elasticsearch父子文档处理(join)
elasticsearch父子文档处理 join
一、背景
在我们工作的过程中,有些时候我们需要用到父子文档的关系映射。**比如:**一个问题有多个答案、一本书籍有多个评论等等。此处我们可以使用 es 的 jion数据类型或 nested来实现。此处我们使用join来建立es中的父子文档关系。
二、需求
我们需要创建一个计划(plan),计划下存在活动(activity)和书籍(book),书籍下存在评论(comments)。
即层级结构为:
plan
/ \
/ \
activity book
|
|
comments
三、前置知识
- 每一个
mapping下只能有一个join类型的字段。 - 父文档和子文档必须在同一个分片(
shard)上。即: 增删改查一个子文档都必须和父文档使用相同的 routing key。 - 每个元素只能有一个父,但是可以存在多个子。
- 可以为一个已经存在的 join 字段增加新的关联关系。
- 可以为一个已经是父的元素增加一个子元素。
join数据类型在elasticsearch中不应该像关系型数据库那种使用。而且has_child和has_parent都是比较消耗性能的。只有当 子的数据 远远大于 父的数据时,使用
join才是有意义的。比如:一个博客下,有多个评论。
四、实现步骤
1、创建 mapping
PUT /plan_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"plan_id":{
"type": "keyword"
},
"plan_name":{
"type": "text",
"fields": {
"keyword":{
"type" : "keyword",
"ignore_above" : 256
}
}
},
"act_id":{
"type": "keyword"
},
"act_name":{
"type": "text",
"fields": {
"keyword":{
"type" : "keyword",
"ignore_above" : 256
}
}
},
"comment_id":{
"type": "keyword"
},
"comment_name":{
"type": "text",
"fields": {
"keyword":{
"type" : "keyword",
"ignore_above" : 256
}
}
},
"creator":{
"type": "keyword"
},
"create_time":{
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
},
"plan_join": {
"type": "join",
"relations": {
"plan": ["activity", "book"],
"book": "comments"
}
}
}
}
}
注意️

2、添加父文档数据
此处添加的是 (plan) 数据。
PUT /plan_index/_doc/plan-001
{
"plan_id": "plan-001",
"plan_name": "四月计划",
"creator": "huan",
"create_time": "2021-04-07 16:27:30",
"plan_join": {
"name": "plan"
}
}
PUT /plan_index/_doc/plan-002
{
"plan_id": "plan-002",
"plan_name": "五月计划",
"creator": "huan",
"create_time": "2021-05-07 16:27:30",
"plan_join": "plan"
}
注意️:
1、如果是创建父文档,则需要使用 plan_join 指定父文档的关系的名字(此处为plan)。
2、plan_join为创建索引的 mapping时指定join的字段的名字。
3、指定父文档时,plan_join的这2种写法都可以。
3、添加子文档
PUT /plan_index/_doc/act-001?routing=plan-001
{
"act_id":"act-001",
"act_name":"四月第一个活动",
"creator":"huan.fu",
"plan_join":{
"name":"activity",
"parent":"plan-001"
}
}
PUT /plan_index/_doc/book-001?routing=plan-001
