ms_celeb_1m数据提取(MsCelebV1-Faces-Aligned.tsv)python脚本
本文主要介绍了如何对MsCelebV1-Faces-Aligned.tsv文件进行提取
原创by南山南北秋悲
欢迎引用!请注明原地址 http://www.cnblogs.com/hwd9654/p/6796811.html 谢谢!
最近用caffe做人脸识别,一开始用lfw作为数据库,但是体量太小,只有五千多人的图片
后来想用李子青组的casia-webface,从网上找了个,下下来发现居然损坏了,好气啊! 想去官网申请,却发现!!!:
- Sign the agreement (The agreement must be signed by the director or the delegate of the deparmart of university. Personal applicant is not acceptable.
。。。。。。不接受个人申请,而lz的学院领导不给签字 - -
后来索性就直接拿微软的ms celeb 1m来训练
简介如下:官网地址(https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/)
MSR IRC是目前世界上规模最大、水平最高的图像识别赛事之一,由MSRA(微软亚洲研究院)图像分析、大数据挖掘研究组组长张磊发起
ms_celeb_1m就是这个比赛的数据集
从1M个名人中,根据他们的受欢迎程度,选择100K个。然后,利用搜索引擎,给100K个人,每人搜大概100张图片。共100K*100=10M个图片。
有三种下载选项:
1.完整版
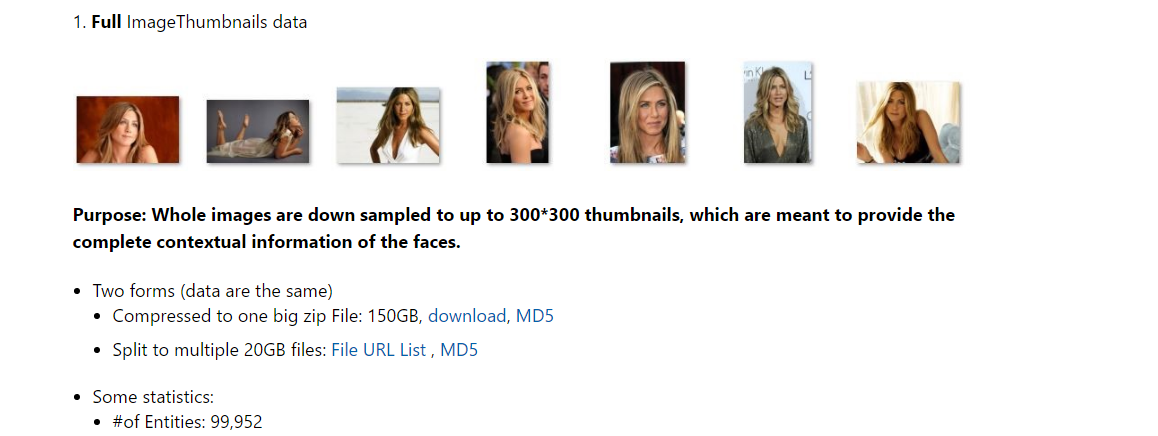
需要自己预处理,人脸检测,人脸对齐。。。
2.微处理版,修剪了一下
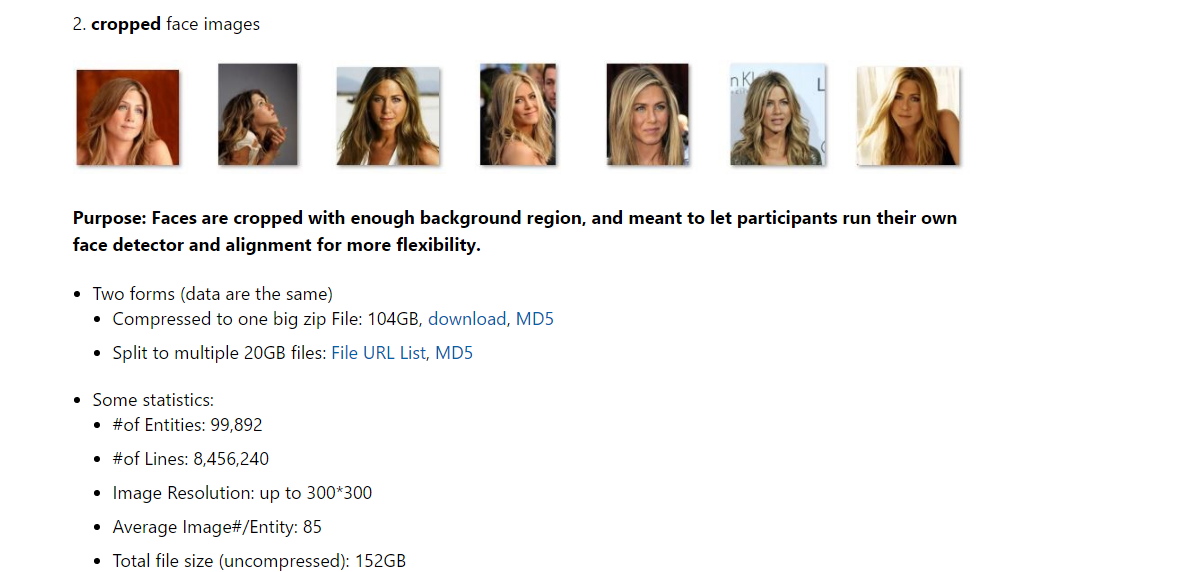
3.对齐过的版本
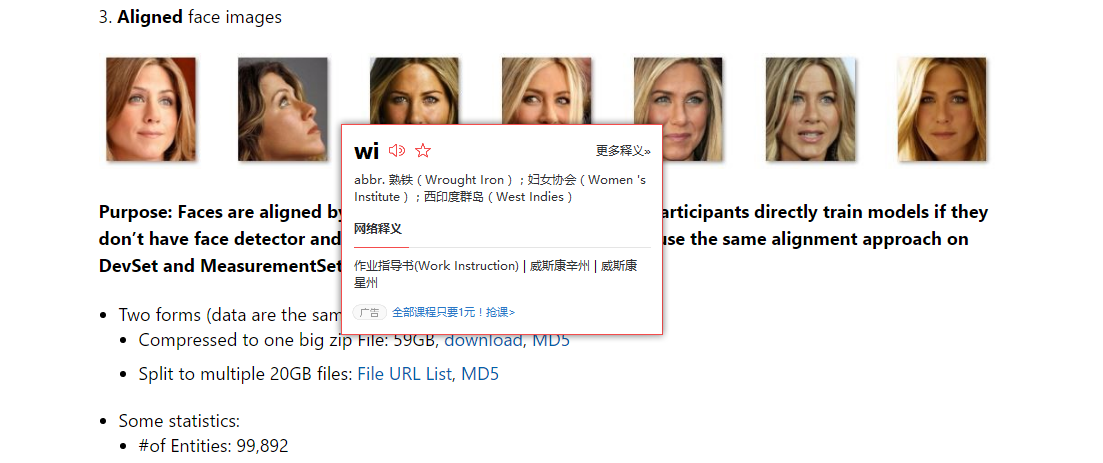
