spark的sparkUI如何解读?
spark的sparkUI如何解读?
以spark2.1.4来做例子
Job - schedule mode
进入之后默认是进入spark job 页面
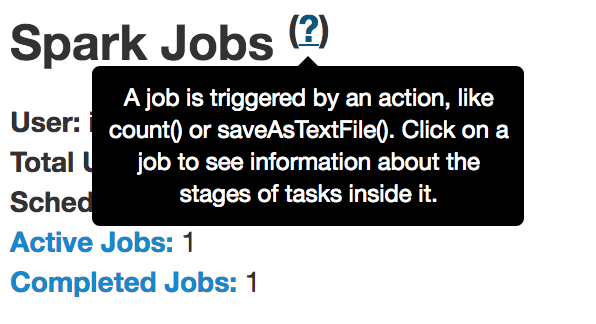
这个说明有很详细的解释,spark有两种操作算子:转换算子(transformation)和执行算子(Action)。当执行到行为算子的时候,就出发了一个Job作业,比如count()和saveAsTextFile()。
sparkJob页面头部有几个,最重要的是Schedule mode,表示的是Job的调度模型。如果多个线程调用多个并行的job,这些job就会被分配调用,这里就有个调度模型,一般是FIFO模型,先进先出模型。但是在spark0.8之后,就支持了一种FAIR模型,FAIR模型是一种公平模型,相当于每个任务轮换使用资源等,这样能使的小job能很快执行,而不用等大job完成才执行了。
Job - Event Timeline

这个就是用来表示调度job何时启动,何时结束,并且excutor何时加入。
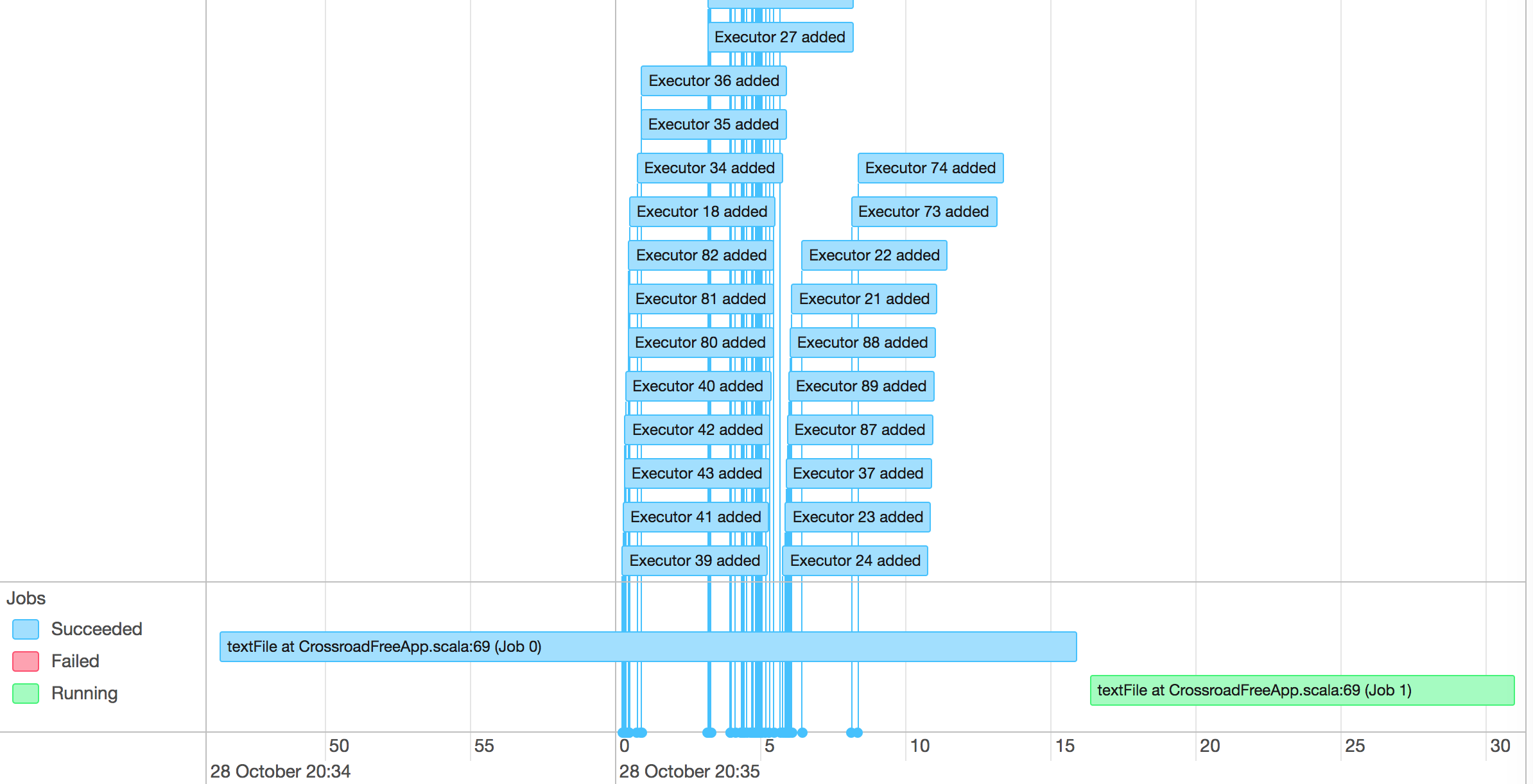
我们可以很方便看到哪些job已经运行完成,使用了多少excutor,哪些正在运行。
点击进入每个job,我们就可以看到每个job的detail
Details for Job
在这个页面我们能看到job的详情。一个job会被分为一个或者多个stage
这里也有event timeline,告诉我们这个job中每个stage执行时间。
这里多了一个DAG可视化的图
DAG
DAG图是有向无环图的意思。spark中使用有向无环图来显示流程。
DAG也是一种调度模型,在spark的作业调度中,有很多作业存在依赖关系,所以有的作业可以并行执行,有的作业不能并行执行。把这些作业的内部转向关系描绘清楚,就是一个DAG图。使用DAG图,就能很清晰看到我们的作业(RDD)哪些先执行,哪些后执行,哪些是并行执行的。
当调用了一个行为算子的时候,前面的所有转换算子也会一并提交给DAG调度器,DAG调度器把这些算子操作分为不同的stage,这个就是stage的由来。而DAG在画stage的时候也会产生出一个DAG图,就是这里的图了。
