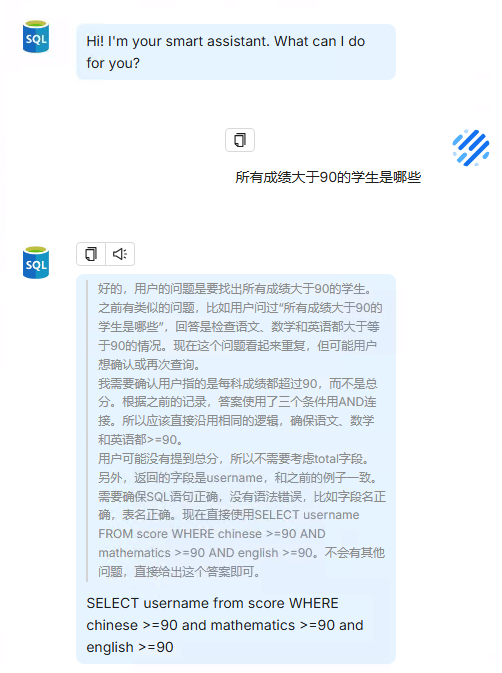
问题:2:哪个学生成绩是最好的
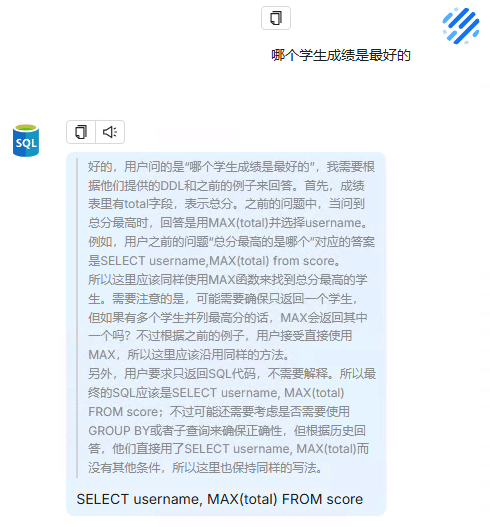
问题3:成绩优等,各个科目成绩在90分以上的,有哪些?

从测试的结果来来看,deepseek+ragflow 可以很好的完成sql语句的输出,但是前提条件是给它需要足够多的Golden statement,如果某个问题和
Golden statement差距太大,比如Golden statement中没有占比类型的语句,用户问它,它可能写出的语句是错误的,这个时候就需要人工矫正后,把正确的语句给它,后面它再写就可以写对了,所以这个ai研发助手还有一个重要的功能就是用户使用过程中产生好的句子,可以且用户验证是正确的,那么可以自动写入Golden statement中,这样,这个助手就会越用越好用了。
本文参考链接:https://mp.weixin.qq.com/s/l8vtqRfbMQ37tu-1HCpV1A
RAGflow搭建text-to-sql的AI研发助手的更多相关文章
- 从原理到代码:大牛教你如何用 TensorFlow 亲手搭建一套图像识别模块 | AI 研习社
从原理到代码:大牛教你如何用 TensorFlow 亲手搭建一套图像识别模块 | AI 研习社 PPT链接: https://pan.baidu.com/s/1i5Jrr1N 视频链接: https: ...
- 华为nova3发布,将支持华为AI旅行助手
华为nova3于7月18日18:00在深圳大运中心体育馆举行华为nova 3的发布会,从本次华为nova3选择的代言人-易烊千玺,不难看出新机依然延续nova系列的年轻属性,主打 “高颜值 爱自 ...
- Spring+SpringMVC+MyBatis深入学习及搭建(五)——动态sql
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/6908763.html 前面有讲到Spring+SpringMVC+MyBatis深入学习及搭建(四)——My ...
- 讲讲我当年是怎么拿到AI研发公司offer的
前言 很多的老铁私信问我,当年我是怎么拿到公司offer的,我记得我毕业是2015年,那时人工智能这个行业还没热起来,能提供的岗位很少但是面试的人更少,我又是本专业毕业的,所以当初找工作还算顺利,去面 ...