楼主用的是第三个对齐过的版本
下载下来是这么个玩意儿

好了废话不多说
直接上处理脚本
import base64
import csv
import os filename = "J:\dataset\ms_celeb_1m\MsCelebV1-Faces-Aligned.tsv"
outputDir = "I:\ms_celeb_1m" with open(filename, 'r') as tsvF:
reader = csv.reader(tsvF, delimiter='\t')
i = 0
for row in reader:
MID, imgSearchRank, faceID, data = row[0], row[1], row[4], base64.b64decode(row[-1]) saveDir = os.path.join(outputDir, MID)
savePath = os.path.join(saveDir, "{}-{}.jpg".format(imgSearchRank, faceID)) if not os.path.exists(saveDir):
os.mkdir(saveDir)
with open(savePath, 'wb') as f:
f.write(data) i += 1 if i % 1000 == 0:
print("Extracted {} images.".format(i))
自己改下相应路径就可以用了
处理结果:

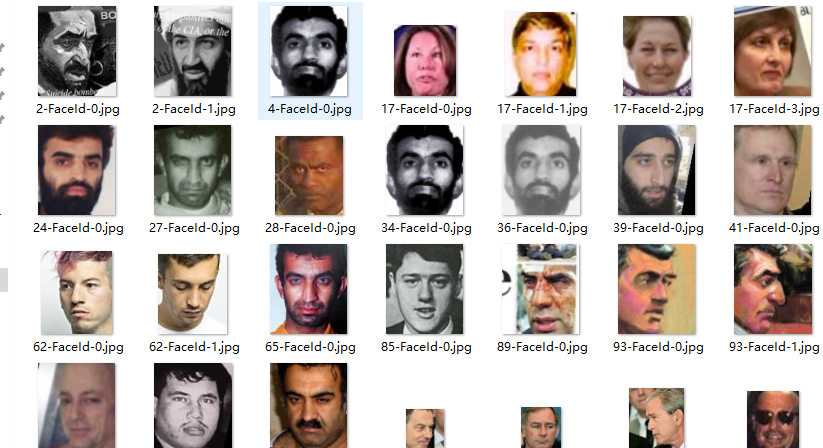
有什么疑问可以留言,不定期查看,慢回勿喷。。。
ms_celeb_1m数据提取(MsCelebV1-Faces-Aligned.tsv)python脚本的更多相关文章
- 使用Python脚本分析你的网站上的SEO元素
撰稿马尼克斯德芒克 上2019年1月, Sooda internetbureau Python就是自动执行重复性任务,为您的其他搜索引擎优化(SEO)工作留出更多时间.没有多少SEO使用Python来 ...
