对于查询调优,你需要的不止STATISTICS IO
在我查询调优期间,STATISTICS IO会话选项是我的朋友,因为对于指定的查询,它准确告诉你有多少页已读取。每次,SQL Server从缓存池骑牛一个8K的页,它通过STATISTICS IO的输出获得记录。
通常我会建议启用STATISTICS IO来更好的理解在给定的查询里,涉及的表上有多少页被读取。而且查询调优的目标是尽可能减少这些读取页数——通过索引策略。对于查询,你数据读的越少,查询就会越快。但今天的问题如下:对于查询调优,STATISTICS IO有你需要的一切么,还是又你应该知道更多的维度?
我们来谈下客户端统计信息
另一个非常重要的选项——至少从我的角度来看——是SSMS里的客户端统计信息选项:

当对你的会话启用这个选项,SSMS会告诉你你的查询客户端处理的更多信息。下图是SSMS里一个典型的输出结果:
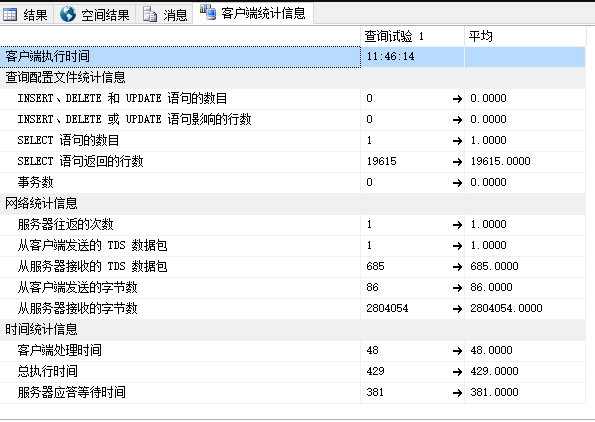
这里SSMS向你展示你的查询最后一次执行的性能指标。最重要的指标是网络统计和时间统计。网络统计信息向你展示下列信息:
- 服务器往返的次数
- 从客户端发送的 TDS 数据包
- 从服务器接收的 TDS 数据包
- 从客户端发送的字节数
- 从服务器接收的字节数
通常我会留意从服务器接收的字节数,因为用收到的信息,你很容易看到从服务器返回的信息量。当然你的结果集越大,你返回的数据越多,你的查询时间也会更长。我在客户这遇到过有返回几G数据的查询,他们还在抱怨为什么查询这么慢,额~~~~~这个……
另外时间统计信息向你展示了下列信息:
- 客户端处理时间
- 总执行时间
- 服务器应答等待时间
这里最重要的维度是客户端处理时间,因为它告诉你SSMS本身需要多长时间来处理你的查询。这里的大部分时间是SSMS用在计算和可视化结果集。同理,结果集越大,SSMS花更多的时间来可视化它,因此查询时间会更长。
小结
STATISTICS IO是查询调优的很好开始,另外我也使用来自客户统计信息的输出来更好的理解有多少数据在网络上传输,SSMS本身需要花多少时间来处理数据。
因此下次你的查询慢的时候,你可以使用客户统计信息来检查在SSMS里的时间花费。或许查询本身很快,但是SSMS需要更多的时间。
感谢关注!
原文链接
https://www.sqlpassion.at/archive/2017/03/27/do-you-need-more-than-statistics-io-for-query-tuning/
对于查询调优,你需要的不止STATISTICS IO的更多相关文章
- Tomcat系列(9)——Tomcat 6方面调优(内存,线程,IO,压缩,缓存,集群)
核心部分 内存 线程 IO 压缩 缓存 集群 一.JVM内存优化 Tomcat内存优化,包括内存大小,垃圾回收策略. Windows 下的catalina.bat,Linux 下的catalina.s ...
- 标量子查询调优SQL
fxnjbmhkk4pp4 select /*+ leading (wb,sb,qw) */ 'blocker('||wb.holding_session||':'||sb.username||')- ...
