linux 之awk--格式化文本信息
https://www.cnblogs.com/xudong-bupt/p/3721210.html
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
awk处理过程: 依次对每一行进行处理,然后输出
awk命令形式:
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
' ' 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令
; 多条命令使用分号分隔
END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
特殊要点:
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量变量
NR 每行的记录号,多文件记录递增
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
\t 制表符
\n 换行符
FS BEGIN时定义分隔符
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~ 匹配,与==相比不是精确比较
!~ 不匹配,不精确比较
== 等于,必须全部相等,精确比较
!= 不等于,精确比较
&& 逻辑与
|| 逻辑或
- 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]/ 一个或一个以上数字
FILENAME 文件名
OFS 输出字段分隔符, 默认也是空格,可以改为制表符等
ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F'[:#/]' 定义三个分隔符
print & $0
print 是awk打印指定内容的主要命令
awk '{print}' /etc/passwd == awk '{print $0}' /etc/passwd
awk '{print " "}' /etc/passwd //不输出passwd的内容,而是输出相同个数的空行,进一步解释了awk是一行一行处理文本
awk '{print "a"}' /etc/passwd //输出相同个数的a行,一行只有一个a字母
awk -F":" '{print $1}' /etc/passwd
awk -F: '{print $1; print $2}' /etc/passwd //将每一行的前二个字段,分行输出,进一步理解一行一行处理文本
awk -F: '{print $1,$3,$6}' OFS="\t" /etc/passwd //输出字段1,3,6,以制表符作为分隔符
-f指定脚本文件
awk -f script.awk file
BEGIN{
FS=":"
}
{print $1} //效果与awk -F":" '{print $1}'相同,只是分隔符使用FS在代码自身中指定
awk 'BEGIN{X=0} /^$/{ X+=1 } END{print "I find",X,"blank lines."}' test
I find 4 blank lines.
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is",sum}' //计算文件大小
total size is 17487
-F指定分隔符
$1 指指定分隔符后,第一个字段,$3第三个字段, \t是制表符
一个或多个连续的空格或制表符看做一个定界符,即多个空格看做一个空格
awk -F":" '{print $1}' /etc/passwd
awk -F":" '{print $1 $3}' /etc/passwd //$1与$3相连输出,不分隔
awk -F":" '{print $1,$3}' /etc/passwd //多了一个逗号,$1与$3使用空格分隔
awk -F":" '{print $1 " " $3}' /etc/passwd //$1与$3之间手动添加空格分隔
awk -F":" '{print "Username:" $1 "\t\t Uid:" $3 }' /etc/passwd //自定义输出
awk -F: '{print NF}' /etc/passwd //显示每行有多少字段
awk -F: '{print $NF}' /etc/passwd //将每行第NF个字段的值打印出来
awk -F: 'NF4 {print }' /etc/passwd //显示只有4个字段的行
awk -F: 'NF>2{print $0}' /etc/passwd //显示每行字段数量大于2的行
awk '{print NR,$0}' /etc/passwd //输出每行的行号
awk -F: '{print NR,NF,$NF,"\t",$0}' /etc/passwd //依次打印行号,字段数,最后字段值,制表符,每行内容
awk -F: 'NR5{print}' /etc/passwd //显示第5行
awk -F: 'NR5 || NR6{print}' /etc/passwd //显示第5行和第6行
route -n|awk 'NR!=1{print}' //不显示第一行
//匹配代码块
//纯字符匹配 !//纯字符不匹配 ~//字段值匹配 !~//字段值不匹配 ~/a1|a2/字段值匹配a1或a2
awk '/mysql/' /etc/passwd
awk '/mysql/{print }' /etc/passwd
awk '/mysql/{print $0}' /etc/passwd //三条指令结果一样
awk '!/mysql/{print $0}' /etc/passwd //输出不匹配mysql的行
awk '/mysql|mail/{print}' /etc/passwd
awk '!/mysql|mail/{print}' /etc/passwd
awk -F: '/mail/,/mysql/{print}' /etc/passwd //区间匹配
awk '/[2][7][7]/{print $0}' /etc/passwd //匹配包含27为数字开头的行,如27,277,2777...
