小白的Python之路 day4 json and pickle数据标准序列化
一、简述
我们在写入文件中的数据,只能是字符串或者二进制,但是要传入文件的数据不一定全是字符串或者二进制,那还要进行繁琐的转换,然后再读取的时候,还要再转回去,显得很麻烦,今天就来学习标准的序列化:json & pickle
二、json序列化
1、dumps序列化和loads反序列化
dumps()序列化
import json #导入json模块
info = {
'name':"qianduoduo",
"age":22,
}
with open("text.txt","w") as f: #以普通模式写入
f.write(json.dumps(info)) #把内存对象转为字符串
#写到文件中
#text.txt文件中的内容
{"name": "qianduoduo", "age": 22}
loads()反序列化
import json #导入json模块
with open("text.txt","r") as f: #以普通模式读
data = json.loads(f.read()) #用loads反序列化
print(data["age"]) #date.get("age") 一样的
#输出
22
2、dump序列化和load反序列化
dump()序列化
import json
info = {
'name':"qianduoduo",
"age":22
}
with open("text.txt","w") as f: #文件以写的方式打开
json.dump(info,f) #第1个参数是内存的数据对象 ,第2个参数是文件句柄
#text.txt文件中的内容
{"name": "qianduoduo", "age": 22}
load()反序列化
import json
with open("text.txt","r") as f: #以读的方式打开文件
data = json.load(f) #输入文件对象
print(data.get("age")) #date["age"]
#输出
22
3、序列化函数
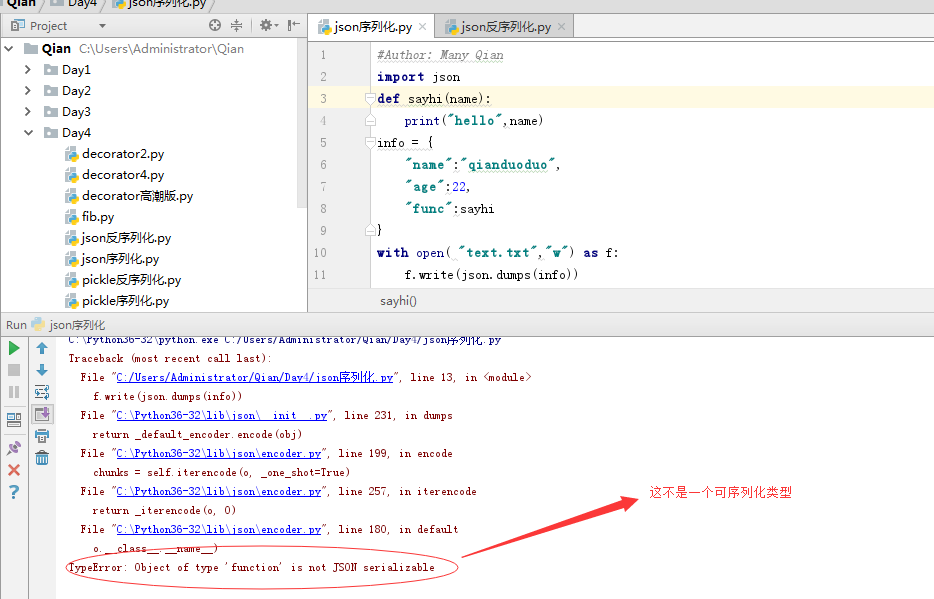
总结:
1.dumps和loads是成对使用的,dump和load是成对使用的。
2.dumps和loads由于序列化的是内容,所以后面要加s,但是dump和load序列化的内容是对象,所以单数。
3.json只能处理简单的数据类型,例如:字典、列表、字符串等,不能处理函数等复杂的数据类型。
为什么不能处理复杂的因为python 和别的语言定义函数,类完全不一样,特性也不一样
4.json是所有语言通用的,所有语言都支持json,如果我们需要python跟其他语言进行数据交互,那么就用json格式。
三、pickle序列化
1、dumps序列化和loads反序列化
dumps()序列化
import pickle
info = {
'name':"qianduoduo",
"age":22,
}
with open("text.txt","wb") as f: #以二进制的形式写入
data = pickle.dumps(info) #序列化成字符串
f.write(data) #写入text.txt 文件中
#输出到test.txt文件中的内容
�}q (X nameqX
qianduoduoqX ageqKu.