- sql查询调优之where条件排序字段以及limit使用索引的奥秘
奇怪的慢sql 我们先来看2条sql 第一条: select * from acct_trans_log WHERE acct_id = 1000000000009000757 order b ...
- 性能调优:理解Set Statistics IO输出
性能调优是DBA的重要工作之一.很多人会带着各种性能上的问题来问我们.我们需要通过SQL Server知识来处理这些问题.经常被问到的一个问题是:早上这个存储过程运行时间还是可以的,但到了晚上就很慢很 ...
- hadoop作业调优参数整理及原理(转)
1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘.这中间的过程比较复杂,并且利用到了内 ...
- hadoop作业调优参数整理及原理【转】
1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘.这中间的过程比较复杂,并且利用到了内 ...
- Mycat性能调优指南
本篇内容来自于网络 JVM调优: 内存占用分两部分:java堆内存+直接内存映射(DirectBuffer占用),建议堆内存 适度大小,直接映射内存尽可能大,两种一起占据操作系统的1/2-2/3的内存 ...
- ELASTIC SEARCH 性能调优
ELASTICSEARCH 性能调优建议 创建索引调优 1.在创建索引的使用使用批量的方式导入到ES. 2.使用多线程的方式导入数据库. 3.增加默认刷新时间. 默认的刷新时间是1秒钟,这样会产生太多 ...
- elasticsearch 了解多少,说说你们公司 es 的集群架构,索 引数据大小,分片有多少,以及一些调优手段 ?
面试官:想了解应聘者之前公司接触的 ES 使用场景.规模,有没有做过比较大 规模的索引设计.规划.调优. 解答: 如实结合自己的实践场景回答即可. 比如:ES 集群架构 13 个节点,索引根据通道不同 ...
随机推荐
- Javsssist用InsertAt()方法对语句插桩
基于上一篇的方法插桩,这一篇则是进一步的对每行的语句进行插桩. 对于存在分支的方法(例如if(){}else{}),对方法插桩的方法是不能够全部涉及到的.所以要对程序的每条语句进行插桩. 插入什么语句 ...
- PHP运算符知识点
表达式 几乎所写的任何东西都是一个表达式,简单却最精确的定义一个表达式的方式就是"任何有值的东西". 算术运算符 Php中常用的有:+.-.*./.%(取模,得到余数) 左+ - ...
- 7个原因告诉你为什么要选择一个“多模型”的数据库?-ArangoDB
ArangoDB 是一个开源的分布式原生多模型数据库 (Apache 2 license). 其理念是:利用一个引擎,一个 query 语法,一项数据库技术,以及多个数据模型,来最大力度满足项目的灵活 ...
- 原生js简单实现双向数据绑定原理
根据对象的访问器属性去监听对象属性的变化,访问器属性不能直接在对象中设置,而必须通过 defineProperty() 方法单独定义. 访问器属性的"值"比较特殊,读取或设置访问器 ...
- JavaScript 之 HelloWorld编写
HelloWorld.html 代码如下: <html><body><script type="text/javascript">documen ...
- nopCommerce 3.9 大波浪系列 之 汉化-Roxy Fileman
官网:http://www.roxyfileman.com/ 中文包:zh.json 1.将zh.json包拷贝到Nop.Admin项目中"Content\Roxy_Fileman\lang ...
- Java 枚举7常见种用法(转)
JDK1.5引入了新的类型——枚举.在 Java 中它虽然算个“小”功能,却给我的开发带来了“大”方便. 用法一:常量 在JDK1.5 之前,我们定义常量都是: public static fianl ...
- 机器学习(4)Hoeffding Inequality--界定概率边界
问题 假设空间的样本复杂度(sample complexity):随着问题规模的增长导致所需训练样本的增长称为sample complexity. 实际情况中,最有可能限制学习器成功的因素是训练数据的 ...
- 7.spark共享变量
spark共享变量 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- windows下配置cygwin和dig的环境变量
配置cygwin和dig的环境变量 打开"控制面板"("开始">"设置">"控制面板"),然后双击" ...