awk -F: '$1~/mail/{print $1}' /etc/passwd //$1匹配指定内容才显示
awk -F: '{if($1~/mail/) print $1}' /etc/passwd //与上面相同
awk -F: '$1!~/mail/{print $1}' /etc/passwd //不匹配
awk -F: '$1!~/mail|mysql/{print $1}' /etc/passwd
IF语句
必须用在{}中,且比较内容用()扩起来
awk -F: '{if($1~/mail/) print $1}' /etc/passwd //简写
awk -F: '{if($1~/mail/) {print $1}}' /etc/passwd //全写
awk -F: '{if($1~/mail/) {print $1} else {print $2}}' /etc/passwd //if...else...
条件表达式
== != > >=
awk -F":" '$1"mysql"{print $3}' /etc/passwd
awk -F":" '{if($1"mysql") print $3}' /etc/passwd //与上面相同
awk -F":" '$1!="mysql"{print $3}' /etc/passwd //不等于
awk -F":" '$3>1000{print $3}' /etc/passwd //大于
awk -F":" '$3>=100{print $3}' /etc/passwd //大于等于
awk -F":" '$3<1{print $3}' /etc/passwd //小于
awk -F":" '$3<=1{print $3}' /etc/passwd //小于等于
逻辑运算符
&& ||
awk -F: '$1~/mail/ && $3>8 {print }' /etc/passwd //逻辑与,$1匹配mail,并且$3>8
awk -F: '{if($1~/mail/ && $3>8) print }' /etc/passwd
awk -F: '$1~/mail/ || $3>1000 {print }' /etc/passwd //逻辑或
awk -F: '{if($1~/mail/ || $3>1000) print }' /etc/passwd
数值运算
awk -F: '$3 > 100' /etc/passwd
awk -F: '$3 > 100 || $3 < 5' /etc/passwd
awk -F: '$3+$4 > 200' /etc/passwd
awk -F: '/mysql|mail/{print $3+10}' /etc/passwd //第三个字段加10打印
awk -F: '/mysql/{print $3-$4}' /etc/passwd //减法
awk -F: '/mysql/{print $3*$4}' /etc/passwd //求乘积
awk '/MemFree/{print $2/1024}' /proc/meminfo //除法
awk '/MemFree/{print int($2/1024)}' /proc/meminfo //取整
输出分隔符OFS
awk '$6 ~ /FIN/ || NR1 {print NR,$4,$5,$6}' OFS="\t" netstat.txt
awk '$6 ~ /WAIT/ || NR1 {print NR,$4,$5,$6}' OFS="\t" netstat.txt
//输出字段6匹配WAIT的行,其中输出每行行号,字段4,5,6,并使用制表符分割字段
输出处理结果到文件
①在命令代码块中直接输出 route -n|awk 'NR!=1{print > "./fs"}'
②使用重定向进行输出 route -n|awk 'NR!=1{print}' > ./fs
格式化输出
netstat -anp|awk '{printf "%-8s %-8s %-10s\n",$1,$2,$3}'
printf表示格式输出
%格式化输出分隔符
-8长度为8个字符
s表示字符串类型
打印每行前三个字段,指定第一个字段输出字符串类型(长度为8),第二个字段输出字符串类型(长度为8),
第三个字段输出字符串类型(长度为10)
netstat -anp|awk '$6"LISTEN" || NR1 {printf "%-10s %-10s %-10s \n",$1,$2,$3}'
netstat -anp|awk '$6"LISTEN" || NR1 {printf "%-3s %-10s %-10s %-10s \n",NR,$1,$2,$3}'
IF语句
awk -F: '{if($3>100) print "large"; else print "small"}' /etc/passwd
small
small
small
large
small
small
awk -F: 'BEGIN{A=0;B=0} {if($3>100) {A++; print "large"} else {B++; print "small"}} END{print A,"\t",B}' /etc/passwd
//ID大于100,A加1,否则B加1
awk -F: '{if($3<100) next; else print}' /etc/passwd //小于100跳过,否则显示
awk -F: 'BEGIN{i=1} {if(i<NF) print NR,NF,i++ }' /etc/passwd
awk -F: 'BEGIN{i=1} {if(i<NF) {print NR,NF} i++ }' /etc/passwd
另一种形式
awk -F: '{print ($3>100 ? "yes":"no")}' /etc/passwd
awk -F: '{print ($3>100 ? $3":\tyes":$3":\tno")}' /etc/passwd
while语句
awk -F: 'BEGIN{i=1} {while(i<NF) print NF,$i,i++}' /etc/passwd