- 记录特殊情况的Python脚本的内存异常与处理
问题 Python 脚本使用 requests 模块做 HTTP 请求,验证代理 IP 的可用性,速度等. 设定 HTTP 请求的 connect timeout 与 read response ti ...
- Python爬虫10-页面解析数据提取思路方法与简单正则应用
GitHub代码练习地址:正则1:https://github.com/Neo-ML/PythonPractice/blob/master/SpiderPrac15_RE1.py 正则2:match. ...
- python 爬虫与数据可视化--数据提取与存储
一.爬虫的定义.爬虫的分类(通用爬虫.聚焦爬虫).爬虫应用场景.爬虫工作原理(最后会发一个完整爬虫代码) 二.http.https的介绍.url的形式.请求方法.响应状态码 url的形式: 请求头: ...
- 【学习】Python进行数据提取的方法总结【转载】
链接:http://www.jb51.net/article/90946.htm 数据提取是分析师日常工作中经常遇到的需求.如某个用户的贷款金额,某个月或季度的利息总收入,某个特定时间段的贷款金额和笔 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- Python——爬虫——数据提取
一.XML数据提取 (1)定义:XML指可扩展标记语言.标记语言,标签需要我们自行定义 (2)设计宗旨:是传输数据,而非显示数据,具有自我描述性 (3)节点关系: 父:每个元素及属性都有一个父. ...
- python爬虫数据提取之bs4的使用方法
Beautiful Soup的使用 1.下载 pip install bs4 pip install lxml # 解析器 官方推荐 2.引用方法 from bs4 import BeautifulS ...
- 【转载】使用Pandas进行数据提取
使用Pandas进行数据提取 本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据提取 目录 set_index() ix 按行提取信息 按列提取信息 按行与列提取信息 提取特定日期的信 ...
随机推荐
- cssLoading效果
http://files.cnblogs.com/files/xdoudou/loaders.css-master.zip
- 【SF】开源的.NET CORE 基础管理系统 -介绍篇
[SF]开源的.NET CORE 基础管理系统 -系列导航 1.环境: .NET Core SDK (https://www.microsoft.com/net/core) SQL Server or ...
- geoR文档翻译
说来惭愧,很久没有更新自己的博客了.期间个人生活经历了很多变故,心理上的打击尤甚.加之没有取得好的科研成果,痛定思痛,还是下苦功夫多多学习. 最近对比验证各种方法的插值精度,用到了R语言地统计学包,由 ...
- 零件库管理信息系统设计--part03:管理员登录部分设计
兄弟们,我又回来啦! 上次我把表建完了.今天来点干货,我们用ssm框架来先简单实现一下管理员的登录功能. 在实现之前,我对user表(管理员表)做了些简单的修改,先来看看: 忽略哪些蓝色的马赛克和乱输 ...
- UWP Composition API - New FlexGrid 锁定行列
如果之前看了 UWP Jenkins + NuGet + MSBuild 手把手教你做自动UWP Build 和 App store包 这篇的童鞋,针对VS2017,需要对应更新一下配置,需要的童鞋点 ...
- 知问前端——html+jq+jq_ui+ajax
**************************************************************************************************** ...
- linux shell 找端口号及对应的进程
#!/bin/bash#author:zhongyulin#crteate-time:2016-10-20 netstat -lnpt|grep -v grep>/tmp/script/nets ...
- ucenter单点登录
首先我们先来了解下Ucenter登录步骤 1.用户登录discuz,通过logging.php文件中的函数uc_user_login对post过来的数据进行验证,也就是对username和passwo ...
- java 接口默认修饰符问题
package test; public interface InterfaceTest { void todo();} /** * 以下是反编译的内容,接口里的方法默认都是public的.abstr ...
- icheck样式绑定与翻页保持
官方文档:http://icheck.fronteed.com/ 使用基本样式 $('input').iCheck({ checkboxClass : 'icheckbox_square-blue', ...