经过4次优化我把python代码耗时减少95%
背景交代
团队做大学英语四六级考试相关服务。业务中有一个care服务,购买了care服务考试不过可以全额退款,不过有一个前提是要完成care服务的任务,比如坚持背单词N天,完成指定的试卷。
在这个背景下,当2021年6月的四六级考试完成之后,要统计出两种用户数据:
- 完成care服务的用户
- 没有完成care的用户
所以简化的逻辑就是要在所有的用户中区分出care完成用户和care未完成用户。
- 目标1:完成care服务
- 目标2:未完成care服务
所有目标用户的数量在2.7w左右,care完成用户在0.4w左右。所以我需要做的是在从数据库中查询出的 2.7w 所有用户,去另一个表区分出care完成用户和care未完成用户。
第一版
第一版:纯粹使用数据库查询。首先查询出所有目标,然后遍历所有用户,在遍历中使用user id从另一张表中查询出care完成用户。
总量在2.7w 左右,所以数据库就查询了2.7w次。
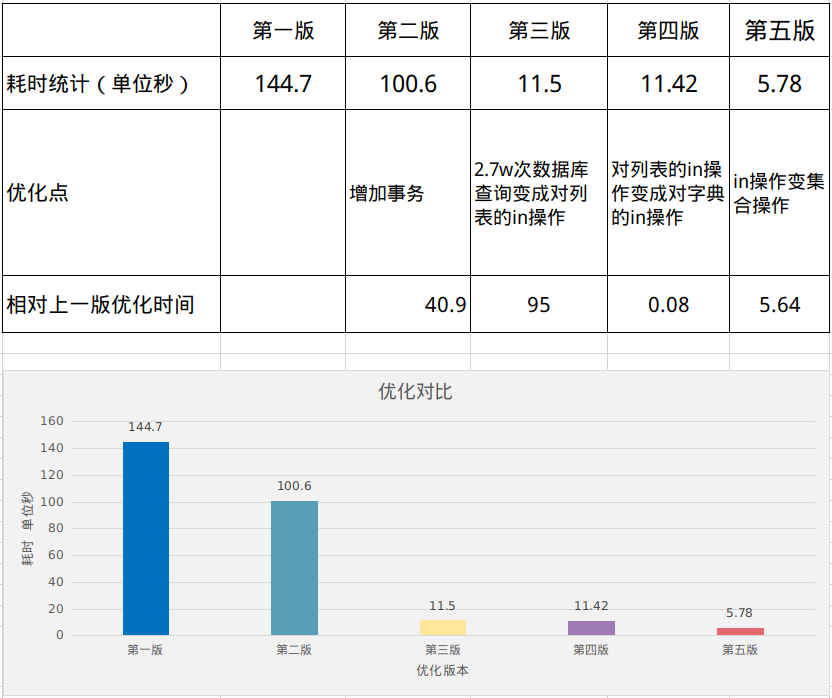
耗时统计:144.7 s
def remind_repurchase():
# 查询出所有用户
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
for user in all_users:
# 从另一张表查询用户是否完成care
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.user_id == user.user_id,
cm.UserInsurance.plan_id == user.plan_id,
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
# care 完成
if len(user_insurance) == 1:
# 其他逻辑
plan_15_16_can_refund_users.append(user.user_id)
else:
# care未完成用户
plan_15_16_not_refund_users.append(user.user_id)
主要的耗时操作就在for循环查询数据库。这种耗时肯定是不被允许的,需要提高效率。
第二版
优化点:增加事务
第二版优化思路:对于 2.7w 次的数据库库查询肯定会有 2.7w 次建立连接、事务、查询语句转SQL等。2.7w次的开销也是一个极大的数字。理所当然的想到了减少事务的开销。将所有的数据库查询都放在一个事务中完成,就能够有效减少查询带来的耗时。
耗时统计:100.6 s
def remind_repurchase():
# 查询出所有用户
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 增加事务
with pwdb.database.atomic():
for user in all_users:
# 从另一张表查询用户是否完成care
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.user_id == user.user_id,
cm.UserInsurance.plan_id == user.plan_id,
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
# care 完成
if len(user_insurance) == 1:
# 其他逻辑
plan_15_16_can_refund_users.append(user.user_id)
else:
# care未完成用户
plan_15_16_not_refund_users.append(user.user_id)
增加事务之后减少了44s,相当于缩短了时间30%的时间,由此可以看出事务在数据库中查询是一个比较耗时的操作。
第三版
优化点:将2.7w次的数据库查询转变成对列表的in操作。
第三版提出改进方案:原来的逻辑是循环 2.7w 次,在数据库中查询用户是否完成care服务。2.7w 次的数据库查询是耗时最长的原因,而可以改进的方法是将所有完成care服务的用户先一次性查询出来,放到一个列表中。遍历所有用户时不去查数据库,而是直接使用in操作在列表中查询。这种方法直接将 2.7w 次数据库遍历减少到1次,极大缩短了数据库查询耗时。
耗时统计:11.5 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 所有care完成用户,先将所有用户查询出来放在一个列表中
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_list = [user.user_id for user in user_insurance]
