ResNet学习笔记
ResNet学习笔记
前言
这篇文章实在看完很多博客之后写的,需要读者至少拥有一定的CNN知识,当然我也不知道需要读者有什么水平,所以可能对一些很入门的基本的术语进行部分的解释,也有可能很多复杂的术语因为不好解释而没有解释(主要是懒)。看的时候最好结合论文和百度(谷歌、必应随意开心就好)。
ResNet简介
ResNet全称Deep residual network,中文名深度残差神经网络。因为ResNet在ImageNet等的优秀表现和出色的论文描述,作者何凯明获得了CVPR2016最佳论文奖。
论文原文地址:https://arxiv.org/pdf/1512.03385.pdf
顾名思义,ResNet的精髓在与深度和残差。深度是指模型的深度。在此之前,GoogleNet有22层,VGG有19层,AlexNet只有8层,但是ResNet有152层之多。

从网络层数和模型规模上来看,ResNet的规模远远大于之前的网络。ResNet取得的巨大成功从某种意义上确实源于深度。但是他在模型架构上还通过一种巧妙的方式解决了很多深度网络的问题,这就是残差学习(Residual learnning)。
ResNet的理论
深度学习的层数和训练效果存在必然的联系,从理论上来说,深度学习增加恒等映射层会获得比浅层模型更好地效果,因为从理论上浅层模型是更深层次模型解的一个子空间。但是咋实际中,我们经常会发现随着网络层数的增加,训练误差会上升,这当然不是因为过拟合(过拟合的训练误差会很低很低,相对的可能在验证集效果不好。)主要原因是因为梯度消失和梯度爆炸。这就是深度网络的退化问题。
梯度消失和梯度爆炸(这部分不喜欢可以跳过,我也是复制的)
梯度在高等数学中有了很详细的了解,我相信看这篇文章的铁汁集美也懂得什么叫反向传播,那么自然也就知道什么叫梯度消失和梯度爆炸,那我们是不是可以......(不是)。
好吧还是简单写(chao)一下吧。
反向传播:根据损失函数计算的误差通过反向传播的方式,指导深度网络参数的更新优化。
采取反向传播的原因:首先,深层网络由许多线性层和非线性层堆叠而来,每一层非线性层都可以视为是一个非线性函数\(f(x)\)(非线性来自于非线性激活函数,比如常用的Sigmoid、Tanh、ReLU......),因此整个深度网络可以视为是一个复合的非线性多元函数。
我们最终的目的是希望这个非线性函数很好的完成输入到输出之间的映射,也就是找到让损失函数(Loss function)取得极小值。所以最终的问题就变成了一个寻找函数最小值的问题,在数学上,很自然的就会想到使用梯度下降来解决。
什么?你说梯度下降是什么?额滴神啊!高数中是不是讲过函数的变化率沿着梯度方向变化的最快?我们举个栗子:
求函数\(f(x) = x^2\)的最小值。
求梯度:$$ \frac{\partial f(x)}{\partial x}=2x$$
向梯度的负方向移动特定的步长$$ \Delta x$$
好了又出来一个问题,对于一元函数,方向有两个:正方向和反方向,那么我们为什么往负方向走呢?这就需要泰勒公式来帮忙了。看下面的式子:

左侧是当前x移动一小步之后的下一个位置,他近似等于右边(球球了,泰勒展开不想讲了,自己看高数书吧)我们要找到一个方向,使$$ f(x+ \Delta x)<f(x)$$ (我们要找最小值对吧),根据泰勒公式,显然我们需要另上式中的右侧加号后面小于0。
我们令$$\Delta x = -\alpha \nabla f(x),\alpha >0$$ 阿尔法是一个很小的正数,这在机器学习和深度学习中叫做学习率(看到别人说学习率该知道是啥了)。
所以我们就能将公式进行替换确保 $$ f(x-\alpha \nabla f(x))<f(x)$$。
下面就比较简单了,更新即可,这也就是所谓的沿负梯度方向更新。
回归正题,在梯度更新的过程中,以最简单的网络结构为例,加入有三个隐藏层,每层的神经元个数都是1,且对应的非线性函数为(其中
为某个激活函数)如下图:

现在假设我们需要更新参数 ,那么我们就要求出损失函数对参数
的导数,根据链式法则,可以写成下面这样:
而对于激活函数,之前一直使用Sigmoid函数,其函数图像成一个S型,如下所示,它会将正无穷到负无穷的数映射到0~1之间:

