webmagic爬取渲染网站
最近突然得知之后的工作有很多数据采集的任务,有朋友推荐webmagic这个项目,就上手玩了下。发现这个爬虫项目还是挺好用,爬取静态网站几乎不用自己写什么代码(当然是小型爬虫了~~|)。好了,废话少说,以此随笔记录一下渲染网页的爬取过程首先找到一个js渲染的网站,这里直接拿了学习文档里面给的一个网址,http://angularjs.cn/
打开网页是这样的
查看源码是这样的
源码这么少,不用说肯定是渲染出来的了,随便搜了一条记录,果然源码里面找不到结果
那就开始解析网址了,从浏览器开发者工具里面发现了这么些请求记录
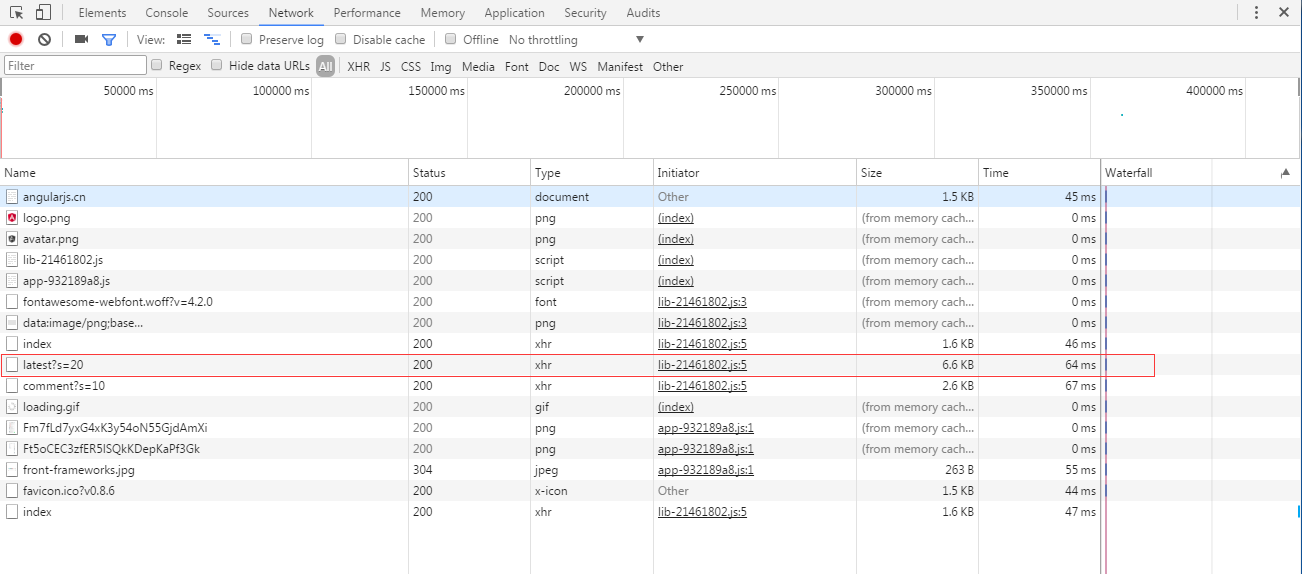
就直接从得到的数据量最大的请求开始查看,如上红线标记的。从xhr看出这是个ajax请求来的数据,打开请求的数据是这样的
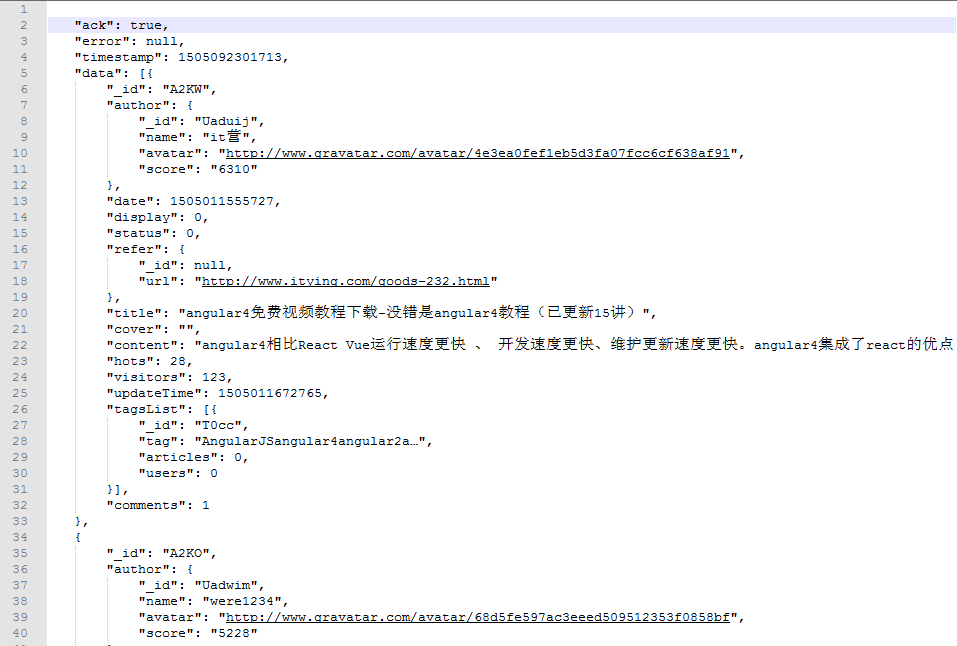
从网页上找一条源码里面找不到的记录,放在这个json数据里面搜索一下,运气还是不错的,搜索到了
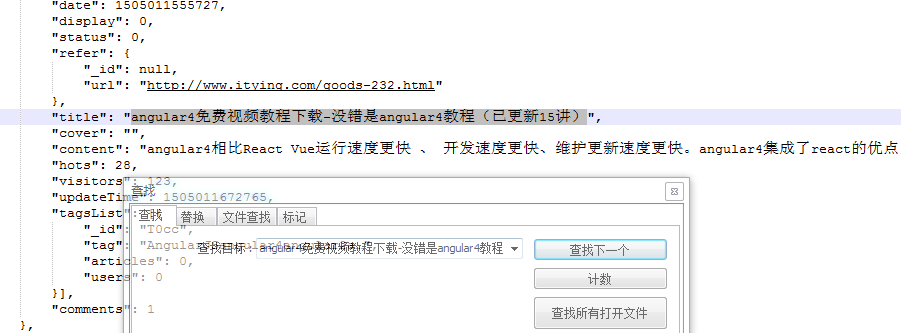
那不用说,就是它了!!接下来直接解析这个json就能拿到所有渲染后的链接了。
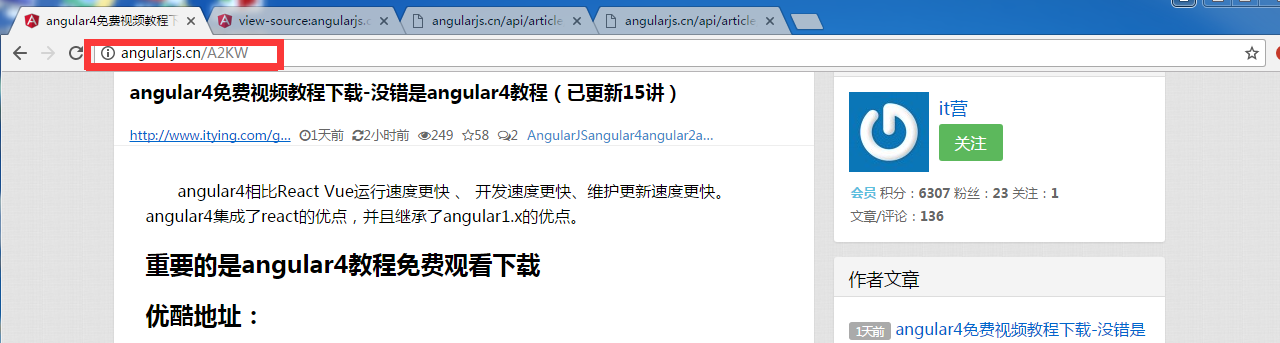
从网页直接点击一个链接进入,发现链接是这样的:
然后回到json文件,找到这个标题
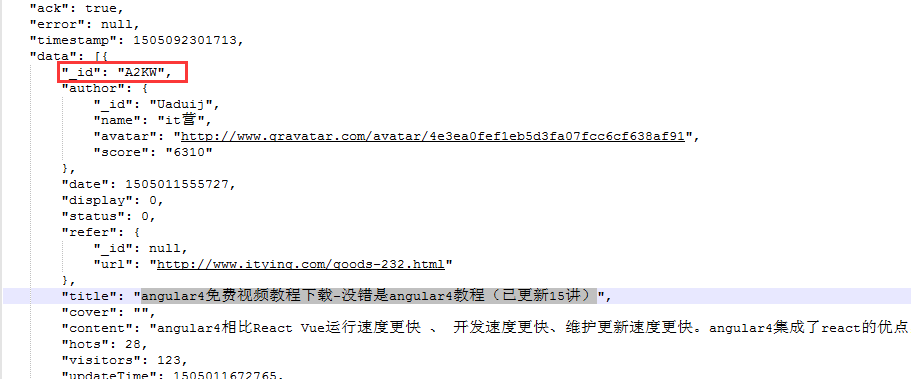
找到一个很了不起的东西!就是那个id,它就是链接后面带的。大胆推测,所有链接都是这个尿性!!(事实上我多点了几个链接看才敢确认这个尿性)
接下来就好办了,写代码解析这个json数据,然后拼凑出所有链接加入爬取队列爬取就行了。
结果发现通过首页链接点进去的下级链接,还是js渲染的。。。
没办法,拿着链接请求继续分析
得到这么些请求数据:
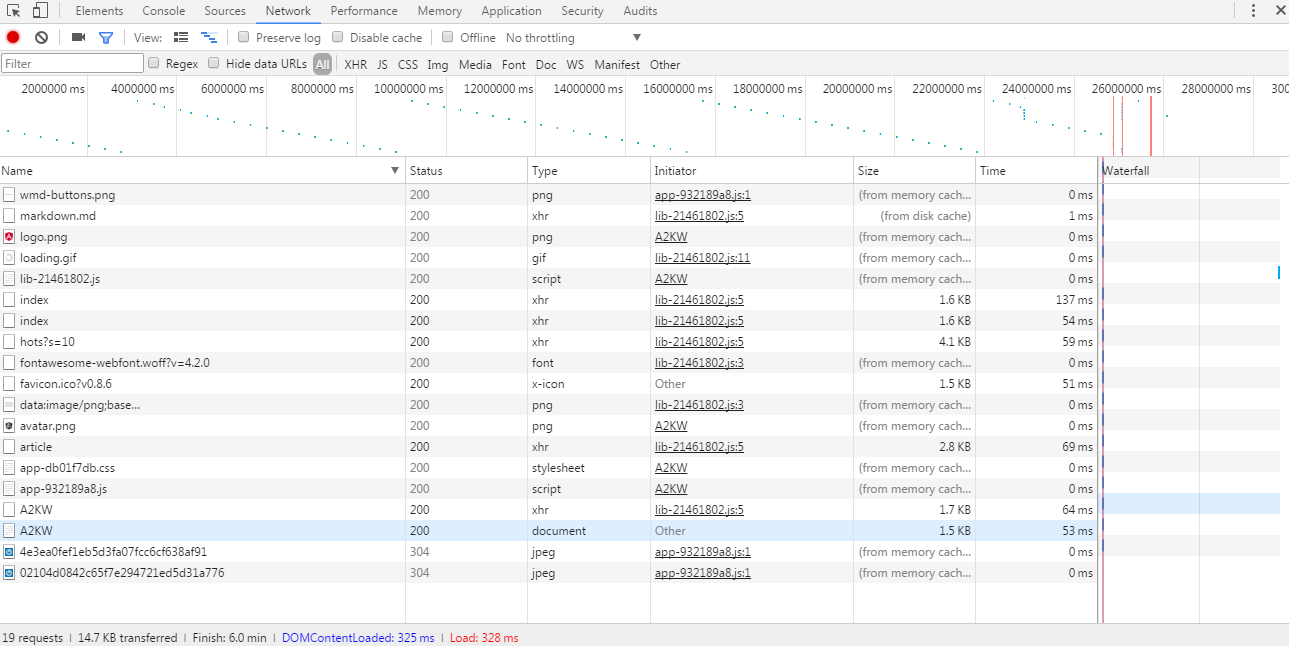
直接看到xhr栏,也就是ajax请求的数据
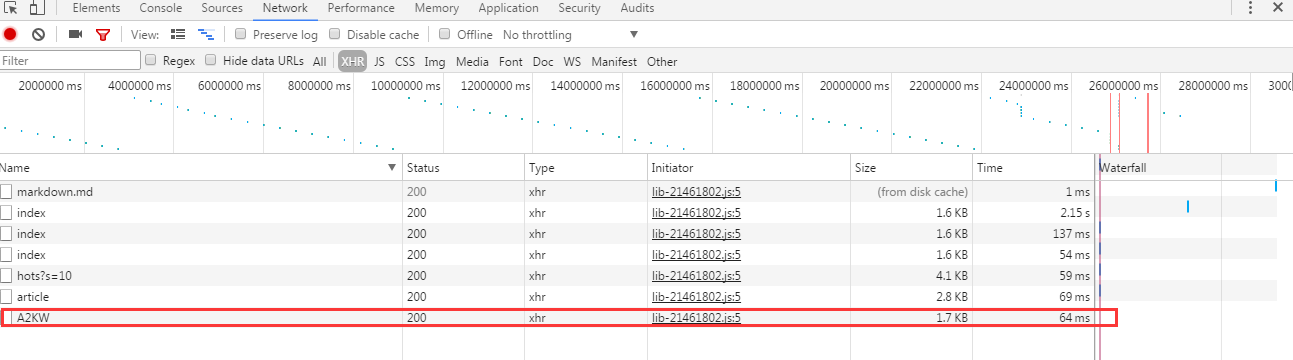