loads()反序列化
import pickle
with open("text.txt","rb") as f: #以二进制的模式读
data = pickle.loads(f.read()) #反序列化操作
print(data.get("age")) #date["age"] 是一样的
#输出
22
2、dump序列化和load反序列化
dump()序列化
import pickle
info = {
'name':"qianduoduo",
"age":22,
}
with open("text.txt","wb") as f:
pickle.dump(info,f) #序列化
#输出
�}q (X nameqX
qianduoduoqX ageqKu.
load()反序列化
import pickle
with open("text.txt","rb") as f:
data = pickle.load(f) #反序列化成内存对象
print(data.get("age")) #or date["age"] 一样的
#输出
22
上面几个例子可以观察出:
pickle序列化的是字节,而json序列化的是字符,所以pickle序列化写入和读取都是二进制
3、序列化函数
序列化
import pickle
def sayhi(name): #函数
print("hello:",name)
info = {
'name':"zhangqigao",
"age":22,
"func":sayhi #"func"对应的值sayhi,是函数名 如果sayhi加()就执行这个函数
}
with open("text.txt","wb") as f:
data = pickle.dumps(info)
f.write(data)
#输出test.txt
�}q (X nameqX
qianduoduoqX ageqKX funcqc__main__
sayhi
qu.
反序列化
import pickle
def sayhi(name): #在反序列化中必须写上此函数,不然会报错,因为在加载的时候,函数没有加载到内存
print("hello:",name)
with open("text.txt","rb") as f:
data = pickle.loads(f.read())
print(data["age"])
data.get("func")("qianduoduo") #执行函数sayhi
#输出
22
hello: qianduoduo #输出的函数体中的逻辑也是可以变的,但是函数名必须要相同,这又是要注意的地方
小结:
1.json值支持简单的数据类型,pickle支持python所有的数据类型。
2.pickle只能支持python本身的序列化和反序列化,不能用作和其他语言做数据交互,而json可以。
3.pickle序列化的是整个的数据对象,所以反序列化函数时,函数体中的逻辑变了,是跟着新的函数体逻辑。
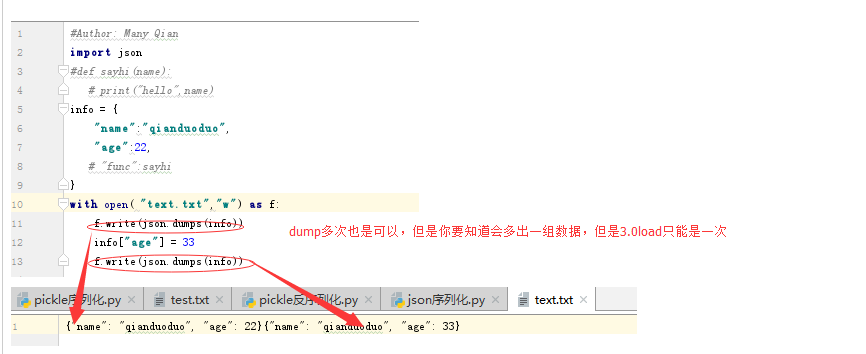
4.pickle和json在3.0中只能dump一次和load一次,dump在2.7里面可以dump多次,load多次,anyway,以后只记住,只需要dump一次,load一次就可以了。
小白的Python之路 day4 json and pickle数据标准序列化的更多相关文章
- 小白的Python之路 day4 装饰器前奏
装饰器前奏: 一.定义: 1.装饰器本质是函数,语法都是用def去定义的 (函数的目的:他需要完成特定的功能) 2.装饰器的功能:就是装饰其他函数(就是为其他函数添加附加功能) 二.原则: 1. 不能 ...
- 小白的Python之路 day4 装饰器高潮
首先装饰器实现的条件: 高阶函数+嵌套函数 =>装饰器 1.首先,我们先定义一个高级函数,去装饰test1函数,得不到我们想要的操作方式 import time #定义高阶函数 def deco ...
