深入tornado中的IOStream
IOStream对tornado的高效起了很大的作用,他封装了socket的非阻塞IO的读写操作。大体上可以这么说,当连接建立后,服务端与客户端的请求响应的读写都是基于IOStream的,也就是说:IOStream是用来处理对连接的读写,当然IOStream是异步的读写而且可以有很多花样的读写。
接下来说一下有关接收请求的大体流程:
当连接建立,服务器端会产生一个对应该连接的socket,同时将该socket封装至IOStream实例中(这代表着IOStream的初始化)。
我们知道tornado是基于IO多路复用的(就拿epoll来说),此时将socket进行register,事件为READABLE,这一步与IOStream没有多大关系。
当该socket事件发生时,也就是意味着有数据从连接发送到了系统缓冲区中,这时就需要将chunk读入到我们在内存中为其开辟的_read_buffer中,在IOStream中使用deque作为buffer。_read_buffer表示读缓冲,当然也有_write_buffer,并且在读的过程中也会检测总尺寸是否大于我们设定的最大缓冲尺寸。不管是读缓冲还是写缓冲本质上就是tornado进程开辟的一段用来存储数据的内存。
而这些chunk一般都是客户端发送的请求了,但是我们还需要对这些chunk作进一步操作,比如这个chunk中可能包含了多个请求,如何把请求分离?(每个请求首部的结束符是b'\r\n\r\n'),这里就用到read_until来分离请求并设置callback了。同时会将被分离的请求数据从_read_buffer中移除。
然后就是将callback以及他的参数(被分离的请求数据)添加至IOLoop._callbacks中,等待下一次IOLoop的执行,届时会迭代_callbacks并执行回调函数。
补充: tornado是水平触发,所以假如读完一次chunk后系统缓存区中依然还有数据,那么下一次的epoll.poll()依然会返回该socket。
在iostream中有一个类叫做:IOStream
有几个较为重要的属性:
def __init__():
self.socket = socket # 封装socket
self.socket.setblocking(False) # 设置socket为非阻塞
self.io_loop = io_loop or ioloop.IOLoop.current()
self._read_buffer = deque() # 读缓冲
self._write_buffer = deque() # 写缓冲
self._read_callback = None # 读到指定字节数据时,或是指定标志字符串时,需要执行的回调函数
self._write_callback = None # 发送完_write_buffer的数据时,需要执行的回调函数
有几个较为重要的方法
class IOStream(object):
def read_until(self, delimiter, callback):
def read_bytes(self, num_bytes, callback, streaming_callback=None):
def read_until_regex(self, regex, callback):
def read_until_close(self, callback, streaming_callback=None):
def write(self, data, callback=None):
以上所有的方法都需要一个可选的callback参数,如果该参数为None则该方法会返回一个Future对象。
以上所有的读方法本质上都是读取该socket所发送来的数据,然后当读到指定分隔符或者标记或者条件触发的时候,停止读,然后将该分隔符以及其前面的数据作为callback(如果没有callback,则将数据设置为Future对象的result)的参数,然后将callback添加至IOLoop._callbacks中。当然其中所有的"读"操作是非阻塞的!
像read_until read_until_regex 这两个方法相差不大,原理都是差不多的,都是在buffer中找指定的字符或者字符样式。
而read_bytes则是设置读取字节数,达到这些字节就会触发并运行回调函数(当然这些回调函数不是立刻运行,而是被送到ioloop中的_callbacks中),该方法主要是用来读取包含content-length或者分块传输编码的具有主体信息的请求或者响应。
而read_until_close则是主要被用在非持久连接上,因为非持久连接响应的结束标志就是连接关闭。
read_bytes和read_until_close这两个方法都有streaming_callback这个参数,假如指定了该参数,那么只要read_buffer中有数据,则将数据作为参数调用该函数
就拿比较常见的read_until方法来说,下面是代码简化版:
def read_until(self, delimiter, callback=None, max_bytes=None):
future = self._set_read_callback(callback) # 可能是Future对象,也可能是None
self._read_delimiter = delimiter # 设置分隔符
self._read_max_bytes = max_bytes # 设置最大读字节数
self._try_inline_read()
return future
其中_set_read_callback会根据callback是否存在返回None或者Future对象(存在返回None,否则返回一个Future实例对象)
如果我们
再来看_try_inline_read方法的简化版:
def _try_inline_read(self):
"""
尝试从_read_buffer中读取所需数据
"""
# 查看是否我们已经在之前的读操作中得到了数据
self._run_streaming_callback() # 检查字符流回调,如果调用read_bytes和read_until_close并指定了streaming_callback参数就会造成这个回调
pos = self._find_read_pos() # 尝试在_read_buffer中找到分隔符的位置。找到则返回分隔符末尾所处的位置,如果不能,则返回None。
if pos is not None:
self._read_from_buffer(pos)
return
self._check_closed() # 检查当前IOStream是否关闭
pos = self._read_to_buffer_loop() # 从系统缓冲中读取一个chunk,检查是否含有分隔符,没有则继续读取一个chunk,合并两个chunk,再次检查是否函数分隔符…… 如果找到了分隔符,会返回分隔符末尾在_read_buffer中所处的位置
if pos is not None: # 如果找到了分隔符,
self._read_from_buffer(pos) # 将所需的数据从_read_buffer中移除,并将其作为callback的参数,然后将callback封装后添加至IOLoop._callbacks中