7 root 1
7 x 2
7 0 3
7 0 4
7 root 5
7 /root 6
数组
netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) print i,"\t",a[i]}'
netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) printf "%-20s %-10s %-5s \n", i,"\t",a[i]}'
9523 1
9929 1
LISTEN 6
7903 1
3038/cupsd 1
7913 1
10837 1
9833 1
应用1
awk -F: '{print NF}' helloworld.sh //输出文件每行有多少字段
awk -F: '{print $1,$2,$3,$4,$5}' helloworld.sh //输出前5个字段
awk -F: '{print $1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //输出前5个字段并使用制表符分隔输出
awk -F: '{print NR,$1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //制表符分隔输出前5个字段,并打印行号
应用2
awk -F'[:#]' '{print NF}' helloworld.sh //指定多个分隔符: #,输出每行多少字段
awk -F'[:#]' '{print $1,$2,$3,$4,$5,$6,$7}' OFS='\t' helloworld.sh //制表符分隔输出多字段
应用3
awk -F'[:#/]' '{print NF}' helloworld.sh //指定三个分隔符,并输出每行字段数
awk -F'[:#/]' '{print $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12}' helloworld.sh //制表符分隔输出多字段
应用4
计算/home目录下,普通文件的大小,使用KB作为单位
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",sum/1024,"KB"}'
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",int(sum/1024),"KB"}' //int是取整的意思
应用5
统计netstat -anp 状态为LISTEN和CONNECT的连接数量分别是多少
netstat -anp|awk '$6~/LISTEN|CONNECTED/{sum[$6]++} END{for (i in sum) printf "%-10s %-6s %-3s \n", i," ",sum[i]}'
应用6
统计/home目录下不同用户的普通文件的总数是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]++} END{for (i in sum) printf "%-6s %-5s %-3s \n",i," ",sum[i]}'
mysql 199
root 374
统计/home目录下不同用户的普通文件的大小总size是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]+=$5} END{for (i in sum) printf "%-6s %-5s %-3s %-2s \n",i," ",sum[i]/1024/1024,"MB"}'
应用7
输出成绩表
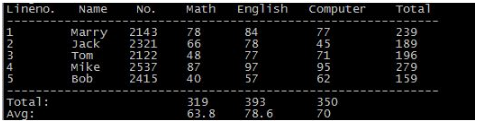
awk 'BEGIN{math=0;eng=0;com=0;printf "Lineno. Name No. Math English Computer Total\n";printf "------------------------------------------------------------\n"}{math+=$3; eng+=$4; com+=$5;printf "%-8s %-7s %-7s %-7s %-9s %-10s %-7s \n",NR,$1,$2,$3,$4,$5,$3+$4+$5} END{printf "------------------------------------------------------------\n";printf "%-24s %-7s %-9s %-20s \n","Total:",math,eng,com;printf "%-24s %-7s %-9s %-20s \n","Avg:",math/NR,eng/NR,com/NR}' test0
[root@localhost home]# cat test0
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
linux 之awk--格式化文本信息的更多相关文章
- Linux用awk处理文本数据
awk -F',' -v OFS='\t' 'NR>1{print $1, $4, $6, $7}' demo2.csv | sort -t $'\t' -k 1 -r
- linux的awk命令解读
转自:http://blog.csdn.net/guoer9973/article/details/44650729 awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理 ...
- [转帖]Linux中awk工具的使用
Linux中awk工具的使用 2018年10月09日 17:26:20 谢公子 阅读数 2170更多 分类专栏: linux系统安全 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权 ...
