大数据学习(5)MapReduce切片(Split)和分区(Partitioner)
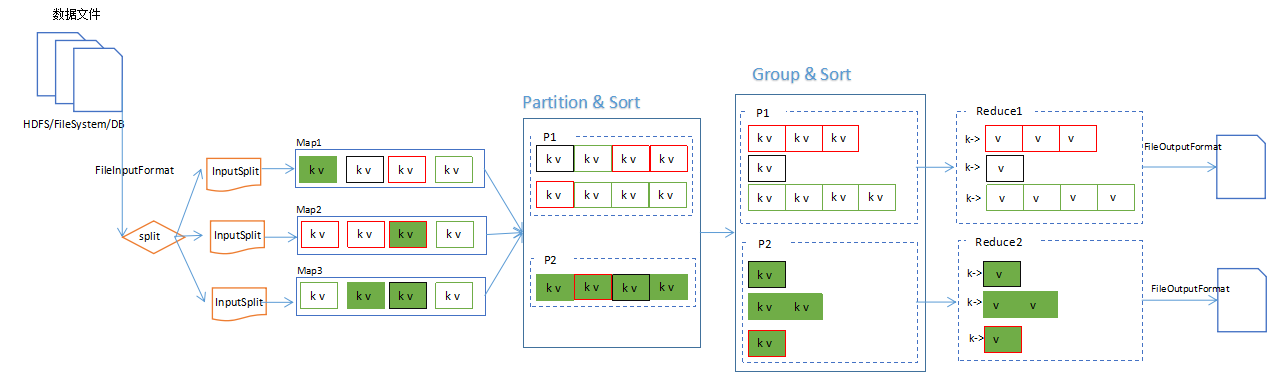
MapReduce中,分片、分区、排序和分组(Group)的关系图:
分片大小
对于HDFS中存储的一个文件,要进行Map处理前,需要将它切分成多个块,才能分配给不同的MapTask去执行。 分片的数量等于启动的MapTask的数量。默认情况下,分片的大小就是HDFS的blockSize。
Map阶段的对数据文件的切片,使用如下判断逻辑:
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
blockSize:默认大小是128M(dfs.blocksize)
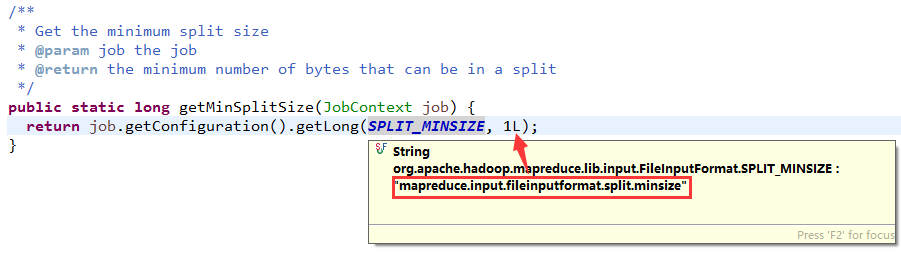
minSize:默认是1byte(mapreduce.input.fileinputformat.split.minsize):
maxSize:默认值是Long.MaxValue(mapreduce.input.fileinputformat.split.minsize)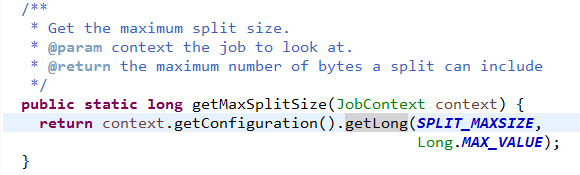
由此可以看出两个可以自定义的值(minSize和maxSize)与blockSize之间的关系如下:
当blockSize位于minSize和maxSize 之间时,认blockSize:

当maxSize小于blockSize时,认maxSize:
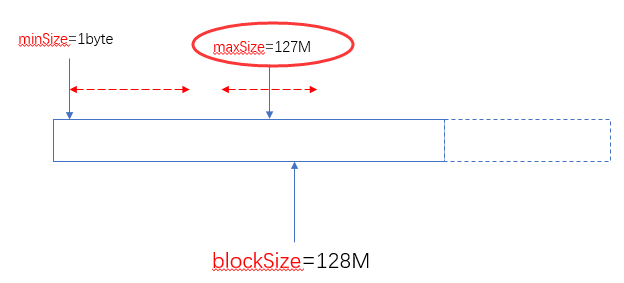
当minSize大于blockSize时,认minSize:
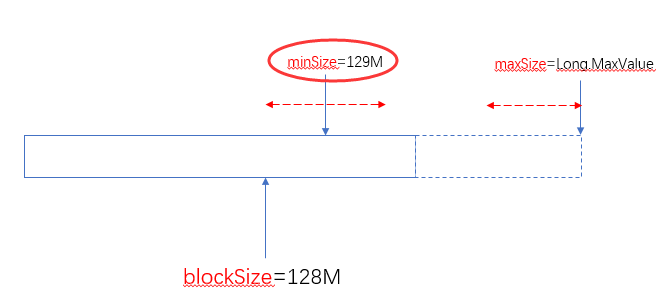
另外一个极端的情况,maxSize小于minSize时,认minsize,可以理解为minSize的优先级比maxSize大:
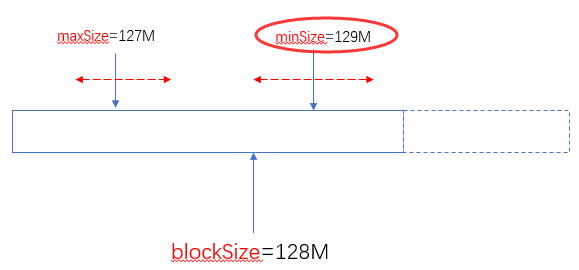
实际使用中,建议不要去修改maxSize,通过调整minSize(使他大于blockSize)就可以设定分片(Split)的大小了。
总之通过minSize和maxSize的来设置切片大小,使之在blockSize的上下自由调整。
什么时候需要调整分片的大小
首先要明白,HDFS的分块其实是指HDFS在存储文件时的一个参数。而这里分片的大小是为了业务逻辑用的。分片的大小直接影响到MapTask的数量,你可以根据实际的业务需求来调整分片的大小。
分区
在Reduce过程中,可以根据实际需求(比如按某个维度进行归档,类似于数据库的分组),把Map完的数据Reduce到不同的文件中。分区的设置需要与ReduceTaskNum配合使用。比如想要得到5个分区的数据结果。那么就得设置5个ReduceTask。
自定义Partitioner:
public class URLResponseTimePartitioner extends Partitioner<Text, LongWritable>{
@Override
public int getPartition(Text key, LongWritable value, int numPartitions) {
String accessPath = key.toString();
if(accessPath.endsWith(".do")) {
return 0;
}
return 1;
}
}
然后可以在job中设置partitioner:
job.setPartitionerClass(URLResponseTimePartitioner.class);
//URLResponseTimePartitioner returns 1 or 0,so num of reduce task must be 2
job.setNumReduceTasks(2);
两个分区会产生两个最终结果文件:
[root@centos01 ~]# hadoop fs -ls /access/log/response-time
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found items
-rw-r--r-- root supergroup -- : /access/log/response-time/_SUCCESS
-rw-r--r-- root supergroup -- : /access/log/response-time/part-r-
-rw-r--r-- root supergroup -- : /access/log/response-time/part-r-
其中00000中存放着.do的统计结果,00001则存放其他访问路径的统计结果。
[root@centos01 ~]# hadoop fs -cat /access/log/response-time/part-r- |more
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
//MyAdmin/scripts/setup.php 3857
//css/console.css 356
//css/result_html.css 628
//images/male.png 268
//js/tooltipster/css/plugins/tooltipster/sideTip/themes/tooltipster-sideTip-borderless.min.css 1806
//js/tooltipster/css/tooltipster.bundle.min.css 6495
//myadmin/scripts/setup.php 3857
//phpMyAdmin/scripts/setup.php 3857
//phpmyadmin/scripts/setup.php 3857
//pma/scripts/setup.php 3857
//search_children.js
/Dashboard.action
/Homepage.action
/My97DatePicker/WdatePicker.js
/My97DatePicker/calendar.js
/My97DatePicker/lang/zh-cn.js
/My97DatePicker/skin/WdatePicker.css
/My97DatePicker/skin/default/datepicker.css
/My97DatePicker/skin/default/img.gif
排序
要想最终结果中按某个特性排序,则需要在Map阶段,通过Key的排序来实现。
例如,想让上述平均响应时间的统计结果按降序排列,实现如下:
关键就在于这个用于OUTKey的Bean。它实现了Comparable接口,所以输出的结果就是按compareTo的结果有序。
由于这个类会作为Key,所以它的equals方法很重要,会作为,需要按实际情况重写。这里重写的逻辑是url相等则表示是同一个Key。(虽然Key相同的情况其实没有,因为之前的responseTime统计结果已经把url做了group,但是这里还是要注意有这么个逻辑。)
排序并不是依赖于key的equals!