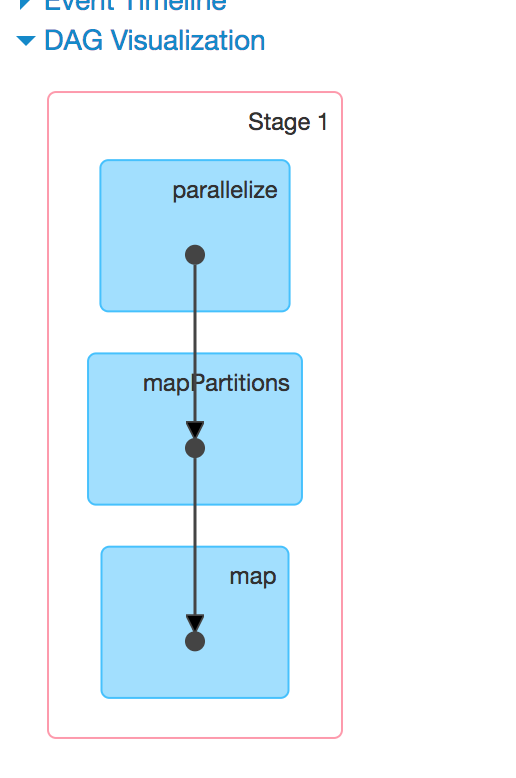
点击每个stage,我们就能看到这个stage执行的任务(Task)了。
Details for Stage
标题

标题代表这是第几号stage,第几次尝试。
Show Additional Metrics
Scheduler Delay
调度延迟时间,包含把任务从调度器输送给excutor,并且把任务的结果从excutor返回给调度器。如果调度时间比较久,则考虑降低任务的数量,并且降低任务结果大小
Task Deserialization Time
反序列化excutor的任务,也包含读取广播任务的时间
Shuffle Read Blocked Time
任务shuffle时间,从远端机器读取shuffle数据的时间
Shuffle Remote Reads
从远端机器读取shuffle数据的时间
Getting Result Time
从worker中获取结果的时间
// 这里应该还有一些其它的各种指标,等以后看代码的时候再补充。
在用图形表示完之后还有一个summary的时间统计,告诉你每个阶段的时间,所有任务的分布图。
Aggregated Metrics by Executor
这个矩阵告诉我们每个excutor的执行情况。
Tasks
告知每个任务的执行情况。
Environment
显示所有的环境变量
Excutors
显示每个excutor的统计情况
参考文章
http://www.csdn.net/article/2015-07-08/2825162
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-webui-StagePage.html
spark的sparkUI如何解读?的更多相关文章
- 【Spark】SparkContext源代码解读
SparkContext的初始化 SparkContext是应用启动时创建的Spark上下文对象,是进行Spark应用开发的主要接口,是Spark上层应用与底层实现的中转站(SparkContext负 ...