依旧从大到小查看json数据,和页面的内容匹配,直到第三个才找到正确的。++|
然后得到了最终数据的请求链接:http://angularjs.cn/api/article/A2KW
接下来就可以写代码了:
public class SpiderTest implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
// 先从浏览器中分析出隐藏请求可得出以下匹配规则
private static final String URLRULE = "http://angularjs\\.cn/api/article/latest.*";
private static String firstUrl = "http://angularjs.cn/api/article/";
@Override
public Site getSite() {
// TODO Auto-generated method stub
return site;
}
@Override
public void process(Page page) {
// TODO Auto-generated method stub
/**
* 筛选出所有符合条件的url,手动添加到爬取队列。
*/
if (page.getUrl().regex(URLRULE).match()) {
//通过jsonpath得到json数据中的id内容,之后再拼凑待爬取链接
List<String> endUrls = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(endUrls)) {
for (String endUrl : endUrls) {
page.addTargetRequest(firstUrl + endUrl);
}
}
} else {
//通过jsonpath从爬取到的json数据中提取出id和content内容
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
}
}
@Test
public void test(){
Spider.create(new SpiderTest()).addUrl("http://angularjs.cn/api/article/latest?s=20").run();
}
}
至此一个渲染的网页就爬取下来了。over
webmagic爬取渲染网站的更多相关文章
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 网络爬虫 002 (入门) 爬取一个网站之前,要了解的知识
网站站点的背景调研 1. 检查 robots.txt 网站都会定义robots.txt 文件,这个文件就是给 网络爬虫 来了解爬取该网站时存在哪些限制.当然了,这个限制仅仅只是一个建议,你可以遵守,也 ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- 利用python的requests和BeautifulSoup库爬取小说网站内容
1. 什么是Requests? Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库. 它比urllib更加方便,可以节约 ...
随机推荐
- github 或者gitlab 设置添加SSH
克隆项目二种方式: 1. 使用https url克隆, 复制https url 然后到 git clone https-url 2.使用 SSH url 克隆却需要在克隆之前先配置和添加好 SSH ...
- hdu 6047 Maximum Sequence(贪心)
Description Steph is extremely obsessed with "sequence problems" that are usually seen on ...
- list集合为空或为null的区别
简述 判断一个list集合是否为空,我们的惯性思维是判断list是否等于null即可,但是在Java中,list集合为空还是为null,这是两码事. 新建一个list对象,默认值是空,而非null: ...
- 单页面应用(spa)引入百度地图(Cannot read property 'dc' of undefined)
