【论文阅读】DSDNet Deep Structured self-Driving Network
前言引用
[2] DSDNet Deep Structured self-Driving Network Wenyuan Zeng, Shenlong Wang, Renjie Liao, Yun Chen, Bin Yang, Raquel Urtasun (ECCV 2020)
从这里我们进入了比较正式的期刊论文(我其实挺喜欢NVIDIA的写作风格类似于报告 但是比较易懂 让我们下次看看这篇吧)正式所以摘要很少 hhh
摘要
万事从摘要开始:
In this paper, we propose the Deep Structured self-Driving Network (DSDNet), which performs object detection, motion prediction, and motion planning with a single neural network. Towards this goal, we develop a deep structured energy based model which considers the interactions between actors and produces socially consistent multimodal future predictions. Furthermore, DSDNet explicitly exploits the predicted future distributions of actors to plan a safe maneuver by using a structured planning cost. Our sample-based formulation allows us to overcome the di culty in probabilistic inference of continuous random variables. Experiments on a number of large-scale self driving datasets demonstrate that our model signi cantly outperforms the state-of-the-art.
碎碎念:这次的摘要很短,如果只看摘要可能会很疑惑,比如interactions between actors, produces socially(socially还能数据化?->其实就是预测其他车的运动), 基于样本去formulation, probabilistic inference of continuous random variables(直译:连续随机变量的概率推理 这是指哪个现象呢 )前面两个在介绍部分就解释了一下
1.interactions between actors:指其中一个的actor的行为会影响到其他的actor(actor翻译成对象还是啥好呢 所以就中英夹杂了)
2.produces socially consistent multimodal future predictions:虽然我还是没能理解socially?可能是语言上?但是从介绍部分这个就是1.的延伸,行为会相互影响所以 model the future motions of actors with multi-modal distributions就是十分重要的。
所以这篇文章干的事情就是:输入数据,三个分支(但是一张网?此点待看)对于规划的cost function采取基于样本的形式(数据+人为),明显和上一个NVIDIA的暴力学习不同的是,1.加入了概率模型去预测未来在决定驾驶,2.prediction module uses an energy-based formulation to explicitly capture the interactions among actors and xxx(见介绍的最后部分),3.训练集采用的开源 2个真实世界,1个CARLA仿真见[6][15,39]的参考出处可得
Contribution
- Our prediction module uses an energy-based formulation to explicitly capture the interactions among actors and predict multiple future outcomes with calibrated uncertainty.
- Our planning module considers multiple possibilities of how the future might unroll, and outputs a safe trajectory for the self-driving car that respects the laws of traffic and is compliant with other actors.
- We address the costly probabilistic inference with a sample-based framework.
Method