return
# 没找到分隔符,要么关闭IOStream,要么为该socket在IOLoop中注册事件
if self.closed():
self._maybe_run_close_callback()
else:
self._add_io_state(ioloop.IOLoop.READ)
上面的代码被我用空行分为了三部分,每一部分顺序的对应下面每一句话
分析该方法:
1 首先在_read_buffer第一项中找分隔符,找到了就将分隔符以及其前的数据从_read_buffer中移除并将其作为参数传入回调函数,没找到就将第二项与第一项合并然后继续找……;
2 如果在_read_buffer所有项中都没找到的话就把系统缓存中的数据读取至_read_buffer,然后合并再次查找,
3 如果把系统缓存中的数据都取完了都还没找到,那么就等待下一次该socket发生READ事件后再找,这时的找则就是:将系统缓存中的数据读取到_read_buffer中然后找,也就是执行第2步。
来看一看这三部分分别调用了什么方法:
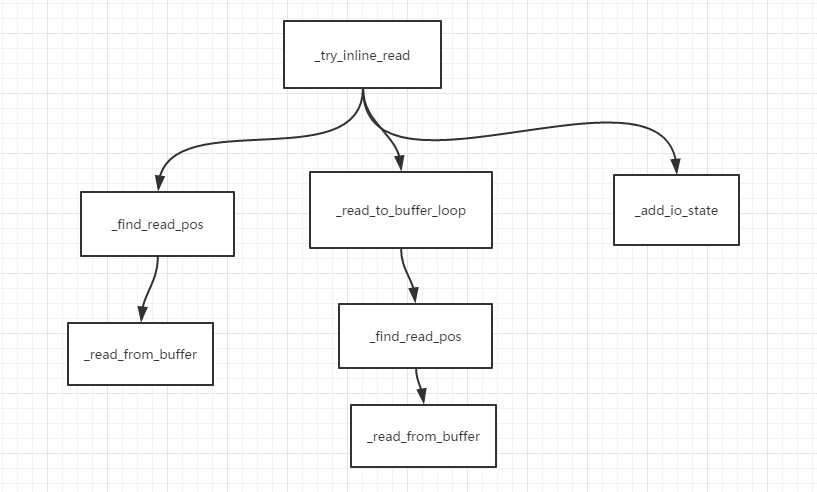
第一部分中的_find_read_pos以及_read_from_buffer
前者主要是在_read_buffer中查找分隔符,并返回分隔符的位置,后者则是将分隔符以及分隔符前面的所有数据从_read_buffer中取出并将其作为callback的参数,然后将callback封装后添加至IOLoop._callbacks中
来看_find_read_pos方法的简化版:
def _find_read_pos(self): # 尝试在_read_buffer中寻找分隔符。找到则返回分隔符末尾所处的位置,如果不能,则返回None。
if self._read_delimiter is not None:
if self._read_buffer: # 查看_read_buffer中是否有之前未处理的数据
while True:
loc = self._read_buffer[0].find(self._read_delimiter) # 查找分隔符所出现的首部位置
if loc != -1: # 在_read_buffer的首项中找到了
delimiter_len = len(self._read_delimiter)
self._check_max_bytes(self._read_delimiter, loc + delimiter_len)
return loc + delimiter_len # 分隔符末尾的位置
if len(self._read_buffer) == 1:
break
_double_prefix(self._read_buffer)
self._check_max_bytes(self._read_delimiter, len(self._read_buffer[0]))
return None
_find_read_pos
def _read_from_buffer(self, pos): # 将所需的数据从_read_buffer中移除,并将其作为callback的参数,然后将callback封装后添加至IOLoop._callbacks中
self._read_bytes = self._read_delimiter = self._read_regex = None
self._read_partial = False
self._run_read_callback(pos, False)
_read_from_buffer
来看_run_read_callback源码简化版:
def _run_read_callback(self, size, streaming):
if streaming:
callback = self._streaming_callback
else:
callback = self._read_callback
self._read_callback = self._streaming_callback = None
if self._read_future is not None: # 这里将_read_future进行set_result
assert callback is None
future = self._read_future
self._read_future = None
future.set_result(self._consume(size))
if callback is not None:
assert (self._read_future is None) or streaming
self._run_callback(callback, self._consume(size)) # 将后者作为前者的参数,然后将前者进行封装后添加至IOLoop._callbacks中 来看_consume的源码:
def _consume(self, loc): # 将self._read_buffer 的首项改为 原首项[loc:] ,然后返回 原首项[:loc]
if loc == 0:
return b""
_merge_prefix(self._read_buffer, loc) # 将双端队列(deque)的首项调整为指定大小。
self._read_buffer_size -= loc
return self._read_buffer.popleft() 来看_run_callback源码简化版:
def _run_callback(self, callback, *args):# 将callback封装后添加至ioloop._callbacks中
def wrapper():
self._pending_callbacks -= 1
try:
return callback(*args)
finally:
self._maybe_add_error_listener()
with stack_context.NullContext():
self._pending_callbacks += 1
self.io_loop.add_callback(wrapper) # 将callback添加至IOLoop._callbacks中
_run_read_callback
这里面还用到一个很有意思的函数:_merge_prefix ,这个函数的作用就是将deque的首项调整为指定大小
def _merge_prefix(deque, size):
"""Replace the first entries in a deque of strings with a single
string of up to size bytes. >>> d = collections.deque(['abc', 'de', 'fghi', 'j'])
>>> _merge_prefix(d, 5); print(d)
deque(['abcde', 'fghi', 'j']) Strings will be split as necessary to reach the desired size.