for user in all_users:
user_id = user.user_id
# care 完成
if user.user_id in user_insurance_list:
# 查分数
plan_15_16_can_refund_users.append(user_id)
else:
# care未完成用户 + 非care用户
plan_15_16_not_refund_users.append(user_id)
这一次优化的效果是非常显著的,可以看出想要提高代码效率要尽量减少数据库查询次数。
第四版
优化点:2.7w 次对列表的in操作变成对字典的in操作
在第三版中已经极大的优化了效率,但是仔细琢磨之后发现还是有提升的空间的。在第三版中 2.7w 次for循环,然后用in操作在列表中查询。众所周知python中对列表的in操作是遍历的,时间复杂度为0(n),所以效率不高,而对字典的in操作时间复杂度为常数级别0(1)。所以在第四版优化中先查询出的数据不保存为列表,而是保存为字典。key就是原来列表中的值,value可自定义。
耗时统计:11.42 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 所有care完成用户,先将所有用户查询出来放在一个列表中
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_dict = {user.user_id:True for user in user_insurance}
for user in all_users:
user_id = user.user_id
# care 完成
if user.user_id in user_insurance_dict:
# 查分数
plan_15_16_can_refund_users.append(user_id)
else:
# care未完成用户 + 非care用户
plan_15_16_not_refund_users.append(user_id)
由于2.7w次的in操作数据量并不是很大,并且列表的in操作在python中优化的效率也很好,所以这里的对字典的in操作并没有减少时间消耗。
第五版
优化点:将in操作转变成集合操作。
在前四版的优化下已经将耗时缩短了 133s,减少了近 92.1% 的耗时,想着这个数据看起来还不错了。隔天早上在刷牙时脑子里思绪纷飞就想到这个事情了。这时忽然想到既然我能查询全部用户,又将完成care用户的用户查询到一个列表中,这时不就是相当于两个集合吗?既然是集合,那么使用集合之间的交集和差集是不是比循环 2.7w 次要快呢?上班之后马上动手来验证这个想法。果然,还能够减少时间消耗,将第四版中的11.42 直接减少了一半,缩短到5.78,缩短近50%。
耗时统计: 5.78 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
all_users_set = set([user.user_id for user in all_users])
plan_15_16_can_refund_users = []
received_user_count = 0
# 所有care完成用户
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_set = set([user.user_id for user in user_insurance])
temp_can_refund_users = all_users_set.intersection(user_insurance_set)
总结
最终优化的结果:
第一版耗时: 144.7 s
最后一版耗时: 5.7 s
优化时间:109 s
优化百分比:95.0%
在各个版本中的优化详细细节如下:
由此可以得出几个结论,帮助减少程序耗时:
结论一:事务不仅能够保证数据原子性,合理使用还能有效减少数据库查询耗时
结论二:集合操作的效率非常高,要善于使用集合减少循环
结论三:字典的查找效率高于列表,但是万次级别的操作无法体验优势
最后的还有一个结论:程序员的灵感似乎在刷牙、上厕所、洗澡、喝水时特别活跃,所以写不出来代码就该去摸摸鱼了。

经过4次优化我把python代码耗时减少95%的更多相关文章
- ROS系统python代码测试之rostest
ROS系统中提供了测试框架,可以实现python/c++代码的单元测试,python和C++通过不同的方式实现, 之后的两篇文档分别详细介绍各自的实现步骤,以及测试结果和覆盖率的获取. ROS系统中p ...
- [转] Python 代码性能优化技巧
选择了脚本语言就要忍受其速度,这句话在某种程度上说明了 python 作为脚本的一个不足之处,那就是执行效率和性能不够理想,特别是在 performance 较差的机器上,因此有必要进行一定的代码优化 ...
