Hadoop:HDFS设计原理
一、HDFS组成结构
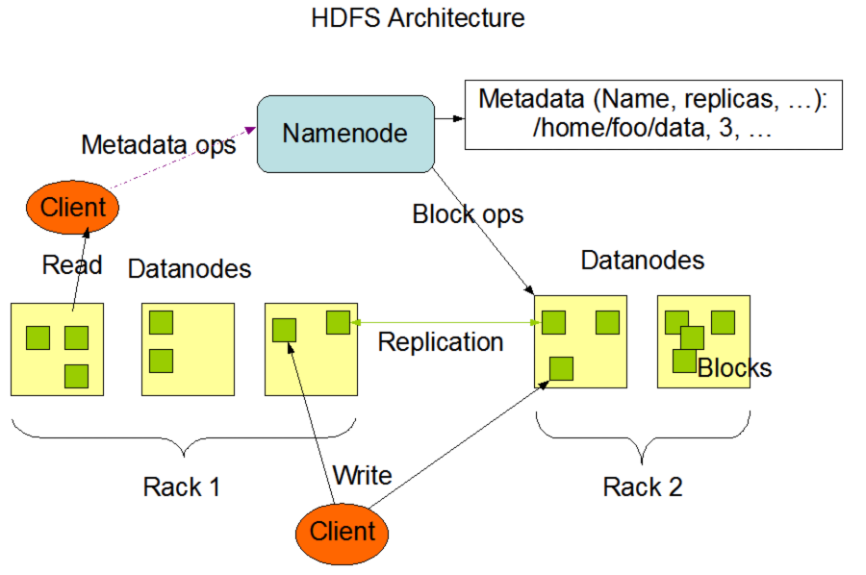
1、NameNode
- 相当于Master,主要存储文件的元数据(文件名、目录结构、文件属性等),以及每个文件的块列表和块所在的DataNode。
- 配置副本策略,管理数据库映射信息,处理客户端读写请求等。
2、DataNode
- 相当于Slave,主要用于存储文件块数据,执行数据块的读写操作。
- 数据块大小定义(1.x版本默认64M,2.x/3.x版本默认128M)。
- 数据块太小,会增加程序寻址时间;太大会影响磁盘传输时间。
3、Client
- 文件切分(上传到HDFS时,client会将文件切分成一个个数据块,再进行上传)。
- 与NameNode交互,获取文件位置信息。
- 与DataNode交互,读写数据。
- 可以通过一些命令管理HDFS(NameNode格式化、对HDFS增删改查等)。
4、Secondary NameNode
- 不是NameNode的热备,当NameNode挂掉的时候,可辅助恢复NameNode。
- 辅助NameNode,每隔一段时间对NameNode元数据备份(定期合并Fsimage和Edits,并推送给NameNode)。
二、HDFS写数据流程
2.1 写数据流程
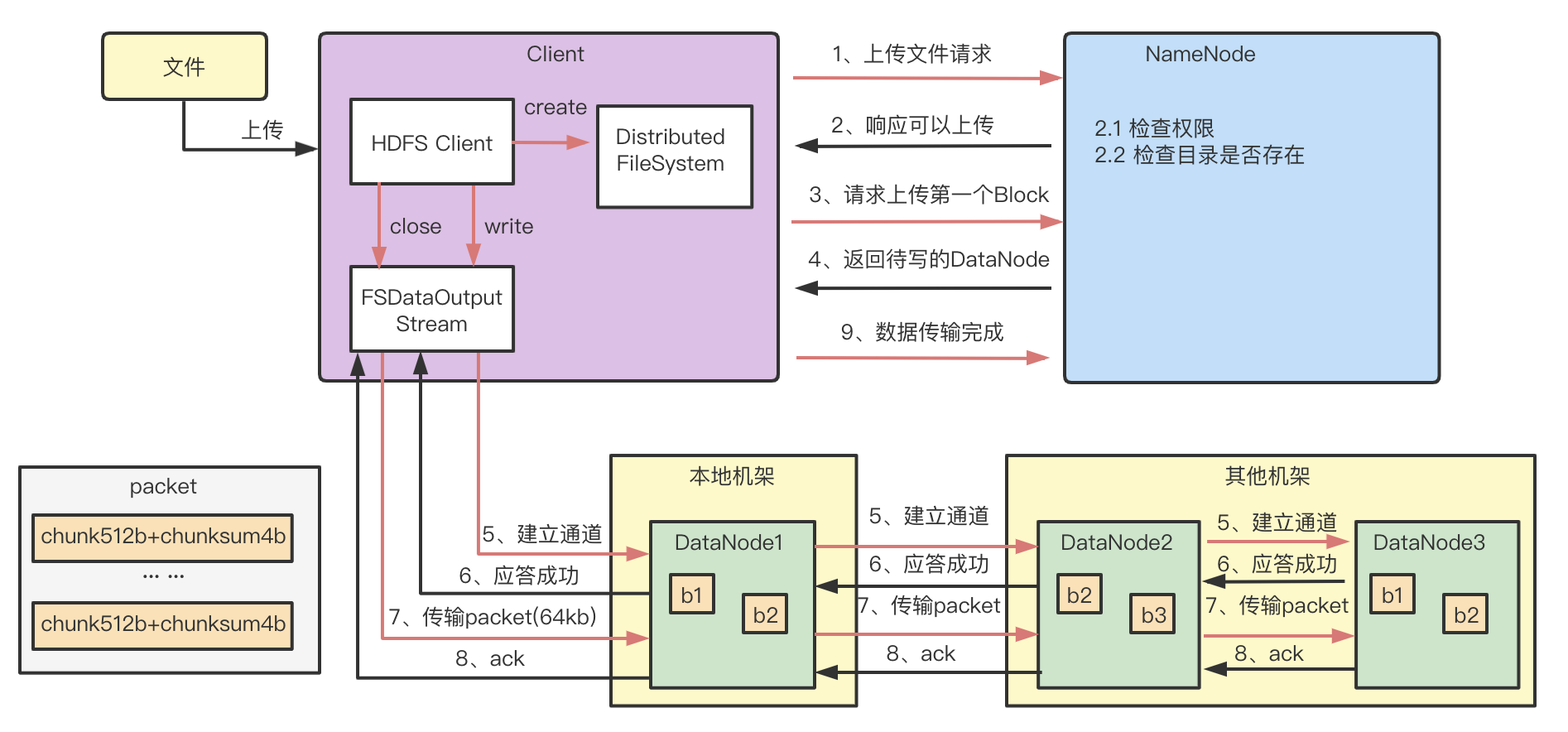
1、Client通过Distributed FileSystem 向 NameNode 请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在。
2、NameNode 返回是否可以上传。
3、客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
4、NameNode 返回待上传的DataNode 节点。
5、客户端通过 FSDataOutputStream 请求 DN1上传数据,DN1收到请求会继续调用DN2,然后DN2调用DN3,将这个通信管道建立完成。
6、DN1、DN2、DN3逐级应答客户端。
7、客户端开始往DN1上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),以Packet(64K)为单位,DN1收到一个Packet,会一边写本地一边传给DN2,DN2再一边写本地一边传给DN3;每传一个 packet都会放入一个ack应答队列。
8、当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务器。(重复执行 3-7 步)。
2.2 副本节点选择
- 第一个副本在Client所处的节点上。如果客户端在集群外, 随机选一个。
- 第二个副本在另一个机架的随机一个节点。
- 第三个副本在第二个副本所在机架的随机节点。
2.3 网络拓扑-节点距离计算
