统计学习方法学习(四)--KNN及kd树的java实现
K近邻法
1基本概念
K近邻法,是一种基本分类和回归规则。根据已有的训练数据集(含有标签),对于新的实例,根据其最近的k个近邻的类别,通过多数表决的方式进行预测。
2模型相关
2.1 距离的度量方式
定义距离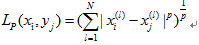
(1)欧式距离:p=2。
(2)曼哈顿距离:p=1。
(3)各坐标的最大值:p=∞。
2.2 K值的选择
通常使用交叉验证法来选取最优的k值。
k值大小的影响:
k越小,只有距该点较近的实例才会起作用,学习的近似误差会较小。但此时又会对这些近邻的实例很敏感,如果紧邻点存在噪声,预测就会出错,即学习的估计误差大,泛化能力不好。
K越大,距该点较远的实例也会起作用,造成近似误差增大,使预测发生错误。
2.3 k近邻法的实现:kd树
Kd树是二叉树。kd树是一种对K维空间中的实例点进行存储以便对其进行快速检索的树形数据结构.
Kd树是二叉树, 表示对K维空间的一个划分( partition).构造Kd树相 当于不断地用垂直于坐标轴的超平面将k维空间切分, 构成一系列的k维超矩形区域.Kd树的每个结点对应于一个k维超矩形区域
其中,创建kd树时,垂直于坐标轴的超平面垂直的坐标轴选择是:
L=(J mod k)+1。其中,j为当前节点的节点深度,k为k维空间(给定实例点的k个维度)。根节点的节点深度为0.此公式可看为:依次循环实例点的k个维所对应的坐标轴。
Kd树的节点(分割点)为L维上所有实例点的中位数。
2.4 Kd树的实现
别处代码实现基于其他博客,但是纠正了其中的错误,能够返回前k个近邻。如果要求最近邻,只需要将k=1即可。
public class BinaryTreeOrder {
public void preOrder(Node root) {
if(root!= null){
System.out.print(root.toString());
preOrder(root.left);
preOrder(root.right);
}
}
}
public class kd_main {
public static void main(String[] args) {
List<Node> nodeList=new ArrayList<Node>();
nodeList.add(new Node(new double[]{5,4}));
nodeList.add(new Node(new double[]{9,6}));
nodeList.add(new Node(new double[]{8,1}));
nodeList.add(new Node(new double[]{7,2}));
nodeList.add(new Node(new double[]{2,3}));
nodeList.add(new Node(new double[]{4,7}));
nodeList.add(new Node(new double[]{4,3}));
nodeList.add(new Node(new double[]{1,3}));
kd_main kdTree=new kd_main();
Node root=kdTree.buildKDTree(nodeList,0);
new BinaryTreeOrder().preOrder(root);
for (Node node : nodeList) {
System.out.println(node.toString()+"-->"+node.left.toString()+"-->"+node.right.toString());
}
System.out.println(root);
System.out.println(kdTree.searchKNN(root,new Node(new double[]{2.1,3.1}),2));
System.out.println(kdTree.searchKNN(root,new Node(new double[]{2,4.5}),1));
System.out.println(kdTree.searchKNN(root,new Node(new double[]{2,4.5}),3));
System.out.println(kdTree.searchKNN(root,new Node(new double[]{6,1}),5));
}
/**
* 构建kd树 返回根节点
* @param nodeList
* @param index
* @return
*/
public Node buildKDTree(List<Node> nodeList,int index)
{
if(nodeList==null || nodeList.size()==0)
return null;
quickSortForMedian(nodeList,index,0,nodeList.size()-1);//中位数排序
Node root=nodeList.get(nodeList.size()/2);//中位数 当做根节点
root.dim=index;
List<Node> leftNodeList=new ArrayList<Node>();//放入左侧区域的节点 包括包含与中位数等值的节点-_-
List<Node> rightNodeList=new ArrayList<Node>();
for(Node node:nodeList)
{
if(root!=node)
{
if(node.getData(index)<=root.getData(index))
leftNodeList.add(node);//左子区域 包含与中位数等值的节点
else
rightNodeList.add(node);
}
}
//计算从哪一维度切分
int newIndex=index+1;//进入下一个维度
if(newIndex>=root.data.length)
newIndex=0;//从0维度开始再算
root.left=buildKDTree(leftNodeList,newIndex);//添加左右子区域
root.right=buildKDTree(rightNodeList,newIndex);
if(root.left!=null)