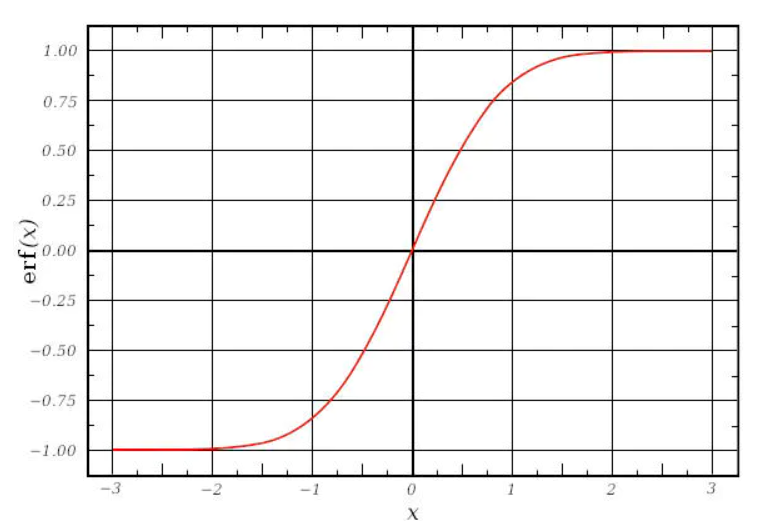
当我们对Sigmoid函数求导时,得到其结果如下:
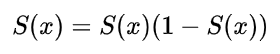
由此可以得到它Sigmoid函数图像,呈现一个驼峰状(很像高斯函数)

从求导结果可以看出,Sigmoid导数的取值范围在0~0.25之间,而我们初始化的网络权值通常都小于1,因此,当层数增多时,小于0的值不断相乘,最后就导致梯度消失的情况出现。同理,梯度爆炸的问题也就很明显了,就是当权值
过大时,导致
,最后大于1的值不断相乘,就会产生梯度爆炸。
残差学习是什么?
我们回到论文中的一张图片:

这是一个小块,定义是这样的:
\]
这个小块有两个分支映射(mapping):
identity mapping,指的是上图右边那条弯的曲线。顾名思义,identity mapping指的就是本身的映射,也就是
自身;
residual mapping,指的是另一条分支,也就是
部分,这部分称为残差映射,也就是
。
激活函数使用ReLU。
我们求得从浅层 到深层
的学习特征为:
利用链式规则,可以求得反向过程的梯度:
式子的第一个因子 表示的损失函数到达
的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
ResNet的网络结构
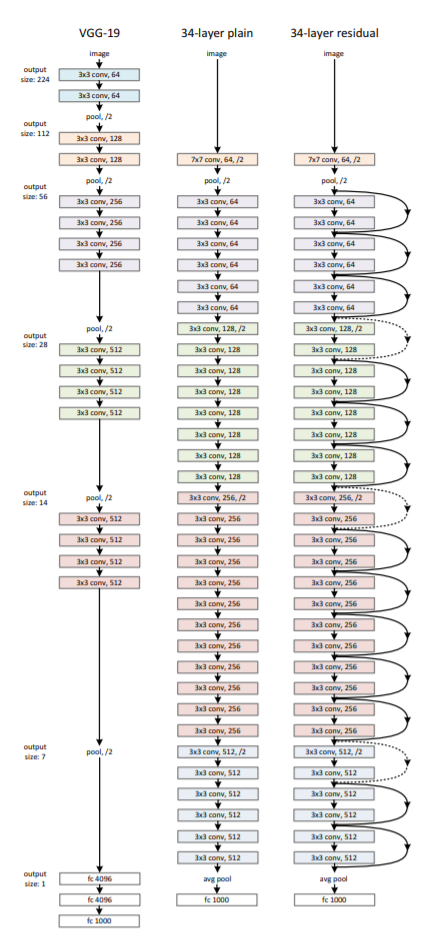
论文中给出了几种不同层次的网络结构,这里使用最简单的18层结构进行编码。
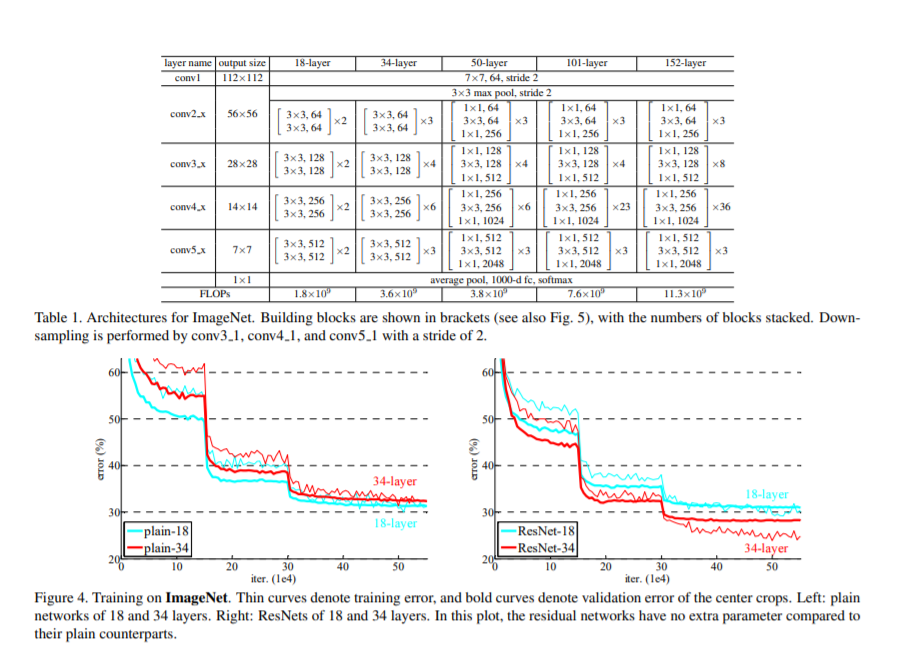

