pytorch实现VAE
一、VAE的具体结构
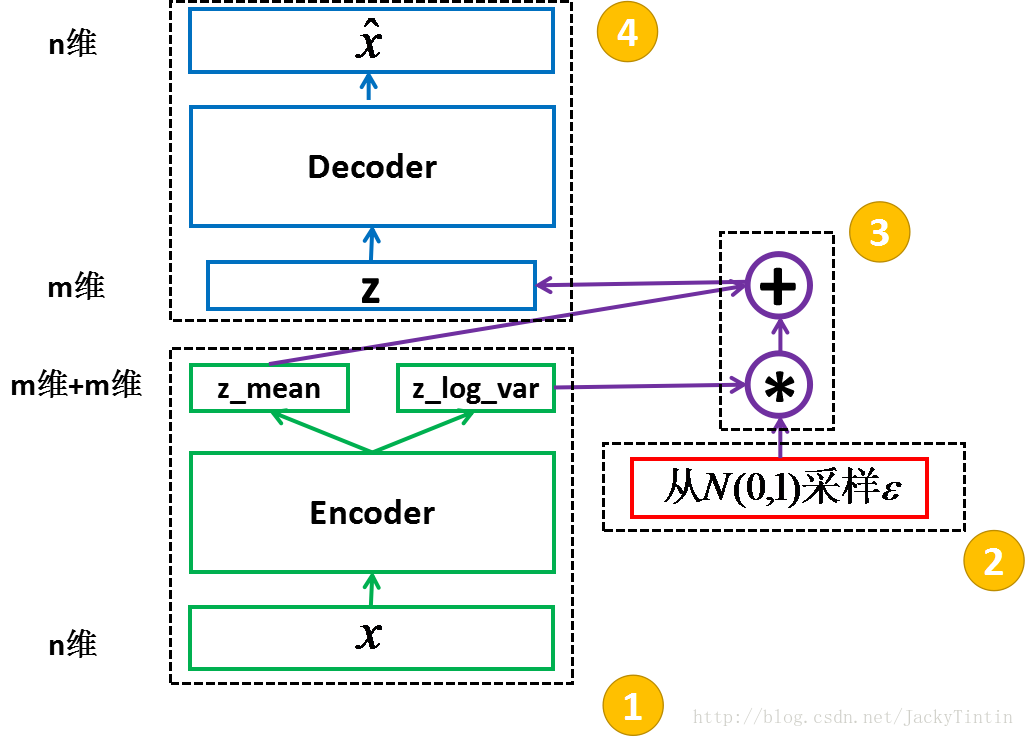
二、VAE的pytorch实现
1加载并规范化MNIST
import相关类:
from __future__ import print_function
import argparse
import torch
import torch.utils.data
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torchvision import datasets, transforms
设置参数:
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=128, metavar='N',
help='input batch size for training (default: 128)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='enables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
print(args) #Sets the seed for generating random numbers. And returns a torch._C.Generator object.
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
输出结果:
Namespace(batch_size=128, cuda=True, epochs=10, log_interval=10, no_cuda=False, seed=1)
下载数据集到./data/目录下:
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
trainset = datasets.MNIST('../data', train=True, download=True,transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(
trainset,
batch_size=args.batch_size, shuffle=True, **kwargs)
testset= datasets.MNIST('../data', train=False, transform=transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(
testset,
batch_size=args.batch_size, shuffle=True, **kwargs)
image, label = trainset[0]
print(len(trainset))
print(image.size())
image, label = testset[0]
print(len(testset))
print(image.size())
输出结果:
60000
torch.Size([1, 28, 28])
10000
torch.Size([1, 28, 28])
2定义VAE
首先我们介绍x.view方法:
x = torch.randn(4, 4)y = x.view(16)z = x.view(-1, 16) # the size -1 is inferred from other dimensions
print(x)
print(y)
print(z)
输出结果:
1.6154 1.1792 0.6450 1.2078
-0.4741 1.2145 0.8381 2.3532
0.2070 -0.9054 0.9262 0.6758
1.2613 0.5196 -1.7125 -0.0519
[torch.FloatTensor of size 4x4]
1.6154
1.1792
0.6450
1.2078
-0.4741
1.2145
0.8381
2.3532
0.2070
-0.9054
0.9262
0.6758
1.2613
0.5196
-1.7125
-0.0519
[torch.FloatTensor of size 16]
Columns 0 to 9
1.6154 1.1792 0.6450 1.2078 -0.4741 1.2145 0.8381 2.3532 0.2070 -0.9054 Columns 10 to 15
0.9262 0.6758 1.2613 0.5196 -1.7125 -0.0519
[torch.FloatTensor of size 1x16]
然后建立VAE模型
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__() self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784) self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid() def encode(self, x):
h1 = self.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1) def reparametrize(self, mu, logvar):
std = logvar.mul(0.5).exp_()
eps = Variable(std.data.new(std.size()).normal_())
return eps.mul(std).add_(mu) def decode(self, z):
h3 = self.relu(self.fc3(z))
return self.sigmoid(self.fc4(h3)) def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparametrize(mu, logvar)
return self.decode(z), mu, logvar model = VAE()
if args.cuda:
model.cuda()
3.定义一个损失函数
reconstruction_function = nn.BCELoss()
reconstruction_function.size_average = False def loss_function(recon_x, x, mu, logvar):
BCE = reconstruction_function(recon_x, x.view(-1, 784)) # see Appendix B from VAE paper:
# Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
# https://arxiv.org/abs/1312.6114
# 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
KLD = torch.sum(KLD_element).mul_(-0.5) return BCE + KLD optimizer = optim.Adam(model.parameters(), lr=1e-3)
4.在训练数据上训练神经网络
我们只需要对数据迭代器进行循环,并将输入反馈到网络并进行优化。
for epoch in range(1, args.epochs + 1):
train(epoch)
test(epoch)
其中
def train(epoch):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = Variable(data)
if args.cuda:
data = data.cuda()
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
train_loss += loss.data[0]
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.data[0] / len(data))) print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, train_loss / len(train_loader.dataset))) def test(epoch):
model.eval()
test_loss = 0
for data, _ in test_loader:
if args.cuda:
data = data.cuda()
data = Variable(data, volatile=True)
recon_batch, mu, logvar = model(data)
test_loss += loss_function(recon_batch, data, mu, logvar).data[0] test_loss /= len(test_loader.dataset)
print('====> Test set loss: {:.4f}'.format(test_loss))
Tips:
1.直接运行pytorch examples里的代码发现library not initialized at /pytorch/torch/lib/THC/THCGeneral.c错误
解决方案:sudo rm -r ~/.nv
2.该源码实现的论文为https://arxiv.org/pdf/1312.6114.pdf
pytorch实现VAE的更多相关文章
- Pytorch入门之VAE
关于自编码器的原理见另一篇博客 : 编码器AE & VAE 这里谈谈对于变分自编码器(Variational auto-encoder)即VAE的实现. 1. 稀疏编码 首先介绍一下“稀疏编码 ...