难点介绍 引入百度地图的时候,用原生的获取不到dom节点. ( var mapEle = document.getElementById(testApi): var map = new BMap.Ma ...
- 【前端,干货】react and redux教程学习实践(二)。
前言 这篇博文接 [前端]react and redux教程学习实践,浅显易懂的实践学习方法. ,上一篇简略的做了一个redux的初级demo,今天深入的学习了一些新的.有用的,可以在生产项目中使用的 ...
- Mybatis 调用存储过程,使用Map进行输入输出参数的传递
做个记录,以备后用 java代码: public String texuChange() throws Exception { try { ...
- 微信小程序(有始有终,全部代码)开发---跑步App+音乐播放器 Bug修复
开篇语 昨晚发了一篇: <简年15: 微信小程序(有始有终,全部代码)开发---跑步App+音乐播放器 > 然后上午起来吃完午饭之后,我就准备继续开工的,但是突然的,想要看B站.然后在一股 ...
- Can not issue data manipulation statements with executeQuery().解决的方法
query是查询用的,而update是插入和更新,删除修改用的. executeQuery()语句是用于产生单个结果集的语句,如select语句,在什么情况下用,当你的数据库已经保存了数据后,要进行查 ...
- jQueryGantt与DHTMLX-Gantt的对比
对比内容|jQueryGantt|DHTMLX-Gantt 本地化(语言)|封装了语言包,(仅英语)要想改变要重新编写|支持多种语言包,并且形成了完整的css文件 皮肤|只有一套现成的皮肤,逍遥该表喲 ...
- 关于DB2版本、补丁升级和回退的总结[转载]
首先介绍几个概念 RELEASE的升级就是版本升级,例如9.1→9.5→9.7→10.1,可以跳版本升级,例如9.1→10.1 FIX PACK简称FP,就是打补丁,例如9.7.1→9.7.2,每个版 ...