ResNet的18层模型构建代码:
from keras.layers import Input
from keras.layers import Conv2D, MaxPool2D, Dense, BatchNormalization, Activation, add, GlobalAvgPool2D
from keras.models import Model
from keras import regularizers
from keras.utils import plot_model
from keras import backend as K
def conv2d_bn(x, nb_filter, kernel_size, strides=(1, 1), padding='same'):
"""
conv2d -> batch normalization -> relu activation
"""
x = Conv2D(nb_filter, kernel_size=kernel_size,
strides=strides,
padding=padding,
kernel_regularizer=regularizers.l2(0.0001))(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
return x
def shortcut(input, residual):
"""
shortcut连接,也就是identity mapping部分。
"""
input_shape = K.int_shape(input)
residual_shape = K.int_shape(residual)
stride_height = int(round(input_shape[1] / residual_shape[1]))
stride_width = int(round(input_shape[2] / residual_shape[2]))
equal_channels = input_shape[3] == residual_shape[3]
identity = input
# 如果维度不同,则使用1x1卷积进行调整
if stride_width > 1 or stride_height > 1 or not equal_channels:
identity = Conv2D(filters=residual_shape[3],
kernel_size=(1, 1),
strides=(stride_width, stride_height),
padding="valid",
kernel_regularizer=regularizers.l2(0.0001))(input)
return add([identity, residual])
def basic_block(nb_filter, strides=(1, 1)):
"""
基本的ResNet building block,适用于ResNet-18和ResNet-34.
"""
def f(input):
conv1 = conv2d_bn(input, nb_filter, kernel_size=(3, 3), strides=strides)
residual = conv2d_bn(conv1, nb_filter, kernel_size=(3, 3))
return shortcut(input, residual)
return f
def residual_block(nb_filter, repetitions, is_first_layer=False):
"""
构建每层的residual模块,对应论文参数统计表中的conv2_x -> conv5_x
"""
def f(input):
for i in range(repetitions):
strides = (1, 1)
if i == 0 and not is_first_layer:
strides = (2, 2)
input = basic_block(nb_filter, strides)(input)
return input
return f
def resnet_18(input_shape=(224,224,3), nclass=1000):
"""
build resnet-18 model using keras with TensorFlow backend.
:param input_shape: input shape of network, default as (224,224,3)
:param nclass: numbers of class(output shape of network), default as 1000
:return: resnet-18 model
"""
input_ = Input(shape=input_shape)
conv1 = conv2d_bn(input_, 64, kernel_size=(7, 7), strides=(2, 2))
pool1 = MaxPool2D(pool_size=(3, 3), strides=(2, 2), padding='same')(conv1)
conv2 = residual_block(64, 2, is_first_layer=True)(pool1)
conv3 = residual_block(128, 2, is_first_layer=True)(conv2)
conv4 = residual_block(256, 2, is_first_layer=True)(conv3)