在 HDFS 写数据的过程中, NameNode 会选择距离待上传数据最近距离的 DataNode 接收数据。 那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。

三、HDFS读数据流程

1、客户端通过 DistributedFileSystem 向 NameNode 请求下载文件, NameNode 通过查询元数据,找到文件块所在的 DataNode 地址。
2、挑选一台 DataNode(节点距离最近+负载均衡)服务器,请求读取数据。
3、DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。
4、并行读取Block,并对读取的Block做checksum验证,出现错误会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
5、客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
四、NameNode 和 SecondaryNameNode
思考: NameNode 中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在 NameNode 节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。 因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新 FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦 NameNode 节点断电,就会产生数据丢失。 因此,引入 Edits 文件(只进行追加操作,效率很高) 。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到 Edits 中。 这样,一旦 NameNode 节点断电,可以通过 FsImage 和 Edits 的合并,合成元数据。
但是,如果长时间添加数据到 Edits 中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行 FsImage 和 Edits 的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于 FsImage 和 Edits 的合并。
4.1 NameNode工作机制
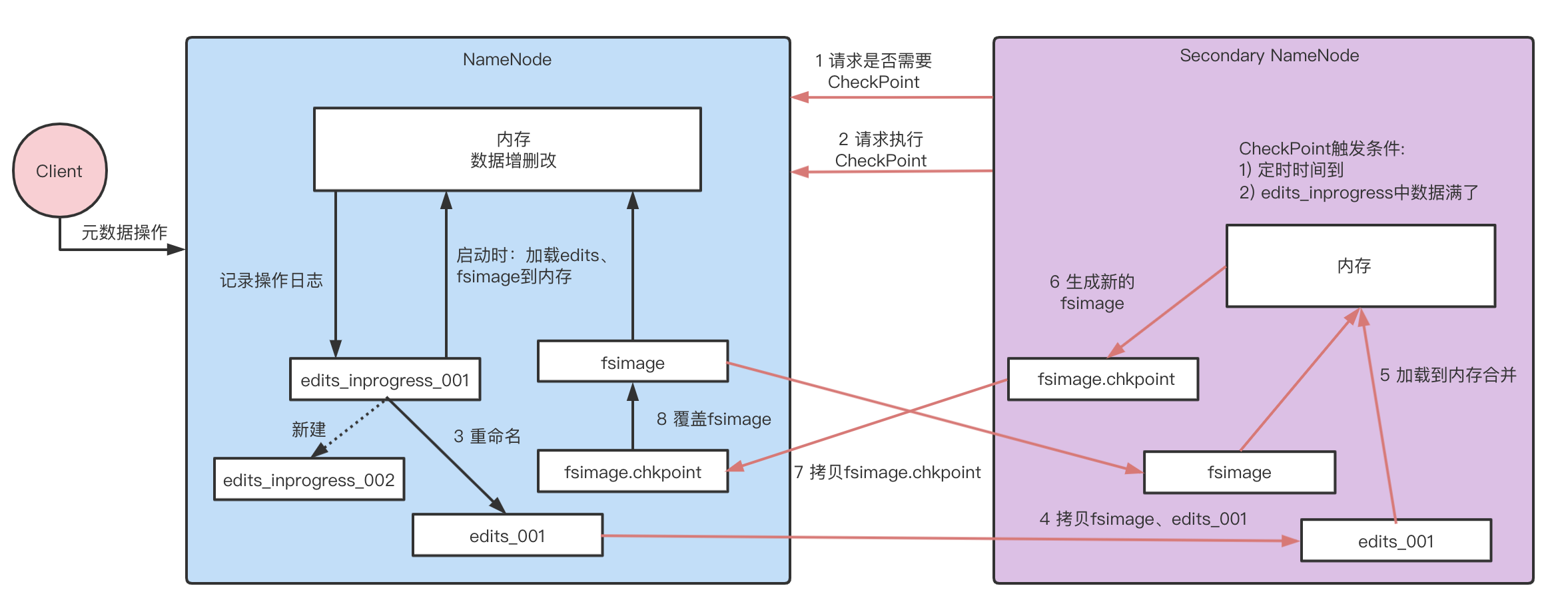
第一阶段:NameNode工作
1、第一次启动 NameNode 格式化后, 创建 fsimage 和 edits 文件。如果不是第一次启动,直接加载fsimage和edits_inprogress_001到内存。
2、客户端对元数据进行增删改的请求。
3、NameNode 在内存中对元数据进行增删改,记录操作日志写到edits_inprogress_001,执行CheckPoint时会重命名为edits_001,再生成一个新的edits_inprogress_002,后续记录写到edits_inprogress_002中。