{
"book_id":"book-001",
"book_name":"四月读取的第一本书",
"creator":"huan.fu",
"plan_join":{
"name":"book",
"parent":"plan-001"
}
}
PUT /plan_index/_doc/book-002?routing=plan-001
{
"book_id":"book-002",
"book_name":"编程珠玑",
"creator":"huan.fu",
"plan_join":{
"name":"book",
"parent":"plan-001"
}
}
PUT /plan_index/_doc/book-003?routing=plan-002
{
"book_id":"book-003",
"book_name":"java编程思想",
"creator":"huan.fu",
"plan_join":{
"name":"book",
"parent":"plan-002"
}
}
# 理论上 comment 的父文档是 book ,但是此处routing使用 plan 也是可以的。
PUT /plan_index/_doc/comment-001?routing=plan-001
{
"comment_id":"comment-001",
"comment_name":"这本书还可以",
"creator":"huan.fu",
"plan_join":{
"name":"comments",
"parent":"book-001"
}
}
PUT /plan_index/_doc/comment-002?routing=plan-001
{
"comment_id":"comment-002",
"comment_name":"值得一读,棒。",
"creator":"huan.fu",
"plan_join":{
"name":"comments",
"parent":"book-001"
}
}
注意️:
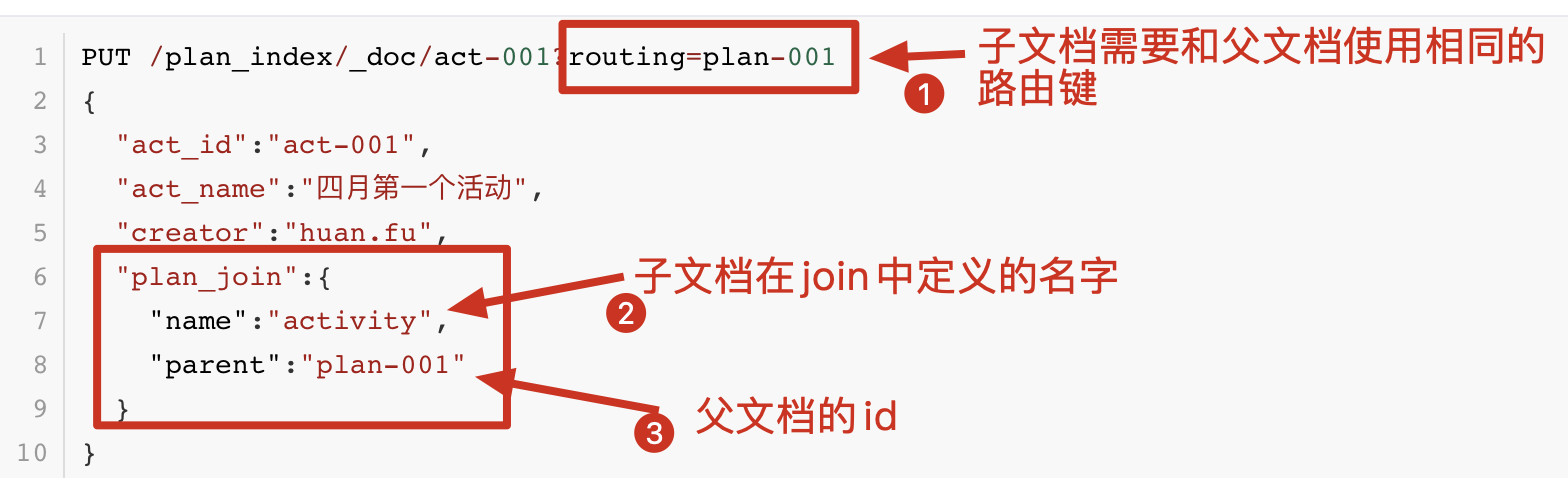
1、子文档(子孙文档等)需要和父文档使用相同的路由键。
2、需要指定父文档的id。
3、需要指定join的名字。
4、查询文档
1、根据父文档id查询它下方的子文档
**需求:**返回父文档id是plan-001下的类型为book的所有子文档。
GET /plan_index/_search
{
"query":{
"parent_id": {
"type":"book",
"id":"plan-001"
}
}
}

2、has_child返回满足条件的父文档
**需求:**返回创建者(creator)是huan.fu,并且子文档最少有2个的父文档。
GET /plan_index/_search
{
"query": {
"has_child": {
"type": "book",
"min_children": 2,
"query": {
"match": {
"creator": "huan.fu"
}
}
}
}
}

3、has_parent返回满足父文档的子文档
**需求:**返回父文档(book)的创建者是huan.fu的所有子文档
GET /plan_index/_search
{
"query": {
"has_parent": {
"parent_type": "book",
"query": {
"match": {
"creator":"huan.fu"
}
}
}
}
}

五、Nested Object 和 join 对比
| Nested Object | join (Parent/Child) |
|---|---|
| 1、文档存储在一起,读取性能高 | 1、父子文档单独存储,互不影响。但是为了维护join的关系,需要占用额外的内容,读取性能略差。 |
| 2、更新父文档或子文档时,需要更新整个文档。 | 2、父文档和子文档可以单独更新。 |
| 3、适用于查询频繁,子文档偶尔更新的情况。 | 3、适用于更新频繁的情况,且子文档的数量远远超过父文档的数量。 |
六、参考文档
1、join数据类型
elasticsearch父子文档处理(join)的更多相关文章
- elasticsearch 父子文档(十一)
说明 需求 一个产品多个区域销售 每个区域有自己的价格, 方式1冗余行,a 产品分别在 area1 area2 area3区域销售 a产品就会生成3条产品数据 搜索id去重就行了,但是问题就是 聚合 ...