conv5 = residual_block(512, 2, is_first_layer=True)(conv4)
pool2 = GlobalAvgPool2D()(conv5)
output_ = Dense(nclass, activation='softmax')(pool2)
model = Model(inputs=input_, outputs=output_)
model.summary()
return model
ResNet学习笔记的更多相关文章
- 深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结 写于:2019.03.15—大连理工大学 论文名称:Deep Residual Learning for Image Recognition 作者:微软亚洲研究院的何凯 ...
- tensorflow学习笔记——图像识别与卷积神经网络
无论是之前学习的MNIST数据集还是Cifar数据集,相比真实环境下的图像识别问题,有两个最大的问题,一是现实生活中的图片分辨率要远高于32*32,而且图像的分辨率也不会是固定的.二是现实生活中的物体 ...
- 官网实例详解-目录和实例简介-keras学习笔记四
官网实例详解-目录和实例简介-keras学习笔记四 2018-06-11 10:36:18 wyx100 阅读数 4193更多 分类专栏: 人工智能 python 深度学习 keras 版权声明: ...
- CTR学习笔记&代码实现5-深度ctr模型 DeepCrossing -> DCN
之前总结了PNN,NFM,AFM这类两两向量乘积的方式,这一节我们换新的思路来看特征交互.DeepCrossing是最早在CTR模型中使用ResNet的前辈,DCN在ResNet上进一步创新,为高阶特 ...
- CTR学习笔记&代码实现6-深度ctr模型 后浪 xDeepFM/FiBiNET
xDeepFM用改良的DCN替代了DeepFM的FM部分来学习组合特征信息,而FiBiNET则是应用SENET加入了特征权重比NFM,AFM更进了一步.在看两个model前建议对DeepFM, Dee ...
- fpn(feature-Pyramid-network)学习笔记
FPN(特征金字塔网络)学习笔记 论文 在物体检测里面,有限计算量情况下,网络的深度(对应到感受野)与 stride 通常是一对矛盾的东西,常用的网络结构对应的 stride 一般会比较大(如 32) ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
- PHP-会员登录与注册例子解析-学习笔记
1.开始 最近开始学习李炎恢老师的<PHP第二季度视频>中的“章节5:使用OOP注册会员”,做一个学习笔记,通过绘制基本页面流程和UML类图,来对加深理解. 2.基本页面流程 3.通过UM ...
随机推荐
- CMDB项目要点总结之中控机
1.基于paramiko对远程主机执行命令操作 秘钥形式 private_key = paramiko.RSAKey.from_private_key_file('c:/Users/用户名/.ssh/ ...
- 去哪找Java练手项目?
经常有读者在微信上问我: 在学编程的过程中,看了不少书.视频课程,但是看完.听完之后感觉还是不会编程,想找一些项目来练手,但是不知道去哪儿找? 类似的问题,有不少读者问,估计是大部分人的困惑. 练手项 ...
- 最权威的html 标签属性大全
<p>---恢复内容开始---</p>1.html标签 <marquee>...</marquee>普通卷动 <marquee behavior= ...
- effective解读-第一条 静态工厂创建对象代替构造器
好处 有名称,能见名知意.例如BigInteger的probablePrime方法 享元模式.单例模式中使用 享元模式:创建对象代价很高,重复调用已有对象,例如数据库连接等.享元模式是单例模式的一个拓 ...
- SQL排名问题,100% leetcode答案大公开!
(首先原谅我最近新番看多了,起了一个中二的名字) 最近在找实习,所以打算系统总结(复习)一下sql中经常遇到问题.不管是刷leetcode还是牛客的sql题,有一个问题总是绕不开的,那就是排名问题.其 ...
- PHP并发抢购解决方案
Mysql版 逻辑步骤 mysql存储引擎使用Innodb 开始事务,查询商品库存并加上共享锁 判断库存是否足够,进行商品/订单/用户等操作 提交事务,完成下单抢购 代码参考 // 关闭自动提交 $t ...
- thinkphp 5.1框架利用及rce分析
前言 上个学期钻研web渗透的时候接触过几个tp的框架,但那时候还没有写blog的习惯,也没有记录下来,昨天在做ctf的时候正好碰到了一个tp的框架,想起来就复现一下 正文 进入网站,标准笑脸,老tp ...
- 抗DDOS应急预案实践-生产环境总结-建议必看
一.首先摸清楚环境与资源 为DDoS应急预案提供支撑 所在的网络环境中,有多少条互联网出口?每一条带宽多少? 每一条互联网出口的运营商是否支持DDoS攻击清洗,我们是否购买,或可以紧急试用?当发生DD ...
- 全网最详细的Linux命令系列-ls命令
Linux开始必须要会的命令当属ls,在日常工作中用到ls命令时的频率是很多的,作为一个初学者,可能我只会或者顶多ls -l两种用法.但是ls其实是一个非常实用的指令,ls命令就是list的缩写,ls ...
- 3步安装Python虚拟环境virtualenv
1. pip安装必要库 pip install virtualenv -i https://pypi.douban.com/simple pip install virtualenvwrapper - ...