第二阶段:Secondary NameNode工作
1、Secondary NameNode 询问 NameNode 是否需要 CheckPoint。 直接返回 NameNode是否检查结果。
2、Secondary NameNode 请求执行 CheckPoint。
3、NameNode新建edits_inprogress_002,将edits_inprogress_001重命名为edits_001。
4、将滚动前的fsimage和edits_001拷贝到 Secondary NameNode。
5、Secondary NameNode加载fsimage和edits_001到内存。
6、Secondary NameNode合并生成新的镜像文件fsimage.chkpoint。
7、拷贝 fsimage.chkpoint 到 NameNode。
8、NameNode 将 fsimage.chkpoint 重新命名成fsimage并覆盖掉旧的。
4.2 Fsimage 和 Edits
[${hadoop.tmp.dir}/dfs/name/current]
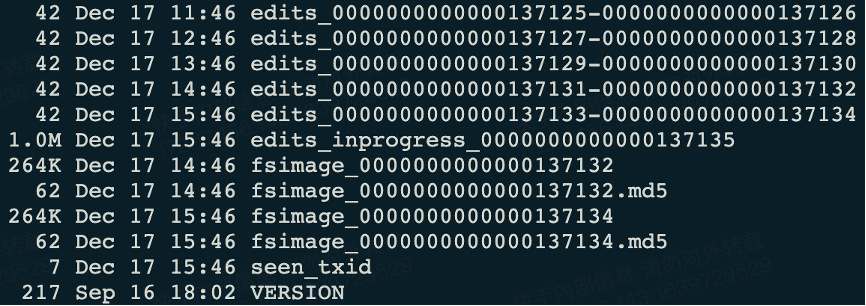
[${hadoop.tmp.dir}/dfs/namesecondary/current]

NameNode被格式化之后, 将在${hadoop.tmp.dir}/dfs/name/current目录中产生如下文件:
1、fsimage文件:HDFS文件系统元数据的一个永久性的检查点, 其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
2、edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
3、seen_txid文件:保存的是一个数字,就是最后一个edits_的数字。
4、每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
反编译fsimage:hdfs oiv -p XML -i fsimage_0000000000000137086 -o fsimage_out.xml
反编译edits:hdfs oev -p XML -i edits_inprogress_0000000000000137089 -o edits_out.xml4.3 CheckPoint 时间设置
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>10000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
<description> 1 分钟检查一次操作次数</description>
</property>五、DataNode工作机制
5.1 DataNode工作机制
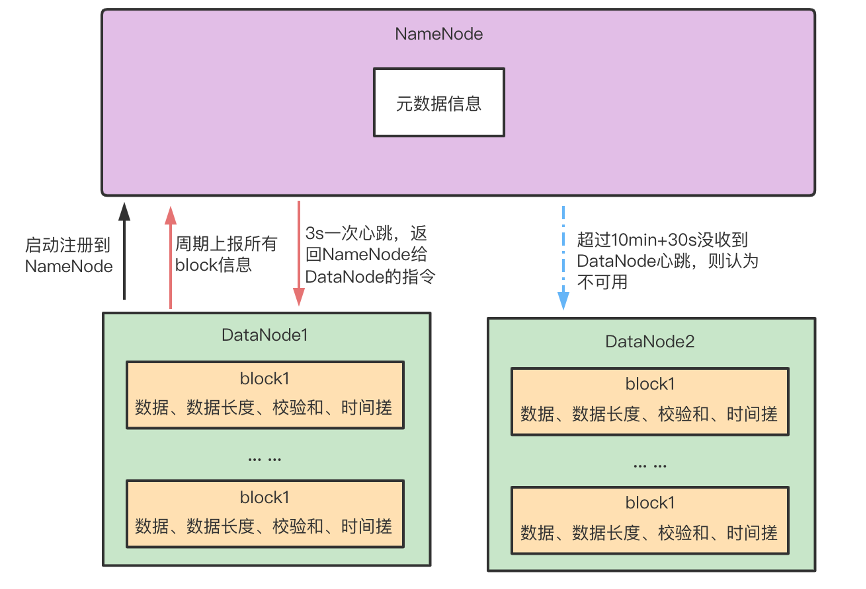