root.left.parent=root;//添加父指针
if(root.right!=null)
root.right.parent=root;//添加父指针
return root;
}
/**
* 查询最近邻
* @param root kd树
* @param q 查询点
* @param k
* @return
*/
public List<Node> searchKNN(Node root,Node q,int k)
{
List<Node> knnList=new ArrayList<Node>();
searchBrother(knnList,root,q,k);
return knnList;
}
/**
* searhchBrother
* @param knnList
* @param k
* @param q
*/
public void searchBrother(List<Node> knnList, Node root, Node q, int k) {
// Node almostNNode=root;//近似最近点
Node leafNNode=searchLeaf(root,q);
double curD=q.computeDistance(leafNNode);//最近近似点与查询点的距离 也就是球体的半径
leafNNode.distance=curD;
maintainMaxHeap(knnList,leafNNode,k);
System.out.println("leaf1"+leafNNode.getData(leafNNode.parent.dim));
while(leafNNode!=root)
{
if (getBrother(leafNNode)!=null) {
Node brother=getBrother(leafNNode);
System.out.println("brother1"+brother.getData(brother.parent.dim));
if(curD>Math.abs(q.getData(leafNNode.parent.dim)-leafNNode.parent.getData(leafNNode.parent.dim))||knnList.size()<k)
{
//这样可能在另一个子区域中存在更加近似的点
searchBrother(knnList,brother, q, k);
}
}
System.out.println("leaf2"+leafNNode.getData(leafNNode.parent.dim));
leafNNode=leafNNode.parent;//返回上一级
double rootD=q.computeDistance(leafNNode);//最近近似点与查询点的距离 也就是球体的半径
leafNNode.distance=rootD;
maintainMaxHeap(knnList,leafNNode,k);
}
}
/**
* 获取兄弟节点
* @param node
* @return
*/
public Node getBrother(Node node)
{
if(node==node.parent.left)
return node.parent.right;
else
return node.parent.left;
}
/**
* 查询到叶子节点
* @param root
* @param q
* @return
*/
public Node searchLeaf(Node root,Node q)
{
Node leaf=root,next=null;
int index=0;
while(leaf.left!=null || leaf.right!=null)
{
if(q.getData(index)<leaf.getData(index))
{
next=leaf.left;//进入左侧
}else if(q.getData(index)>leaf.getData(index))
{
next=leaf.right;
}else{
//当取到中位数时 判断左右子区域哪个更加近
if(q.computeDistance(leaf.left)<q.computeDistance(leaf.right))
next=leaf.left;
else
next=leaf.right;
}
if(next==null)
break;//下一个节点是空时 结束了
else{
leaf=next;
if(++index>=root.data.length)
index=0;
}
}
return leaf;
}
/**
* 维护一个k的最大堆
* @param listNode
* @param newNode
* @param k
*/
public void maintainMaxHeap(List<Node> listNode,Node newNode,int k)
{
if(listNode.size()<k)
{
maxHeapFixUp(listNode,newNode);//不足k个堆 直接向上修复
}else if(newNode.distance<listNode.get(0).distance){
//比堆顶的要小 还需要向下修复 覆盖堆顶
maxHeapFixDown(listNode,newNode);
}
}
/**
* 从上往下修复 将会覆盖第一个节点
* @param listNode
* @param newNode
*/
private void maxHeapFixDown(List<Node> listNode,Node newNode)
{
listNode.set(0, newNode);
int i=0;
int j=i*2+1;
while(j<listNode.size())
{
if(j+1<listNode.size() && listNode.get(j).distance<listNode.get(j+1).distance)
j++;//选出子结点中较大的点,第一个条件是要满足右子树不为空
if(listNode.get(i).distance>=listNode.get(j).distance)
break;
Node t=listNode.get(i);