- [转]linux之awk命令
转自:http://blog.chinaunix.net/uid-23302288-id-3785105.html awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓 ...
- Linux的awk命令详解
awkawk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,默认以空格为分隔符将每行切片,切开的部分再 ...
- linux系统awk命令
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息awk处理过程:?依次对每一行进行处理,然后输出awk命令形式:awk [-F|-f ...
- 格式化文本数据抽取工具awk
在管理和维护Linux系统过程中,有时可能需要从一个具有一定格式的文本(格式化文本)中抽取数据,这时可以使用awk编辑器来完成这项任务.发明这个工具的作者是Aho.Weinberg和Kernighan ...
- Linux常用基本命令:三剑客命令之-awk格式化动作
我们之前说过,awk是一个超强的文本格式化工具,而本文的printf动作就是经常用来做格式化文本的.使用方式跟c语言的printf差不多. 1,printf默认不会回车换行 ghostwu@dev:~ ...
- 从XML文件中获取格式化的文本信息
在FMW的运维过程中,时常需要将中间传输的XML信息转换为excel格式化的问题提交给关联系统人员,现总结三种格式化问题提供方式 一.使用Excel转换 因为从系统中取到的xml文档为中间信息文档,需 ...
随机推荐
- 【NX二次开发】UF_CSYS_map_point()函数,绝对坐标,工作坐标,部件之间坐标转换。
UF_CSYS_map_point用来变换点的坐标,比较简单且实用.例如工作坐标系与绝对坐标系转换,一个部件的坐标与另一个部件坐标系之间的转换.下面的例子是在三个坐标下创建三个点相对坐标为{10,50 ...
- 【C++】类
一个简单例子: 1 //c++ 类 2 #include<iostream> 3 using namespace std; 4 class Point 5 { 6 private: 7 i ...
- 深度解密:Java与线程的关系
并发不一定要依赖多线程(如PHP的多进程并发),但在Java中谈论并发,大多数都与线程脱不开关系. 线程的实现 线程是CPU调度的基本单位,Thread类与大部分的Java API有显著的差别,它的所 ...
- docker-compose 部署 Apollo 自定义环境
Apollo 配置中心是什么: Apollo是携程框架部门研发的开源配置管理中心,能够集中化管理应用不同环境.不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限.流程治理等特性. ...
- 基于ABP落地领域驱动设计-05.实体创建和更新最佳实践
目录 系列文章 数据传输对象 输入DTO最佳实践 不要在输入DTO中定义不使用的属性 不要重用输入DTO 输入DTO中验证逻辑 输出DTO最佳实践 对象映射 学习帮助 系列文章 基于ABP落地领域驱动 ...
- <5人公司极简研发方案
人过35,被年轻人卷走了一大半,还停留在这个行业的,不是在创业,就是在创业的路上. 创业很难,刚开始没钱没人,啥都要自己干,一个字累.好处是地基是自己搭的,心里有底.不过博主最近健忘的毛病愈发严重了, ...
- 在线CRM系统对企业的好处有哪些
随着信息技术的飞速发展,每个企业都希望通过互联网技术来让自身发展壮大.由于强大的管理能力和技术手段,在线CRM系统成为了企业用来管理自身获得发展的最佳选择.那么在线CRM系统对企业来说有哪些好处呢?本 ...
- acwing 4 多重背包问题 I
多重背包 有 n种物品 一共有 m大小的背包,每种物品的价值 大小 个数 为 s[i],v[i],num[i]; #include<bits/stdc++.h>//cmhao #defin ...
- Go:go程序报错Cannot run program "C:\Users\dell\AppData\Local\Temp\___go_build_hello_go.exe" (in directory "…………"):该版本的 %1 与你运行的 Windows 版本不兼容。
问题截图 在go语言编译的时候,如果只是单单编译一个文件的话,package必须是main,意味着是可以单独编译的. 解决办法 修改为 package main 就可以 再次运行就可以啦. 文章转载至 ...
- 资源:zookeeper下载地址
提供zookeeper下载地址:https://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/