从开头的这两幅图结合介绍看,对整个框架应该可以认识的很快
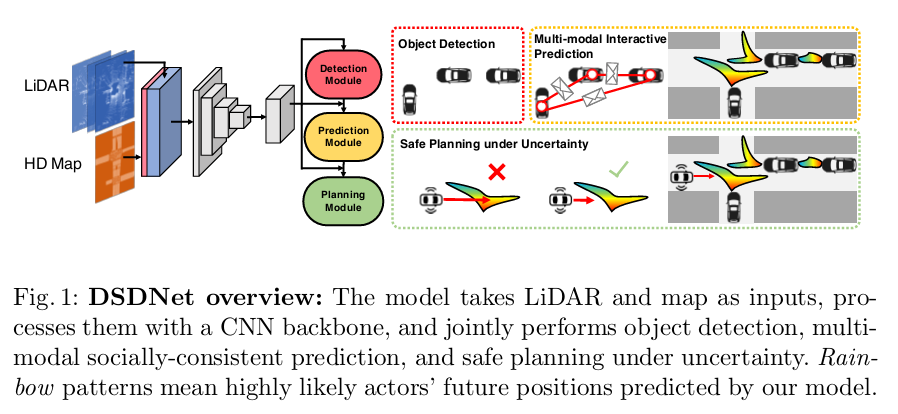
从第一个看,用一个CNN框架,共同细分了三个模块【所以是咋细分的呢?输出三个模块?输出信息呢?】
右边的safe planning under uncertainty很有意思,考虑了socially-consistent prediction
原文:In this work, we further enhance the model capacity with a non-parametric explicit distribution construed over a dense set of trajectory samples.【这个也没看懂 可能是基础问题 non-parametric explicit distribution?】
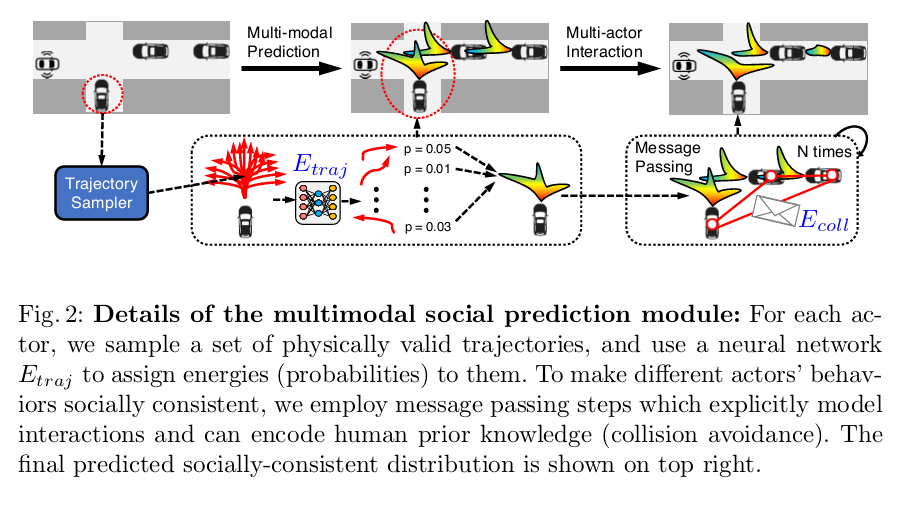
Structured models and Belief Propagation:
To encode prior knowledge, there is a recent surge of deep structured models, which use deep neural networks (DNNs) to provide the energy terms of a probabilistic graphical models (PGMs).
进入Method,这一部分的方法特别长(主要我想理解 所以有点想解释清楚),最好对着论文看比较好...
框架 - backbone
整个框架的输入:We rasterize the lanes with different semantics into different channels and concatenate them with 3D LiDAR tensor to form our input representation.
将不同的semantics与3D LiDAR tensor整合起来,整合得到的3D tensor再通过深度卷积网络去计算出a backbone feature map \(F \in \mathbb R{^{H \times W \times C}}\),使用两个卷积网络分开F,一个是识别位置上是否有其他actor,其余一个是返回每个actor的位置,大小,方位和速度。再讲这个feature map作为prediction和planning modules 的输入去生成actors' 行为分布和safe planning maneuver.
多社会模型概率预测? - Probabilistic Multimodal Social Prediction
(不知道怎么翻译这个小标题了) 为了计划安全的行驶行为,我们就得预测其他的actors是什么行为。 we represent their possible future behavior using a trajectory defined as a sequence of 2D waypoints on birds eye view sampled at \(T\) discrete timestamps.
️将输出参数化:每当一个测量周期就更新一次所有actors'概率,那么概率是怎么表示的呢?\(s_i \in \mathbb R^{T \times 2}\) be the future trajectory of the i-th actor. 这是一个单独的整个\(p(s_1,\ldots , s_N|X)\),这个整体的联合概率没有高效的计算方式。
️对所有的agent未来预测行为建模:Here, we propose to approximate this high-dimensional continuous space with a finite number of samples. 所以本文采用的是采样的方法 randomly sample K possible future trajectory. 为确保采样的diverse, dense and physically plausible(离散又密集?diverse and dense?奇怪点) we follow the Neural Motion Planner (NMP) and use a combination of straight, circle and clothoid curves. 总公式如下:
\]
式子中w是学习的参数,X是传感器原始数据,Z是actors' 所有可能的状态。\(Z=\sum exp(-E(\hat s_1^{k_1}, \ldots,s_N^{k_N}))\) 这里为了让整个框架有可解释性,就像人们驾驶车的感觉和交规方面。比如,我们会尽可能的smoothly along the road and avoid collision with each other. Therefore, we decompose the energy E into two terms.(这里的energy E 在MIT老教授的线性代数里正定也看到过 energy test,但是实际的意义到底是什么呢?能量?还是就是一种cost function的表示?)