- elasticsearch——海量文档高性能索引系统
elasticsearch elasticsearch是一个高性能高扩展性的索引系统,底层基于apache lucene. 可结合kibana工具进行可视化. 概念: index 索引: 类似SQL中 ...
- ES 父子文档查询
父子文档的特点 1. 父/子文档是完全独立的. 2. 父文档更新不会影响子文档. 3. 子文档更新不会影响父文档或者其它子文档. 父子文档的映射与索引 1. 父子关系 type 的建立必须在索引新建或 ...
- elasticsearch 路由文档到分片
路由文档到分片 当你索引一个文档,它被存储在单独一个主分片上.Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢? 进程不能是 ...
- ElasticSearch部署文档(Ubuntu 14.04)
ElasticSearch部署文档(Ubuntu 14.04) 参考链接 https://www.elastic.co/guide/en/elasticsearch/guide/current/hea ...
- ElasticSearch——原始文档和倒排索引
一.原始文档 如上图所示, 第二象限是一份原始文档,有title和content2个字段,字段取值分别为”我是中国人”和” 热爱共X产党”,这一点没什么可解释的.我们把原始文档写入Elasticsea ...
- 007-elasticsearch5.4.3【一】概述、Elasticsearch 访问方式、Elasticsearch 面向文档、常用概念
一.概述 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上. Elasticsearch 也是使用 Java 编写的,它的内部使用 L ...
- Elasticsearch 删除文档
章节 Elasticsearch 基本概念 Elasticsearch 安装 Elasticsearch 使用集群 Elasticsearch 健康检查 Elasticsearch 列出索引 Elas ...
- Elasticsearch 更新文档
章节 Elasticsearch 基本概念 Elasticsearch 安装 Elasticsearch 使用集群 Elasticsearch 健康检查 Elasticsearch 列出索引 Elas ...
随机推荐
- WEB安全性测试之拒绝服务攻击
1,认证 需要登录帐号的角色 2,授权 帐号的角色的操作范围 3,避免未经授权页面直接可以访问 使用绝对url(PS:绝对ur可以通过httpwatch监控每一个请求,获取请求对应的页面),登录后台的 ...
- 数据结构(c++)(第二版) Dijkstra最短路径算法 教学示范代码出现重大问题!
前言 去年在数据结构(c++)的Dijkstra教学算法案例中,发现了一个 bug 导致算法不能正常的运行,出错代码只是4行的for循环迭代代码. 看到那里就觉得有问题,但书中只给了关键代码的部分,其 ...
- Excel删除重复数据及用公式筛选重复项并标记颜色突出显示
当表格记录比较多时,常常会有重复数据,而重复记录往往只希望保存一条,因此需要把多余的删除:在 Excel 中,删除重复数据有两种方法,一种是用"删除重复数据"删除,另一种是用&qu ...
- PHP设计模式之中介者模式
上回说道,我们在外打工的经常会和一类人有很深的接触,那就是房产中介.大学毕业后马上就能在喜欢的城市买到房子的X二代不在我们的考虑范围内哈.既然需要长期的租房,那么因为工作或者生活的变动,不可避免的一两 ...
- 【小程序】微信小程序iOS苹果报错“协议错误”
遇到问题 目前正在开发一个小程序,然后苹果真机测试时发现无法授权并提示,errMsg:"request:fail 未能完成该操作.协议错误" 开发环境下测试没问题,安卓机真机测试没 ...
- 网站URL Rewrite(伪静态)设置方法
1.如果您的服务器支持.htaccess,则无需设置,网站根目录下的.htaccess已经设置好规则.规则详情:http://download.destoon.com/rewrite/htaccess ...
- (数据科学学习手札128)在matplotlib中添加富文本的最佳方式
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 长久以来,在使用matplotlib进行绘 ...
- linux,apache,php,mysql常用的查看版本信息的方法
1. 查看linux的内核版本,系统信息,常用的有三种办法: uname -a: more /etc/issue; cat /proc/version; 2. 查看apache的版本信息 ...
- struts2 使用ajax进行图片上传
第一步:引入一个插件 jquery.form.js /*! * jQuery Form Plugin * version: 3.36.0-2013.06.16 * @requires jQuer ...
- mapper-spring-boot-starter 主要作用是
今天是第一次接触到 这个场景启动器内心中真是一片的茫然,学习了这么长时间我居然还不知道有这个的存在今天好好查一查资料 参考资料(https://blog.csdn.net/crq1205/articl ...