- 小白的Python之路 day4 生成器
一.列表生成式 看下面例子: 列表生成式的作用:主要是让代码更简洁(还有装X的效果) 二.生成器 通过列表生成式,我们可以直接创建一个列表.但是,受到内存限制,列表容量肯定是有限的.而且,创建一个包 ...
- 小白的Python之路 day4 迭代器
迭代器 学习前,我们回想一下可以直接作用于for循环的数据类型有以下几种: 1.集合数据类型,如list.tuple.dict.set.str等: 2.是generator,包括生成器和带yield的 ...
- 小白的Python之路 day4 软件目录结构规范
软件目录结构规范 为什么要设计好目录结构? "设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题.对于这种风格上的规范,一直都存在两种态度: 一类同 ...
- 小白的Python之路 day4 不同目录间进行模块调用(绝对路径和相对路径)
一.常用模块调用函数功能解释 1.__file__ 功能:返回自身文件的相对路径 你从pycharm的执行结果可以看出,在pycharm执行atm.py文件时,是从绝对路径下去执行的,而你从cmd下去 ...
- 小白的Python之路 day4 生成器并行运算
一.概述 我们已经明白生成器内部的结构,其实就是通过像函数这样的东西实现的! 多线程和单线程:简单来说多线程就是并行运算,单线程就是串行运算 二.生成器执行原理 第一步:生成一个生成器 第二步:执行 ...
- Python之路,Day4 - Python基础4 (new版)
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- Python之路,Day4 - Python基础(转载Alex)
本节大纲 迭代器&生成器 装饰器 基本装饰器 多参数装饰器 递归 算法基础:二分查找.二维数组转换 正则表达式 常用模块学习 作业:计算器开发 实现加减乘除及拓号优先级解析 用户输入 1 - ...
随机推荐
- Beautifulsoup分解
from urllib.request import Request, ProxyHandler from urllib.request import build_opener from bs4 im ...
- 【原创】通过搬瓦工vps搭建SS环境,供学习用
博主前段时间处于某些不可告人的目的,但又限于各类科学工具被禁的窘境,用搬瓦工的vps搭建了次SS环境,现在就来回顾并不知廉耻的传授下经验. 第一步:购买vps 1.登录官网 https://bwh1. ...
- 在C#中输出变量的地址
int a = 3; GCHandle handle = GCHandle.Alloc(a); var pin = GCHandle.ToIntPtr(handle); Console.WriteLi ...
- idea—— 模版配置
修改File Header: /** * @author: ${USER} Date: ${DATE} Time: ${TIME} */ 新增Package Header: /* * Copyrigh ...
- MongoDB-Use --auth parameter with connecting error
When you use mongoDB started as "mongod --dbpath ../../data/db --auth", and you use the ex ...
- SpringBoot集成Redis实现缓存处理(Spring AOP实现)
第一章 需求分析 计划在Team的开源项目里加入Redis实现缓存处理,因为业务功能已经实现了一部分,通过写Redis工具类,然后引用,改动量较大,而且不可以实现解耦合,所以想到了Spring框架的A ...
- 【NOIP2015提高组】运输计划
https://daniu.luogu.org/problem/show?pid=2680 使完成所有运输计划的时间最短,也就是使时间最长的运输计划耗时最短.最大值最小问题考虑用二分答案,每次chec ...
- Codeforces Gym 101521A Shuttle Bus
题意:给定一个2*N的方格,从左上角开始走,有些格子不能走,问能否一次遍历所有能走的方格 在Gym上看到一场香港的比赛,很好奇就去看了一下,发现第一题很有趣,并且很水,似乎讨论一下奇偶性就行了,然后. ...
- java学习总结篇一--写在正式成为码农一年后
一直想写一写工作了一年多的总结与感悟,今天正好有时间,也有这个兴致,随手总结一下这一年来学习及工作的情况. 大学时很无奈地被选择了计算机专业,本人对计算机,不讨厌,也算不上多喜欢.只是当惯了好学生,好 ...
- JAVA8之lambda表达式具体解释,及stream中的lambda使用
前言: 本人也是学习lambda不久,可能有些地方描写叙述有误,还请大家谅解及指正! lambda表达式具体解释 一.问题 1.什么是lambda表达式? 2.lambda表达式用来干什么的? 3.l ...