listNode.set(i, listNode.get(j));
listNode.set(j, t);
i=j;
j=i*2+1;
}
}
private void maxHeapFixUp(List<Node> listNode,Node newNode)
{
listNode.add(newNode);
int j=listNode.size()-1;
int i=(j+1)/2-1;//i是j的parent节点
while(i>=0)
{
if(listNode.get(i).distance>=listNode.get(j).distance)
break;
Node t=listNode.get(i);
listNode.set(i, listNode.get(j));
listNode.set(j, t);
j=i;
i=(j+1)/2-1;
}
}
/**
* 使用快排进进行一个中位数的查找 完了之后返回的数组size/2即中位数
* @param nodeList
* @param index
* @param left
* @param right
*/
@Test
private void quickSortForMedian(List<Node> nodeList,int index,int left,int right)
{
if(left>=right || nodeList.size()<=0)
return ;
Node kn=nodeList.get(left);
double k=kn.getData(index);//取得向量指定索引的值
int i=left,j=right;
//控制每一次遍历的结束条件,i与j相遇
while(i<j)
{
//从右向左找一个小于i处值的值,并填入i的位置
while(nodeList.get(j).getData(index)>=k && i<j)
j--;
nodeList.set(i, nodeList.get(j));
//从左向右找一个大于i处值的值,并填入j的位置
while(nodeList.get(i).getData(index)<=k && i<j)
i++;
nodeList.set(j, nodeList.get(i));
}
nodeList.set(i, kn);
if(i==nodeList.size()/2)
return ;//完成中位数的排序了,但并不是完成了所有数的排序,这个终止条件只是保证中位数是正确的。去掉该条件,可以保证在递归的作用下,将所有的树
//将所有的数进行排序
else if(i<nodeList.size()/2)
{
quickSortForMedian(nodeList,index,i+1,right);//只需要排序右边就可以了
}else{
quickSortForMedian(nodeList,index,left,i-1);//只需要排序左边就可以了
}
// for (Node node : nodeList) {
// System.out.println(node.getData(index));
// }
}
}
public class Node implements Comparable<Node>{
public double[] data;//树上节点的数据 是一个多维的向量
public double distance;//与当前查询点的距离 初始化的时候是没有的
public Node left,right,parent;//左右子节点 以及父节点
public int dim=-1;//维度 建立树的时候判断的维度
public Node(double[] data)
{
this.data=data;
}
/**
* 返回指定索引上的数值
* @param index
* @return
*/
public double getData(int index)
{
if(data==null || data.length<=index)
return Integer.MIN_VALUE;
return data[index];
}
@Override
public int compareTo(Node o) {
if(this.distance>o.distance)
return 1;
else if(this.distance==o.distance)
return 0;
else return -1;
}
/**
* 计算距离 这里返回欧式距离
* @param that
* @return
*/
public double computeDistance(Node that)
{
if(this.data==null || that.data==null || this.data.length!=that.data.length)
return Double.MAX_VALUE;//出问题了 距离最远
double d=0;
for(int i=0;i<this.data.length;i++)
{
d+=Math.pow(this.data[i]-that.data[i], 2);
}
return Math.sqrt(d);
}
public String toString()
{
if(data==null || data.length==0)
return null;
StringBuilder sb=new StringBuilder();
for(int i=0;i<data.length;i++)
sb.append(data[i]+" ");
sb.append(" d:"+this.distance);
return sb.toString();
}
}
参考文献:
[1]李航.统计学习方法
统计学习方法学习(四)--KNN及kd树的java实现的更多相关文章
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 统计学习方法笔记(KNN)
k近邻法(k-nearest neighbor,k-NN) 输入:实例的特征向量,对应于特征空间的点:输出:实例的类别,可以取多类. 分类时,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预 ...