- Python代码性能优化技巧
摘要:代码优化能够让程序运行更快,可以提高程序的执行效率等,对于一名软件开发人员来说,如何优化代码,从哪里入手进行优化?这些都是他们十分关心的问题.本文着重讲了如何优化Python代码,看完一定会让你 ...
- 如何让你的Python代码更加pythonic ?
pythonic如果翻译成中文的话就是很python.很+名词结构的用法在中国不少. 以下为了简略,我们用P表示pythonic的写法,NP表示non-pythonic的写法,当然此P-NP非彼P-N ...
- Python 代码性能优化技巧(转)
原文:Python 代码性能优化技巧 Python 代码优化常见技巧 代码优化能够让程序运行更快,它是在不改变程序运行结果的情况下使得程序的运行效率更高,根据 80/20 原则,实现程序的重构.优化. ...
- Python 代码性能优化技巧
选择了脚本语言就要忍受其速度,这句话在某种程度上说明了 python 作为脚本的一个不足之处,那就是执行效率和性能不够理想,特别是在 performance 较差的机器上,因此有必要进行一定的代码优化 ...
- python基础:测量python代码的运行时间
Python社区有句俗语:“python自己带着电池” ,别自己写计时框架.Python 2.3 具备一个叫做 timeit 的完美计时工具可以测量python代码的运行时间. timeit模块 ti ...
- pythonic-让python代码更高效
何为pythonic? pythonic如果翻译成中文的话就是很python.很+名词结构的用法在中国不少,比如:很娘,很国足,很CCTV等等. 我的理解为,很+名词表达了一种特殊和强调的意味.所以很 ...
- 让你的Python代码更加pythonic
http://wuzhiwei.net/be_pythonic/ 何为pythonic? pythonic如果翻译成中文的话就是很python.很+名词结构的用法在中国不少,比如:很娘,很国足,很CC ...
随机推荐
- [转载]Samba 4实现windows匿名访问Linux共享!
SMB(Server Messages Block,信息服务块). 由于NFS(网络文件系统)可以很好的完成Linux与Linux之间的数据共享,因而 Samba较多的用在了Linux与windows ...
- 简单易行的美化方案:Ubuntu 18.04 把启动过程中的紫色美化为黑色
背景 给笔记本装了一个Ubuntu,嫌弃启动的颜色很丑:因此在网上找到了一些修改方法,集成为一个傻瓜脚本. 参考文档: https://askubuntu.com/questions/5065/how ...
- P7736-[NOI2021]路径交点【LGV引理】
正题 题目链接:https://www.luogu.com.cn/problem/P7736 题目大意 有\(k\)层的图,第\(i\)层有\(n_i\)个点,每层的点从上到下排列,层从左到右排列.再 ...
- fastjson将json转为Map<String,String>踩坑
字符串 对于一个json字符串 String str = "{"specItem":"[红, 大]","specName":&qu ...
- 【分享】 一款自用的Anki卡片模板:黄子涵单词卡片 v1
[分享] 一款自用的Anki卡片模板:黄子涵单词卡片 v1 说明 第一代的功能 主要有两部分组成:英文和含义,目前主要是为自己记忆Web前端一些常用的单词而服务 有美美哒背景图,本来想修改为随机背景图 ...
- springcloud整合config组件
config组件 config组件支持两种配置文件获取方式springcould搭建的微服务的配置文件的获取方式有两种.它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中或者本地 ...
- NX CAM 区域轮廓铣的切削步长
从NX3.0到NX9.0,默认都是5%.可是实际计算的精确度是不一样的.到NX8.0上发现计算速度特别慢,后来东找西找,设置这个参数可以解决.PS:请慎用!请后后面的官方解释. 官方的解释是: &qu ...
- Python在Linux下编译安装报错:Makefile:1141:install
正常情况下执行:./configuremake && make install可以直接安装python,但是在在更新了乌版图后居然报错了!!!检查了一圈,发现乌版图安装了python3 ...
- Java只有值传递
二哥,好久没更新面试官系列的文章了啊,真的是把我等着急了,所以特意过来催催.我最近一段时间在找工作,能从二哥的文章中学到一点就多一点信心啊! 说句实在话,离读者 trust you 发给我这段信息已经 ...
- 状压dp学习笔记(紫例题集)
P3451旅游景点 Tourist Attractions 这个代码其实不算是正规题解的(因为我蒟蒻)是在我们的hzoj上内存限制324MIB情况下过掉的,而且经过研究感觉不太能用滚动数组,所以那这个 ...