Spark面试题(五)——数据倾斜调优
1、数据倾斜
数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
数据倾斜俩大直接致命后果。
1、数据倾斜直接会导致一种情况:Out Of Memory。
2、运行速度慢。
主要是发生在Shuffle阶段。同样Key的数据条数太多了。导致了某个key(下图中的80亿条)所在的Task数据量太大了。远远超过其他Task所处理的数据量。
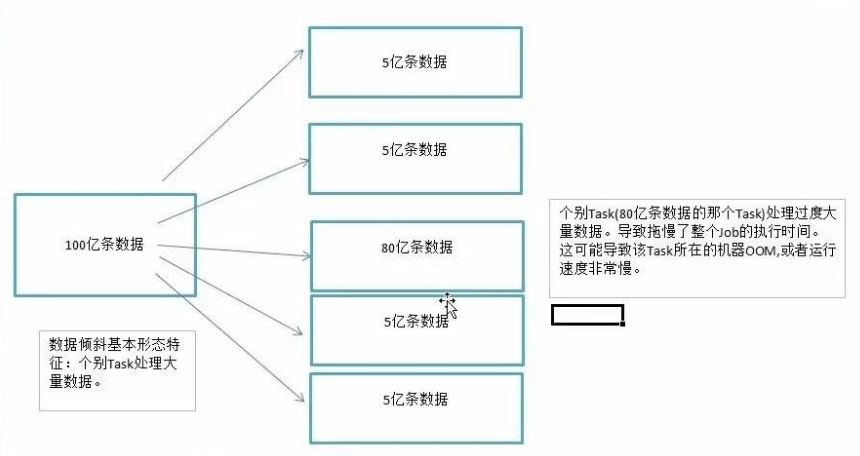
一个经验结论是:一般情况下,OOM的原因都是数据倾斜
2、如何定位数据倾斜
数据倾斜一般会发生在shuffle过程中。很大程度上是你使用了可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
原因:查看任务->查看Stage->查看代码
某个task执行特别慢的情况
某个task莫名其妙内存溢出的情况
查看导致数据倾斜的key的数据分布情况
也可从以下几种情况考虑:
1、是不是有OOM情况出现,一般是少数内存溢出的问题
2、是不是应用运行时间差异很大,总体时间很长
3、需要了解你所处理的数据Key的分布情况,如果有些Key有大量的条数,那么就要小心数据倾斜的问题
4、一般需要通过Spark Web UI和其他一些监控方式出现的异常来综合判断
5、看看代码里面是否有一些导致Shuffle的算子出现
3、数据倾斜的几种典型情况
3.1 数据源中的数据分布不均匀,Spark需要频繁交互
3.2 数据集中的不同Key由于分区方式,导致数据倾斜
3.3 JOIN操作中,一个数据集中的数据分布不均匀,另一个数据集较小(主要)
3.4 聚合操作中,数据集中的数据分布不均匀(主要)
3.5 JOIN操作中,两个数据集都比较大,其中只有几个Key的数据分布不均匀
3.6 JOIN操作中,两个数据集都比较大,有很多Key的数据分布不均匀
3.7 数据集中少数几个key数据量很大,不重要,其他数据均匀
注意:
1、需要处理的数据倾斜问题就是Shuffle后数据的分布是否均匀问题
2、只要保证最后的结果是正确的,可以采用任何方式来处理数据倾斜,只要保证在处理过程中不发生数据倾斜就可以
4、数据倾斜的处理方法
4.1 数据源中的数据分布不均匀,Spark需要频繁交互
解决方案:避免数据源的数据倾斜
实现原理:通过在Hive中对倾斜的数据进行预处理,以及在进行kafka数据分发时尽量进行平均分配。这种方案从根源上解决了数据倾斜,彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。
方案优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
方案缺点:治标不治本,Hive或者Kafka中还是会发生数据倾斜。
适用情况:在一些Java系统与Spark结合使用的项目中,会出现Java代码频繁调用Spark作业的场景,而且对Spark作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次Java调用Spark作业时,执行速度都会很快,能够提供更好的用户体验。