>>> _merge_prefix(d, 7); print(d)
deque(['abcdefg', 'hi', 'j']) >>> _merge_prefix(d, 3); print(d)
deque(['abc', 'defg', 'hi', 'j']) >>> _merge_prefix(d, 100); print(d)
deque(['abcdefghij'])
"""
if len(deque) == 1 and len(deque[0]) <= size:
return
prefix = []
remaining = size
while deque and remaining > 0:
chunk = deque.popleft()
if len(chunk) > remaining:
deque.appendleft(chunk[remaining:])
chunk = chunk[:remaining]
prefix.append(chunk)
remaining -= len(chunk)
if prefix:
deque.appendleft(type(prefix[0])().join(prefix))
if not deque:
deque.appendleft(b"")
_merge_prefix
第二部分的_read_to_buffer_loop
来看_read_to_buffer_loop简化版:
系统缓冲中的data可能十分长,为了查找指定的字符,我们应该先读一个chunk,检查其中是否有指定的字符,若有则返回分隔符末尾所处的位置
若没有则继续读第二个chunk,然后将这两个chunk合并(多字节分隔符(例如“\ r \ n”)可能跨读取缓冲区中的两个块),重复查找过程 def _read_to_buffer_loop(self):
try:
next_find_pos = 0
self._pending_callbacks += 1
while not self.closed():
if self._read_to_buffer() == 0: # 从系统缓冲中读一个chunk并将其添加至_read_buffer中,然后返回chunk的大小,如果无数据则返回0
break
self._run_streaming_callback()
if self._read_buffer_size >= next_find_pos: # _read_buffer_size 表示_read_buffer的大小
pos = self._find_read_pos() # 尝试在_read_buffer中寻找分隔符。找到则返回分隔符末尾所处的位置,如果不能,则返回None。
if pos is not None:
return pos
next_find_pos = self._read_buffer_size * 2
return self._find_read_pos()
finally:
self._pending_callbacks -= 1
_read_to_buffer_loop
第三部分_add_io_state,该函数和ioloop异步相关
def _add_io_state(self, state):
if self.closed(): # 连接已经关闭
return
if self._state is None:
self._state = ioloop.IOLoop.ERROR | state
with stack_context.NullContext():
self.io_loop.add_handler(self.fileno(), self._handle_events, self._state) # 为对应socket的文件描述符添加事件及其处理函数,
elif not self._state & state:
self._state = self._state | state
self.io_loop.update_handler(self.fileno(), self._state) # self._handle_events 是根据events选择对应的处理函数,在这里我们假设处理函数是_handle_read
def _handle_read(self):
try:
pos = self._read_to_buffer_loop()
except UnsatisfiableReadError:
raise
except Exception as e:
gen_log.warning("error on read: %s" % e)
self.close(exc_info=True)
return
if pos is not None:
self._read_from_buffer(pos)
return
else:
self._maybe_run_close_callback()
_add_io_state
参考:
http://www.nowamagic.net/academy/detail/13321051
深入tornado中的IOStream的更多相关文章
- 深入tornado中的TCPServer
1 梳理: 应用层的下一层是传输层,而http协议一般是使用tcp的,所以实现tcp的重要性就不言而喻. 由于tornado中实现了ioloop这个反应器以及iostream这个对连接的异步读写,所以 ...