- 【分类算法】K近邻(KNN) ——kd树(转载)
K近邻(KNN)的核心算法是kd树,转载如下几个链接: [量化课堂]一只兔子帮你理解 kNN [量化课堂]kd 树算法之思路篇 [量化课堂]kd 树算法之详细篇
- 统计学习方法——第四章朴素贝叶斯及c++实现
1.名词解释 贝叶斯定理,自己看书,没啥说的,翻译成人话就是,条件A下的bi出现的概率等于A和bi一起出现的概率除以A出现的概率. 记忆方式就是变后验概率为先验概率,或者说,将条件与结果转换. 先验概 ...
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
- 02-17 kd树
目录 kd树 一.kd树学习目标 二.kd树引入 三.kd树详解 3.1 构造kd树 3.1.1 示例 3.2 kd树搜索 3.2.1 示例 四.kd树流程 4.1 输入 4.2 输出 4.3 流程 ...
- 统计学习方法——KD树最近邻搜索
李航老师书上的的算法说明没怎么看懂,看了网上的博客,悟出一套循环(建立好KD树以后的最近邻搜索),我想应该是这样的(例子是李航<统计学习算法>第三章56页:例3.3): 步骤 结点查询标记 ...
- 李航统计学习方法(第二版)(六):k 近邻算法实现(kd树(kd tree)方法)
1. kd树简介 构造kd树的方法如下:构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对k维空间进行切分,生成子结点.在超矩形区域(结点)上选择一个坐标轴和 ...
- 统计学习方法:KNN
作者:桂. 时间:2017-04-19 21:20:09 链接:http://www.cnblogs.com/xingshansi/p/6736385.html 声明:欢迎被转载,不过记得注明出处哦 ...
随机推荐
- Spark Streaming VS Flink Streaming
引自:https://www.slideshare.net/datamantra/introduction-to-flink-streaming
- Bat脚本命令说明
命名参考 使用方式如果不知道如何使用就到cmd窗口键入help 命名名 例如:"help del" 命令名 注释 ASSOC 显示或修改文件扩展名关联. ATTRIB 显示或更改文 ...
- Platt SMO 和遗传算法优化 SVM
机器学习算法实践:Platt SMO 和遗传算法优化 SVM 之前实现了简单的SMO算法来优化SVM的对偶问题,其中在选取α的时候使用的是两重循环通过完全随机的方式选取,具体的实现参考<机器学习 ...
- 基于百度AI实现 车牌识别
前言 目前百度的AI接口相对完善,对于文字识别类的操作还需要开发者一一去尝试,去评估这效果到底是怎么的. 文字识别的接口相对简单,官方提供的SDK也集成很好,笔者只是在这上面做了一些前期性的功能数据校 ...
- 创建一个可用的简单的SpringMVC项目,图文并茂
转载麻烦注明下来源:http://www.cnblogs.com/silentdoer/articles/7134332.html,谢谢. 最近在自学SpringMVC,百度了很多资料都是比较老的,而 ...
- 关于ubuntu下qt编译显示Cannot connect creator comm socket /tmp/qt_temp.xxx/stub-socket的解决办法
今天在ubuntu下安装了qtcreator,准备测试一下是否能用,果然一测试就出问题了,简单编写后F5编译在gnome-terminal中出现 Cannot connect creator comm ...
- Hibernate缓存和状态
缓存是介于应用程序和物理数据源之间,其作用是为了降低应用程序对物理数据源访问的频次,从而提高了应用的运行性能. 缓存的介质一般是内存,所以读写速度很快.但如果缓存中存放的数据量非常大时,也会用硬盘 ...
- Chrome调试折腾记_(1)调试控制中心快捷键详解!!!
转载:http://blog.csdn.net/crper/article/details/48098625 大多浏览器的调试功能的启用快捷键都一致-按下F12;还是熟悉的味道; 或者直接 Ctrl ...
- 【quickhybrid】iOS端的项目实现
前言 18年元旦三天内和朋友突击了下,勉强是将雏形做出来了,后续的API慢慢完善.(当然了,主力还是那个朋友,本人只是初涉iOS,勉强能看懂,修修改改而已) 大致内容如下: JSBridge核心交互部 ...
- C++ qsort
使用qsort 需要包含头文件#include<algorithm> 例子: class Wooden{ public: int weight; int length; bool flag ...