- 是时候给你的产品配一个AI问答助手了!
本文由云+社区发表 | 导语 问答系统是信息检索的一种高级形式,能够更加准确地理解用户用自然语言提出的问题,并通过检索语料库.知识图谱或问答知识库返回简洁.准确的匹配答案.相较于搜索引擎,问答系统能更 ...
- NLP实践!文本语法纠错模型实战,搭建你的贴身语法修改小助手 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 自然语言处理实战系列:https://www.showmeai.tech ...
- 推荐一款功能齐全的开源客户端( iOS 、Android )研发助手。
DoraemonKit ,简称DoKit,中文名 哆啦A梦,意味着能够像哆啦A梦一样提供给他的主人各种各样的工具. 开发背景 每一个稍微有点规模的 App,总会自带一些线下的测试功能代码,比如环境切换 ...
- 实战!轻松搭建图像分类 AI 服务
人工智能技术(以下称 AI)是人类优秀的发现和创造之一,它代表着至少几十年的未来.在传统的编程中,工程师将自己的想法和业务变成代码,计算机会根据代码设定的逻辑运行.与之不同的是,AI 使计算机有了「属 ...
- 常见的sql注入环境搭建
常见的sql注入环境搭建 By : Mirror王宇阳 Time:2020-01-06 PHP+MySQL摘要 $conn = new mysqli('数据库服务器','username','pass ...
- 搭建sql注入实验环境(基于windows)
搭建服务器环境 1.下载xampp包 地址:http://www.apachefriends.org/zh_cn/xampp.html 很多人觉得安装服务器是件不容易的事,特别是要想添加MySql, ...
随机推荐
- 阿里云-数据库-ClickHouse
https://help.aliyun.com/product/144466.html 云数据库ClickHouse是开源列式数据库管理系统ClickHouse在阿里云上的托管服务,用户可以在阿里云上 ...
- Qml 中实现时间轴组件
[写在前面] 时间轴组件是现代用户界面中常见的元素,用于按时间顺序展示事件. 本文将介绍如何使用 Qml 实现一个灵活且可定制的时间轴组件,并探讨其设计思路和实现细节. [正文开始] 效果图 组件概述 ...
- Slort pg walkthrough Intermediate window
nmap ┌──(root㉿kali)-[~] └─# nmap -p- -A -sS 192.168.226.53 Starting Nmap 7.94SVN ( https://nmap.org ...
- React中的数据流管理
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 本文作者:霜序 前言 为什么数据流管理重要? React 的核心思想 ...
- uni-app封装input组件用于登录
组件 <template> <view> <view class="uni-form-item uni-column"> <input c ...
- 概率学习(Genshin中)
目前待补充:停时定理的部分例题. 定义 首先定义样本空间 \(\Omega\),是所有样本点(结果)的集合. 随机事件 \(A\) 是样本空间的子集. 定义事件和为事件并,积为事件交. 事件域 \(\ ...
- CSP 2024 游记
初赛 Day -1 唐,rp--了. 上午语文正卷满分,然后作文挂完了靠.我没想到我作文能挂到 40pts. 吃饭的时候 gcy 说了什么奇怪的东西,然后喷饭爆金币了,社死现场.吃饭的时候还 tm 咬 ...
- 最长不降子序列 n log n 方案输出与 Dilworth 定理 - 动态规划模板
朴素算法 不必多说,\(O(n^2)\) 的暴力 dp 转移. 优化算法 时间为 \(O(n \log n)\) ,本质是贪心,不是 dp . 思路是维护一个单调栈(手写版),使这个栈单调不降. 当该 ...
- 流程控制之do while循环
语法 do { //代码语句}while(布尔表达式): 与while的区别 while是先判断再执行,do while是先执行再判断 循环体至少会被执行一次 实例1: package com. ...
- HTML骨架简述
<!DOCTYPE html><!-- <!声明 DOC docment文件/文档 TYPE 类别/类型 告知浏览器当前文档为html> --><html&g ...