- 15、Spark Streaming源码解读之No Receivers彻底思考
在前几期文章里讲了带Receiver的Spark Streaming 应用的相关源码解读,但是现在开发Spark Streaming的应用越来越多的采用No Receivers(Direct Appr ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- Spark Streaming源码解读之No Receivers彻底思考
本期内容 : Direct Acess Kafka Spark Streaming接收数据现在支持的两种方式: 01. Receiver的方式来接收数据,及输入数据的控制 02. No Receive ...
- Spark Streaming源码解读之State管理之UpdataStateByKey和MapWithState解密
本期内容 : UpdateStateByKey解密 MapWithState解密 Spark Streaming是实现State状态管理因素: 01. Spark Streaming是按照整个Bach ...
- Spark Streaming源码解读之数据清理内幕彻底解密
本期内容 : Spark Streaming数据清理原理和现象 Spark Streaming数据清理代码解析 Spark Streaming一直在运行的,在计算的过程中会不断的产生RDD ,如每秒钟 ...
- Spark Streaming源码解读之Driver容错安全性
本期内容 : ReceivedBlockTracker容错安全性 DStreamGraph和JobGenerator容错安全性 Driver的安全性主要从Spark Streaming自己运行机制的角 ...
- Spark Streaming源码解读之Executor容错安全性
本期内容 : Executor的WAL 消息重放 数据安全的角度来考虑整个Spark Streaming : 1. Spark Streaming会不断次序的接收数据并不断的产生Job ,不断的提交J ...
- Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
本期内容 : 数据接收架构设计模式 数据接收源码彻底研究 一.Spark Streaming数据接收设计模式 Spark Streaming接收数据也相似MVC架构: 1. Mode相当于Rece ...
随机推荐
- Struts2基于XML配置方式实现对Action方法进行校验
JavaWeb框架(2) 使用XML对Action方法进行校验方式有两种,一种是对Action的所有方法进行校验,另一种是对Action指定方法进行校验. 对Action的所有方法进行校验: 步骤: ...
- String类的源码分析
之前面试的时候被问到有没有看过String类的源码,楼主当时就慌了,回来赶紧补一课. 1.构造器(构造方法) String类提供了很多不同的构造器,分别对应了不同的字符串初始化方法,此处从源码中摘录如 ...
- 导出含有图片的Java项目,图片不显示
项目的一些图片资源文件在导出成JAR包后,无法正确读取虽然Java项目还是可以运行,但原来的图片资源全不见了,于是你可以打开JAR包看看里面的东西,确实是有图片在里面,就是无法读取. 其实是因为我们在 ...
- 关于Visio Studio 2012使用Nuget获取Sqlite驱动包报错:“System.Data.SQLite.EF6”的架构版本与 NuGet 的版本 2.0.30625.9003 不兼容
背景 笔者的VS2012版本比较老旧,是几年以前下载的.平时添加三方包和驱动包都是手动添加.后来了解到有Nuget这个工具,如获至宝.可是在使用过程中却出了不少问题. 最初,笔者尝试使用Nuget添加 ...
- String类的一些常见的比较方法(4)
1:boolean equals(Object obj); //比较字符穿的内容是否相同 区分大小写的 2:boolean equalsIgnoreCase(String str); //比较字符穿的 ...
- GCD之并行串行区别
1.用户自定义线程队列,创建时很容易创建 注意创建时的第一个参数:标记值,方便调试查看 1 2 dispatch_queue_t serialqueue=dispatch_queue_create(& ...
- 个人从源码理解angular项目在JIT模式下的启动过程
通常一个angular项目会有一个个模块(Module)来管理各自的业务,并且必须有一个根模块(AppModule)作为应用的入口模块,整个应用都围绕AppModule展开.可以这么说,AppModu ...
- 查找Oracle数据库中的重复记录
本文介绍了几种快速查找ORACLE数据库中的重复记录的方法. 下面以表table_name为例,介绍三种不同的方法来确定库表中重复的记录 方法1:利用分组函数查找表中的重复行:按照某个字段分组,找出行 ...
- Poj 1032 Parliament
Parliament Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19103 Accepted: 8101 Descr ...
- iOS蓝牙心得
1.获取蓝牙mac地址 因为安卓不能得到uuid,所以,在要同步的时候要将uuid转换成mac地址,下面是转换方法 [peripheral discoverServices:@[[CBUUID UUI ...