总结:前台的Java系统和Spark有很频繁的交互,这个时候如果Spark能够在最短的时间内处理数据,往往会给前端有非常好的体验。这个时候可以将数据倾斜的问题抛给数据源端,在数据源端进行数据倾斜的处理。但是这种方案没有真正的处理数据倾斜问题。
4.2 数据集中的不同Key由于分区方式,导致数据倾斜
解决方案1:调整并行度
实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,都无法处理。
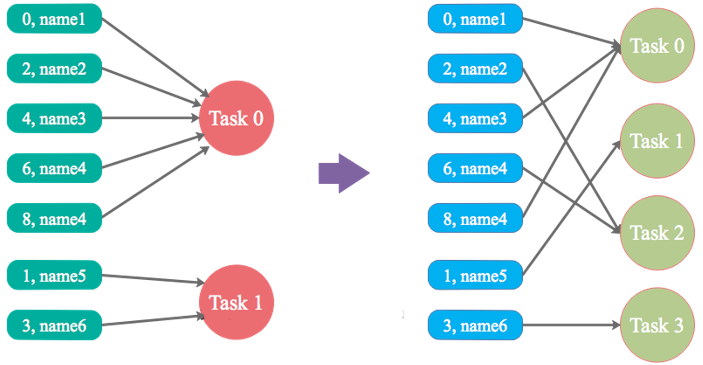
总结:调整并行度:适合于有大量key由于分区算法或者分区数的问题,将key进行了不均匀分区,可以通过调大或者调小分区数来试试是否有效
解决方案2:
缓解数据倾斜(自定义Partitioner)
适用场景:大量不同的Key被分配到了相同的Task造成该Task数据量过大。
解决方案: 使用自定义的Partitioner实现类代替默认的HashPartitioner,尽量将所有不同的Key均匀分配到不同的Task中。
优势: 不影响原有的并行度设计。如果改变并行度,后续Stage的并行度也会默认改变,可能会影响后续Stage。
劣势: 适用场景有限,只能将不同Key分散开,对于同一Key对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的Partitioner,不够灵活。
4.3 JOIN操作中,一个数据集中的数据分布不均匀,另一个数据集较小(主要)
解决方案:Reduce side Join转变为Map side Join
方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M),比较适用此方案。
方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。
方案优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
方案缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。
4.4 聚合操作中,数据集中的数据分布不均匀(主要)
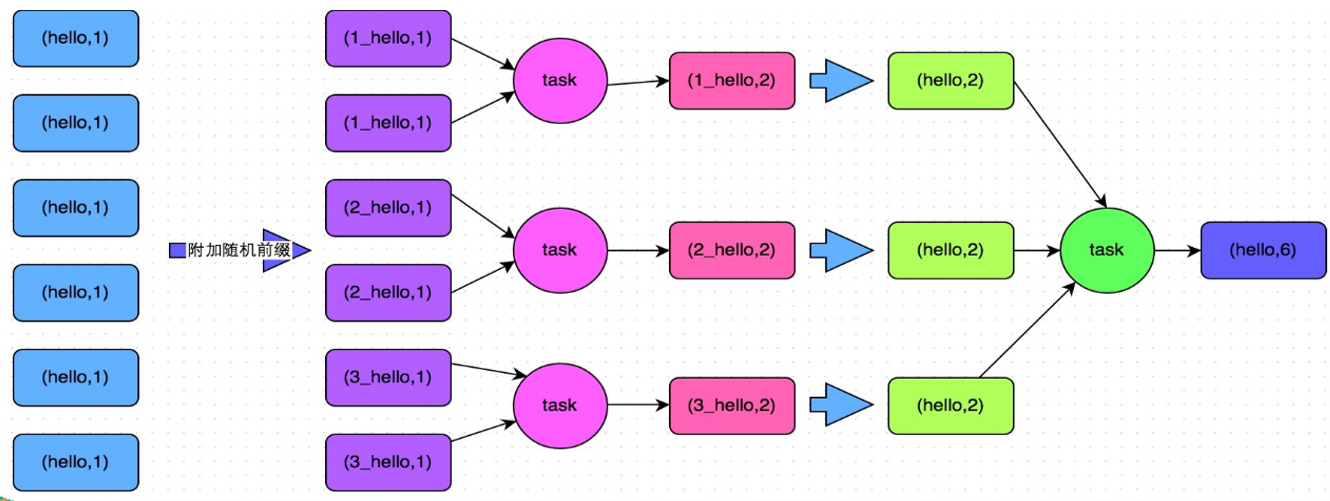
解决方案:两阶段聚合(局部聚合+全局聚合)
适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案
实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案将相同key的数据分拆处理
4.5 JOIN操作中,两个数据集都比较大,其中只有几个Key的数据分布不均匀
解决方案:为倾斜key增加随机前/后缀
适用场景:两张表都比较大,无法使用Map侧Join。其中一个RDD有少数几个Key的数据量过大,另外一个RDD的Key分布较为均匀。
解决方案:将有数据倾斜的RDD中倾斜Key对应的数据集单独抽取出来加上随机前缀,另外一个RDD每条数据分别与随机前缀结合形成新的RDD(笛卡尔积,相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join后去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