1、一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2、DataNode 启动后向 NameNode 注册,通过后,周期性(默认6 小时)的向NameNode上报所有的块信息。
3、心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令。如复制块数据到另一台机器,或删除某个数据块。 如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4、集群运行中可以安全加入和退出一些机器。
5.2 数据完整性
(1) 当 DataNode 读取 Block 的时候,它会计算 CheckSum。
(2) 如果计算后的 CheckSum,与 Block 创建时值不一样,说明 Block 已经损坏。
(3) Client 读取其他 DataNode 上的 Block。
(4)常见的校验算法 crc(32), md5(128), sha1(160)。
(5) DataNode 在其文件创建后周期验证 CheckSum。

5.3 掉线时限参数设置
1、 DataNode进程死亡或者网络故障造成DataNode无法与NameNode通信。
2、 NameNode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。
3、 HDFS默认的超时时长为10分钟+30秒。
4、 如果定义超时时间为TimeOut,则超时时长的计算公式为:TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟, dfs.heartbeat.interval默认为3秒。
需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,dfs.heartbeat.interval 的单位为秒。
[hdfs-site.xml]
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>参考资料:
http://www.atguigu.com/bigdata_video.shtml#bigdata
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.htmlhttps://blog.csdn.net/weixin_38750084/article/details/82963235https://www.cnblogs.com/zsql/p/11587240.htmlhttps://blog.csdn.net/woshiwanxin102213/article/details/19990487
Hadoop:HDFS设计原理的更多相关文章
- Hadoop HDFS 设计随想
目录 引言 HDFS 数据块的设计 数据块应该设置成多大? 抽象成数据块有哪些好处? 操作块信息的命令 HDFS 中节点的设计 有几种节点类型? 用户如何访问 HDFS? 如何对 namenode 容 ...