\]
N是检测的agent总数,w还是学习到的参数
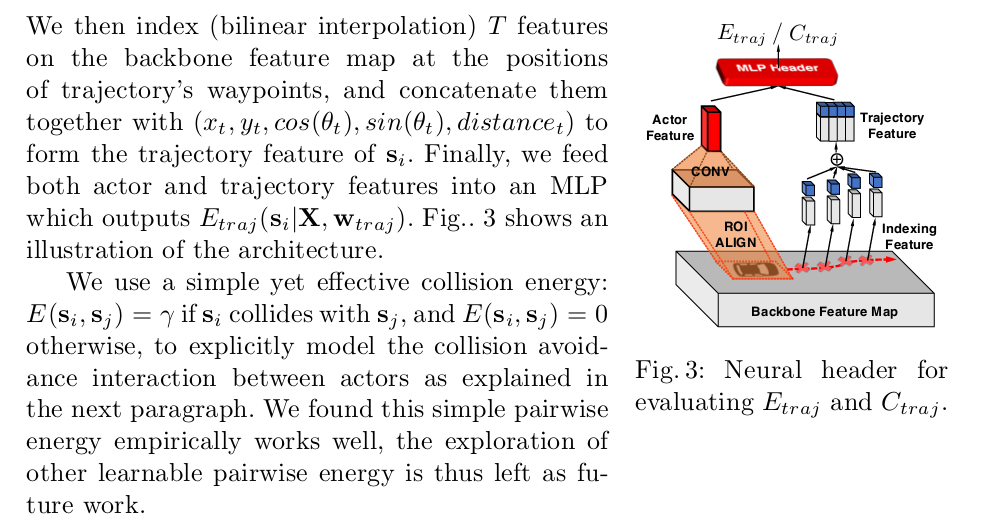
因为前部分的\(E_{traj}\)很难定义,所以这里使用了一层神经网络去学习,输入:传感器数据\(X\)和计划好的路径\(s_i\),输出a scalar value.
下图是更为详细的解释和框架图:
️Message Passing inference:we thus conduct marginal inference over the joint distribution. (这里的marginal inference就不是很懂了?) 我们使用sum-product message passing去预测每一个actor的边缘分布,然后再将其他actors的影响marginalization. 这样得出的边缘概率\(p(s_i|X,w)\)反映出了actor行为的不确定性和multimodality(这个词也不懂),and will be leveraged by our planner. 在每一次迭代行为里更新每个actor \((s_i)\)
\]
这个式子中的\(m_{ij}\)是我一直疑惑的 为什么message可以直接这样表示 或者说这个message的格式信息?想要表达的东西?原文中 \(m_{ij}\) is the message sent from actor i to actor j and \(\propto\) means equal up to a normalization constant. 这个消息传输的过程就是 actors之间互相交流他们未来intention \(s_i\) and how probable those intentions are \(E_{traj}(s_i)\) 而碰撞的可以帮助不同的额actors之间coordinate intentions,这样就算行为复杂也不会产生碰撞。经过消息的传递迭代后,我们可以得出大概的边界概率如下:
\]
在不确定情况下安全的运动规划
The motion planning module fulfills our final goal, that is, navigating towards a destination while avoiding collision and obeying traffic rules. 所以为了量化这个目标,我们构建了cost function C, 更低的cost意味着这条路更好,构建完成后 planning的工作就是找到min cost的trajectory
\]
while \(\tau^*\) the planned optimal trajectory and \(\rm P\) the set of physically realizable trajectories 满足车辆的动力学模型
再到整个Planning Cost
\]
\(C_{traj}\)就是用神经网络学习到的车辆轨迹,\(E_{traj}\)是预测模块,使用了trajectory feature和ROIAlign 从backbone 特征图中提取出来并计算this scalar cost value. \(C_{coll}(\tau,s_i)=\lambda\) if \(\tau\) and \(s_i\) colide, and 0 otherwise,也就是就散得到的planned optimal trajectory如果和任何一个actor撞到了都是不可行的,这样就能保证车辆行驶安全
学习
这一部分我们直接将所有的模型(backbone, detection, prediction and planning)通过一个multi-class loss 联合训练
\]
\(\alpha\)和\(\beta\)是常量超参数,这样的multi-task loss can fully exploit the supervision for each task and help the training. 如果只有前者的\(\mathcal{L}_{planning}\) 那就损失了预测和检测的更为合理的学习,更具可解释性?(但是这样不会重复吗?planning那块的学习就包含住了预测检测的一部分)
Limitation
自己的一些想法
【论文阅读】DSDNet Deep Structured self-Driving Network的更多相关文章
- 【论文阅读】Deep Mixture of Diverse Experts for Large-Scale Visual Recognition
导读: 本文为论文<Deep Mixture of Diverse Experts for Large-Scale Visual Recognition>的阅读总结.目的是做大规模图像分类 ...