优势:相对于Map侧Join,更能适应大数据集的Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
劣势:如果倾斜Key非常多,则另一侧数据膨胀非常大,此方案不适用。而且此时对倾斜Key与非倾斜Key分开处理,需要扫描数据集两遍,增加了开销。
注意:具有倾斜Key的RDD数据集中,key的数量比较少
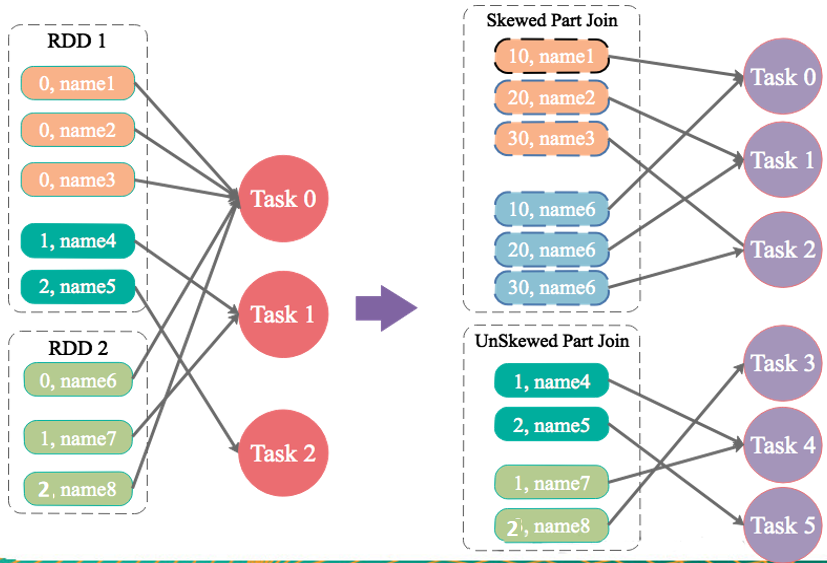
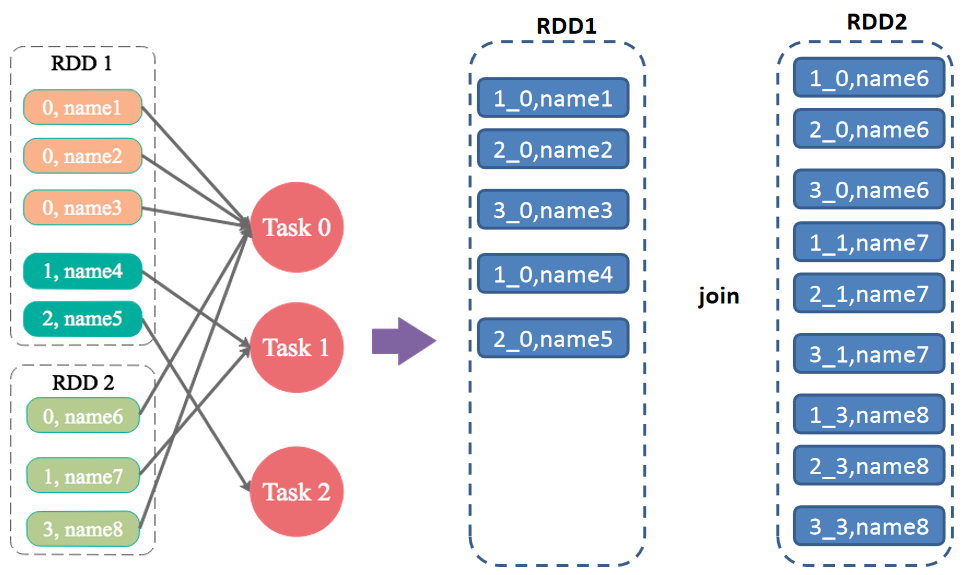
4.6 JOIN操作中,两个数据集都比较大,有很多Key的数据分布不均匀
解决方案:随机前缀和扩容RDD进行join
适用场景:如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义。
实现思路:将该RDD的每条数据都打上一个n以内的随机前缀。同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。最后将两个处理后的RDD进行join即可。和上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
优点:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。
实践经验:曾经开发一个数据需求的时候,发现一个join导致了数据倾斜。优化之前,作业的执行时间大约是60分钟左右;使用该方案优化之后,执行时间缩短到10分钟左右,性能提升了6倍。
注意:将倾斜Key添加1-N的随机前缀,并将被Join的数据集相应的扩大N倍(需要将1-N数字添加到每一条数据上作为前缀)
4.7 数据集中少数几个key数据量很大,不重要,其他数据均匀
解决方案:过滤少数倾斜Key
适用场景:如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
缺点:适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。
实践经验:在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天Spark作业在运行的时候突然OOM了,追查之后发现,是Hive表中的某一个key在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个key之后,直接在程序中将那些key给过滤掉。
猜你喜欢
Hive计算最大连续登陆天数
Hadoop 数据迁移用法详解
Hbase修复工具Hbck
数仓建模分层理论
一文搞懂Hive的数据存储与压缩
大数据组件重点学习这几个
Spark面试题(五)——数据倾斜调优的更多相关文章
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark学习之路 (九)SparkCore的调优之数据倾斜调优
摘抄自:https://tech.meituan.com/spark-tuning-pro.html 数据倾斜调优 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Sp ...