- Variational Auto-encoder(VAE)变分自编码器-Pytorch
import os import torch import torch.nn as nn import torch.nn.functional as F import torchvision from ...
- pytorch实现DCGAN、pix2pix、DiscoGAN、CycleGAN、BEGAN以及VAE
https://github.com/sunshineatnoon/Paper-Implementations
- Pytorch 细节记录
1. PyTorch进行训练和测试时指定实例化的model模式为:train/eval eg: class VAE(nn.Module): def __init__(self): super(VAE, ...
- 【转载】 Pytorch 细节记录
原文地址: https://www.cnblogs.com/king-lps/p/8570021.html ---------------------------------------------- ...
- (转)Awesome PyTorch List
Awesome-Pytorch-list 2018-08-10 09:25:16 This blog is copied from: https://github.com/Epsilon-Lee/Aw ...
- (转) The Incredible PyTorch
转自:https://github.com/ritchieng/the-incredible-pytorch The Incredible PyTorch What is this? This is ...
- pytorch实现autoencoder
关于autoencoder的内容简介可以参考这一篇博客,可以说写的是十分详细了https://sherlockliao.github.io/2017/06/24/vae/ 盗图一张,自动编码器讲述的是 ...
- 库、教程、论文实现,这是一份超全的PyTorch资源列表(Github 2.2K星)
项目地址:https://github.com/bharathgs/Awesome-pytorch-list 列表结构: NLP 与语音处理 计算机视觉 概率/生成库 其他库 教程与示例 论文实现 P ...
随机推荐
- 推广技巧:新站要如何推广引流做到日IP10000?
一.回复高人气帖子插楼推广 1.找高人气的帖子在二楼或者二楼楼层中直接插入链接推广.虽然这种方法存活率比较低,但也算是贴吧里面最直接的有效的方法.一般我们分为三种: 1.1图中链接是一个短网址,这个是 ...
- vue.js基础知识篇(6):组件详解
第11章:组件详解 组件是Vue.js最推崇也最强大的功能之一,核心目标是可重用性. 我们把组件代码按照template.style.script的拆分方式,放置到对应的.vue文件中. 1.注册 V ...
- bam文件softclip , hardclip ,markduplicate的探究
测序产生的bam文件,有一些reads在cigar值里显示存在softclip,有一些存在hardclip,究竟softclip和hardclip是怎么判断出来的,还有是怎么标记duplicate ...
- 7.7 WPF后台代码绑定如果是属性,必须指定一下数据上下文才能实现,而函数(click)就不用
如: private bool _IsExportWithImage; /// <summary> /// 是否选择导出曲线图 /// </summary> public bo ...
- spring boot / cloud (十二) 异常统一处理进阶
spring boot / cloud (十二) 异常统一处理进阶 前言 在spring boot / cloud (二) 规范响应格式以及统一异常处理这篇博客中已经提到了使用@ExceptionHa ...
- 关于本地代码挂载到vm虚拟环境下运行
第一步: 首先你得装个 VM 虚拟机 然后新建一个Linux虚拟环境(建议CentOS镜像)(PS:至于安装此处就省略.....) 第二步:启动虚拟机配置 lnmp (这里我们可以使用 lnmp的 ...
- BootKit病毒——“异鬼Ⅱ”的前世今生
七月底,一种名为"异鬼Ⅱ"的木马在全网大肆传播.一个多月过去了,风声渐渐平息,之前本来准备专门就这个木马写一篇博客的,结果拖到现在,幸好时间隔得还不算太久.闲话不多说,回到正题. ...
- java程序的内存分配
java程序的内存分配 JAVA 文件编译执行与虚拟机(JVM)介绍 Java 虚拟机(JVM)是可运行Java代码的假想计算机.只要根据JVM规格描述将解释器移植到特定的计算机上,就能保证经过编译的 ...
- 获取url中的参数(微信开发)
alert(location.search.split('?')[1].split('&')[0].split('=')[1]); 说明:从当前URL的?号开始的字符串,以?号分割, 分割后索 ...
- 利用 VMWare 搭建随机拓扑网络
这篇文章是计算机网络上机实验课的作业. 实验任务:利用 VMWare 搭建一个由 5 个主机组成的随机拓扑的网络.要求该网络中至少有 2 个子网,两个路由器 .实验的网络拓扑图如下: 网络中有两个路由 ...