- 基于key/value+Hadoop HDFS 设计的存储系统的shell命令接口
对于hadoop HDFS 中的全部命令进行解析(当中操作流程是自己的想法有不允许见欢迎大家指正) 接口名称 功能 操作流程 get 将文件拷贝到本地文件系统 . 假设指定了多个源文件,本地目的端必须 ...
- Hadoop之HDFS优缺点、设计原理、框架
如需大数据开发整套视频(hadoop\hive\hbase\flume\sqoop\kafka\zookeeper\presto\spark):请联系QQ:1974983704 Hadoop的前世今 ...
- HADOOP HDFS的设计
Hadoop提供的对其HDFS上的数据的处理方式,有以下几种, 1 批处理,mapreduce 2 实时处理:apache storm, spark streaming , ibm streams 3 ...
- Hadoop — HDFS的概念、原理及基本操作
1. HDFS的基本概念和特性 设计思想——分而治之:将大文件.大批量文件分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析.在大数据系统中作用:为各类分布式运算框架(如:map ...
- Hadoop(三)HDFS读写原理与shell命令
一 HDFS概述 1.1 HDFS产生背景 随着数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件 ...
- 【转帖】Hadoop — HDFS的概念、原理及基本操作
Hadoop — HDFS的概念.原理及基本操作 https://www.cnblogs.com/swordfall/p/8709025.html 分类: Hadoop undefined 1. HD ...
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- Hadoop之HDFS读写原理
一.HDFS基本概念 HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访 ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
随机推荐
- FDConnection lost后的处理right here
- 康谋分享 | 汽车仿真与AI的结合应用
在自动驾驶领域,实现高质量的虚拟传感器输出是一项关键的挑战.所有的架构和实现都会涉及来自质量.性能和功能集成等方面的需求.aiSim也不例外,因此我们会更加关注于多个因素的协调,其中,aiSim传感器 ...
- issue: java.lang.NoClassDefFoundError: javax/el/ELManager
问题描述: Context initialization failed org.springframework.beans.factory.BeanCreationException: Error c ...
- [亲测]ThinkPHP中where方法中变量不解析的解决方法
2018年5月4日 01:15 血的教训,今天做一个项目,需要批量更新数据,所以where中必须用变量.发现where里的变量不解析并且会直接报错,然后通过搜索发现可以在双引号中的左右加号中包裹变量 ...
- java8接口新特性:default、static
java8之前接口中的方法默认类型都是public abstract,也就是抽象方法,具体实现都交给实现类.而java8对接口功能做了增强,增加了default方法和static方法,也就是说从jav ...
- 数据库问题之“字符编码问题 Cause: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x8E\x81\xE7\x88...' for column 'product_name' at row 41”
1)表1和表2的产品名称[数据库字段]字符编译方式不一致 ①问题 org.springframework.jdbc.UncategorizedSQLException: Error updating ...
- vue3 基础-API-响应式 ref, reactive
上篇咱介绍了 CompositionAPI, 其核心思想是直接在函数作用域内定义响应式状态变量,并将从多个函数中得到的状态组合起来处理复杂问题. 然后初介绍了 setup 函数的作用, 即其是在 cr ...
- 基于First Order Motion与TTS的AI虚拟主播系统全流程实现教程
前言:多模态虚拟主播的技术革命 在AI内容生成领域,虚拟主播技术正经历从2D到3D.从固定模板到个性化定制的跨越式发展.本文将深入解析如何通过Python技术栈构建支持形象定制与声音克隆的AI虚拟主播 ...
- 玩转代码:深入GitHub,高效管理我们的“shou学”平台源代码
玩转代码:深入GitHub,高效管理我们的"shou学"平台源代码 在当今快节奏的开发世界中,有效地管理代码不仅仅是一种良好实践,更是一种必需.无论您是独立开发者还是大型团队的一员 ...
- QJson出现“\n“变成“\\n“
在使用QJson的时候出现了字符串有\n的情况,在QJson转换为QByteArray的时候,\n变成了\n的情况,可以通过这样解决 int index = -1; do { index = qByt ...