- Spark(十)Spark之数据倾斜调优
一 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多.数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作 ...
- Spark学习之路 (九)SparkCore的调优之数据倾斜调优[转]
调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题--数据倾斜,此时Spark作业的性能会比期望差很多.数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的 ...
- 最详细10招Spark数据倾斜调优
最详细10招Spark数据倾斜调优 数据量大并不可怕,可怕的是数据倾斜 . 数据倾斜发生的现象 绝大多数 task 执行得都非常快,但个别 task 执行极慢. 数据倾斜发生的原理 在进行 shuff ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- Spark 数据倾斜调优
一.what is a shuffle? 1.1 shuffle简介 一个stage执行完后,下一个stage开始执行的每个task会从上一个stage执行的task所在的节点,通过网络传输获取tas ...
- 【Spark篇】---Spark调优之代码调优,数据本地化调优,内存调优,SparkShuffle调优,Executor的堆外内存调优
一.前述 Spark中调优大致分为以下几种 ,代码调优,数据本地化,内存调优,SparkShuffle调优,调节Executor的堆外内存. 二.具体 1.代码调优 1.避免创建重复的RDD,尽 ...
- 【原创】构建高性能ASP.NET站点 第五章—性能调优综述(后篇)
原文:[原创]构建高性能ASP.NET站点 第五章-性能调优综述(后篇) 构建高性能ASP.NET站点 第五章—性能调优综述(后篇) 前言:本篇主要讲述如何根据一些简单的工具和简单的现象来粗布的定位站 ...
随机推荐
- Python读取ini配置文件(接口自动测试必备)
前言 大家应该接触过.ini格式的配置文件.配置文件就是把一些配置相关信息提取出去来进行单独管理,如果以后有变动只需改配置文件,无需修改代码. 特别是后续做自动化的测试,代码和数据分享,进行管理.比如 ...
- 订单峰值激增 230%,Serverless 如何为世纪联华降本超 40%?|双11 云原生实践
作者 | 朱鹏 导读:2020 年 双11,世纪联华基于阿里云函数计算 (FC) 弹性扩容,应用于大促会场 SSR.线上商品秒杀.优惠券定点发放.行业导购.数据中台计算等多个场景,业务峰值 QPS 较 ...
- 第29篇-调用Java主类的main()方法
在第1篇中大概介绍过Java中主类方法main()的调用过程,这一篇介绍的详细一点,大概的调用过程如下图所示. 其中浅红色的函数由主线程执行,而另外的浅绿色部分由另外一个线程执行,这个线程最终也会负责 ...
- python中函数里面冒号和函数后面的箭头是什么含义
函数里参数后的冒号其实是参数的类型建议,但是只是建议,就算你不按约定传也不会报错.而后面的箭头,则是函数返回值的类型建议.
- 函数返回值为 const 指针、const 引用
函数返回值为 const 指针,可以使得外部在得到这个指针后,不能修改其指向的内容.返回值为 const 引用同理. class CString { private: char* str; publi ...
- python 工具箱
strip() 方法可以从字符串去除不想要的空白符. print() BIF的file参数控制将数据发送/保存到哪里. finally组总会执行,而不论try/except语句中出现什么异常. 会向e ...
- SpringCloud 2020.0.4 系列之Eureka
1. 概述 老话说的好:遇见困难,首先要做的是积极的想解决办法,而不是先去泄气.抱怨或生气. 言归正传,微服务是当今非常流行的一种架构方式,其中 SpringCloud 是我们常用的一种微服务框架. ...
- 三分钟极速体验:Java版人脸检测
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- [技术博客]大闸蟹的技术博客,通过gitlab api进行用户批量创建
技术博客--通过gitlab api批量注册用户 gitlab登录界面本身提供了register功能,但需要手工一个个添加,对于一次性会添加整个班级的学生的软工平台来说并不科学合理.使用gitlab ...
- FastAPI 学习之路(二十八)使用密码和 Bearer 的简单 OAuth2
OAuth2 规定在使用(我们打算用的)「password 流程」时,客户端/用户必须将 username 和 password 字段作为表单数据发送.我们看下在我们应该去如何实现呢. 我们写一个登录 ...