- 深入tornado中的http1connection
前言 tornado中http1connection文件的作用极其重要,他实现了http1.x协议. 本模块基于gen模块和iostream模块实现异步的处理请求或者响应. 阅读本文需要一些基础的ht ...
- 在 tornado 中异步无阻塞的执行耗时任务
在 tornado 中异步无阻塞的执行耗时任务 在 linux 上 tornado 是基于 epoll 的事件驱动框架,在网络事件上是无阻塞的.但是因为 tornado 自身是单线程的,所以如果我们在 ...
- Tornado 中的 get() 或 post() 方法
---恢复内容开始--- Tornado 中的 get() 或 post() 方法 请求处理程序和请求参数 Tornado 的 Web 程序会将 URL 或者 URL 范式映射到 tornado.we ...
- tornado中使用torndb,连接数过高的问题
问题背景 最近新的产品开发中,使用了到了Tornado和mysql数据库.但在基本框架完成之后,我在开发时候发现了一个很奇怪的现象,我在测试时,发现数据库返回不了结果,于是我在mysql中输入show ...
- 在tornado中使用celery实现异步任务处理之中的一个
一.简单介绍 tornado-celery是用于Tornado web框架的非堵塞 celeryclient. 通过tornado-celery能够将耗时任务增加到任务队列中处理, 在celery中创 ...
- 深入tornado中的协程
tornado使用了单进程(当然也可以多进程) + 协程 + I/O多路复用的机制,解决了C10K中因为过多的线程(进程)的上下文切换 而导致的cpu资源的浪费. tornado中的I/O多路复用前面 ...
- 基于python3.x,使用Tornado中的torndb模块操作数据库
目前Tornado中的torndb模块是不支持python3.x,所以需要修改部分torndb源码即可正常使用 1.开发环境介绍 操作系统:win8(64位),python版本:python3.6(3 ...
- Tornado 中 PyMongo Motor MongoEngine 的性能测试
最近在使用 Tornado 开发 API,数据库选择了 MongoDB,因为想使用 Geo 搜索的特性.Python 可供选择的 MongoDB Drivers 可以在官网查找. 在这些 Driver ...
随机推荐
- 使用Visual Studio 2017作为Linux C++开发工具
Visual Studio 2017 微软的宇宙第一IDE Visual Studio 2017正式版出来了,地址是:https://www.visualstudio.com/vs/whatsnew/ ...
- UIBeaierPath 与 CAShapeLayer
CAShapeLayer是基于贝塞尔曲线而存在的, 如果没有贝塞尔曲线提供路径来画出图形, CAShapeLayer就没有存在的意义, CAShapeLayer可以使得不用在 drawRect:方 ...
- SQL_Join 小总结
原文出自 :http://www.nowamagic.net/librarys/veda/detail/936 对于SQL的Join,在学习起来可能是比较乱的.我们知道,SQL的Join语法有很多in ...
- ansj 2.0.7 错误例子分析
我在做一个solr的项目,分词选定了ansj分词. 选择ansj的原因: 1)身边若干朋友的念叨,说是效果不错 2)网上看了若干评论,说是不错 3)自己尝试了一些case,觉得确实不错. 好了,项目中 ...
- Linux系统常用命令总结
1. 最关键的命令 manecho 2. 目录文件操作命令 ls: 查看目录下的文件信息或文件信息dir:pwd: 打印当前路径cd:改变路径mkdir:创建路径rmdir:删除路径cp:拷贝文件或目 ...
- C# 在PDF中创建和填充域
C# 在PDF中创建和填充域 众所周知,PDF文档通常是不能编辑和修改的.如果用户需要在PDF文档中签名或者填写其他内容时,就需要PDF文档中有可编辑的域.开发者也经常会遇到将数据以编程的方式填充到P ...
- 读书笔记 effective c++ Item 34 区分接口继承和实现继承
看上去最为简单的(public)继承的概念由两个单独部分组成:函数接口的继承和函数模板继承.这两种继承之间的区别同本书介绍部分讨论的函数声明和函数定义之间的区别完全对应. 1. 类函数的三种实现 作为 ...
- 【G】开源的分布式部署解决方案文档 - 手动安装
G.系列导航 [G]开源的分布式部署解决方案 - 导航 序言 因各种原因,决定先写使用文档.也证明下项目没有太监.至于安装过程复杂,是因为还没有做一键安装,这个现阶段确实没精力. 项目进度 (点击图片 ...
- iOS开发之CALayer
1. 概述 在iOS中,你能看得见摸得着的东西基本上都是UIView,比如一个按钮.一个文本标签.一个文本输入框.一个图标等等,这些都是UIView,其实UIView之所以能显示在屏幕 ...
- Memcache存储机制与指令汇总
1.memcache基本简介 memcached是高性能的分布式内存缓存服务器.一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度.提高可扩展性. Memcach ...