public class URLResponseTime implements WritableComparable<URLResponseTime>{
String url;
long avgResponseTime;
public void write(DataOutput out) throws IOException {
out.writeUTF(url);
out.writeLong(avgResponseTime);
}
public void readFields(DataInput in) throws IOException {
this.url = in.readUTF();
this.avgResponseTime = in.readLong();
}
public int compareTo(URLResponseTime urt) {
return this.avgResponseTime > urt.avgResponseTime ? -1 : 1;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public long getAvgResponseTime() {
return avgResponseTime;
}
public void setAvgResponseTime(long avgResponseTime) {
this.avgResponseTime = avgResponseTime;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((url == null) ? 0 : url.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
URLResponseTime other = (URLResponseTime) obj;
if (url == null) {
if (other.url != null)
return false;
} else if (!url.equals(other.url))
return false;
return true;
}
@Override
public String toString() {
return url;
}
}
然后就简单了,在Map和Reduce分别执行简单的写和读操作就行了,没有更多的处理,依赖于Hadoop MapReduce框架自身的特点就实现了排序:
public class URLResponseTimeSortMapper extends Mapper<LongWritable,Text,URLResponseTime,LongWritable>{
//make a member property to avoid new instance every time when map function invoked.
URLResponseTime key = new URLResponseTime();
LongWritable value = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] logs = line.split("\t");
String url = logs[0];
String responseTimeStr = logs[1];
long responseTime = Long.parseLong(responseTimeStr);
this.key.setUrl(url);
this.key.setAvgResponseTime(responseTime);
this.value.set(responseTime);
context.write(this.key,this.value);
}
}
public class URLResponseTimeSortReducer extends Reducer<URLResponseTime, LongWritable, URLResponseTime, LongWritable> {
@Override
protected void reduce(URLResponseTime key, Iterable<LongWritable> values,
Context ctx) throws IOException, InterruptedException {
ctx.write(key, values.iterator().next());
}
}
参考:
Hadoop Wiki,HowManyMapsAndReduces :https://wiki.apache.org/hadoop/HowManyMapsAndReduces
大数据学习(5)MapReduce切片(Split)和分区(Partitioner)的更多相关文章
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
随机推荐
- ace_tree总结。各类问题解决办法汇集
首先讲一下怎么使用,然后讲一下出现的问题的解决办法 1.引用js和css文件 ace-extra.min.js.ace.min.css.fuelux.tree.min.js.ace-elements. ...
- java参数传值方式
java参数有值类型和引用类型两种.所以java参数的传值也就从这两个方面分析. 从内存模型来说参数传递更为直观一些,这里涉及到两种类型的内存:栈内存(stack)和堆内存(heap). 基本类 ...
- window环境下npm install node-sass报错
最近准备想用vue-cli初始化一个项目,需要sass-loader编译: 发现window下npm install node-sass和sass-loader一直报错, window 命令行中提示我 ...
- 负载均衡手段之DNS轮询
大多数域名注册商都支持对统一主机添加多条A记录,这就是DNS轮询,DNS服务器将解析请求按照A记录的顺序,随机分配到不同的IP上,这样就完成了简单的负载均衡.下图的例子是:有3台联通服务器.3台电信服 ...
- Science发表的超赞聚类算法
作者(Alex Rodriguez, Alessandro Laio)提出了一种很简洁优美的聚类算法, 可以识别各种形状的类簇, 并且其超参数很容易确定. 算法思想 该算法的假设是类簇的中心由一些局部 ...
- TFboy养成记 CNN
1/先解释下CNN的过程: 首先对一张图片进行卷积,可以有多个卷积核,卷积过后,对每一卷积核对应一个chanel,也就是一张新的图片,图片尺寸可能会变小也可能会不变,然后对这个chanel进行一些po ...
- 自定义控件,上图下字的Button,图片任意指定大小
最近处在安卓培训期,把自己的所学写成博客和大家分享一下,今天学的是这个自定义控件,上图下字的Button安卓自带,但是苦于无法设置图片大小(可以在代码修改),今天自己做了一个,首先看一下效果图,比较实 ...
- centos6.5 短信猫部署发短信
本文为在centos下部署短信猫发短信使用,以下为具体环境和步骤说明,欢迎留言! 一.环境说明 服务器:centos6.5 x64 依赖包:lockdev-1.0.1-18.el6.x86_64.rp ...
- 计算生日是星期几-soj
编写一个程序,只要输入年月日,就能回答那天是星期几. 输入一个日期,包括年.月.日.(一组测试数据) 输出这个日期是星期几. 输入: 1 1 1 2 1 1 2006 7 10 输出: Monday ...
- 永中DCS文档转换服务其它产品对比
一.利用DCOM配置直接操作Office文件 作用:读取文件内容,导出Html文件 优势:免费 劣势:1.服务器上必须安装Office软件 2.配置麻烦,正如微软所说,读取Office不是这么干的. ...