- 【论文阅读】Deep Adversarial Subspace Clustering
导读: 本文为CVPR2018论文<Deep Adversarial Subspace Clustering>的阅读总结.目的是做聚类,方法是DASC=DSC(Deep Subspace ...
- 【CV论文阅读】Deep Linear Discriminative Analysis, ICLR, 2016
DeepLDA 并不是把LDA模型整合到了Deep Network,而是利用LDA来指导模型的训练.从实验结果来看,使用DeepLDA模型最后投影的特征也是很discriminative 的,但是很遗 ...
- 论文阅读:Relation Structure-Aware Heterogeneous Information Network Embedding
Relation Structure-Aware Heterogeneous Information Network Embedding(RHINE) (AAAI 2019) 本文结构 (1) 解决问 ...
- 论文阅读 DynGEM: Deep Embedding Method for Dynamic Graphs
2 DynGEM: Deep Embedding Method for Dynamic Graphs link:https://arxiv.org/abs/1805.11273v1 Abstract ...
- 【论文阅读】Deep Mutual Learning
文章:Deep Mutual Learning 出自CVPR2017(18年最佳学生论文) 文章链接:https://arxiv.org/abs/1706.00384 代码链接:https://git ...
- 三维目标检测论文阅读:Deep Continuous Fusion for Multi-Sensor 3D Object Detection
题目:Deep Continuous Fusion for Multi-Sensor 3D Object Detection 来自:Uber: Ming Liang Note: 没有代码,主要看思想吧 ...
- 【论文阅读】Deep Clustering for Unsupervised Learning of Visual Features
文章:Deep Clustering for Unsupervised Learning of Visual Features 作者:Mathilde Caron, Piotr Bojanowski, ...
- [论文阅读]VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(VGGNet)
VGGNet由牛津大学的视觉几何组(Visual Geometry Group)提出,是ILSVRC-2014中定位任务第一名和分类任务第二名.本文的主要贡献点就是使用小的卷积核(3x3)来增加网络的 ...
随机推荐
- Proteus中包含的传感器类型(Transducers)
1. 传感器列表 2. 部分传感器的测量电路 (1)光照传感器,搭采样电阻,测电压输出. (2)距离传感器,带采样电阻,测电压输出. (3)粉尘传感器,测PWM脉宽 其余传感器多为总线类型的传感器,各 ...
- Yolo:实时目标检测实战(上)
Yolo:实时目标检测实战(上) YOLO:Real-Time Object Detection 你只看一次(YOLO)是一个最先进的实时物体检测系统.在帕斯卡泰坦X上,它以每秒30帧的速度处理图像, ...
- CVPR2020:点云分类的自动放大框架PointAugment
CVPR2020:点云分类的自动放大框架PointAugment PointAugment: An Auto-Augmentation Framework for Point Cloud Classi ...
- python_request 使用jsonpath取值结果,进行接口关联
一.jsonpath的安装 pip install jsonpath 二.使用举例 import jsonpath d1={"token":"hjshdsjhdsj ...
- 孟老板 ListAdapter封装, 告别Adapter代码 (上)
BaseAdapter封装(一) 简单封装 BaseAdapter封装(二) Header,footer BaseAdapter封装(三) 空数据占位图 BaseAdapter封装(四) PageHe ...
- WordPress安装篇(2):用宝塔面板在Windows上安装WordPress
上一篇文章介绍了如何使用PHPStudy工具在Windows Server环境安装WordPress,接下来介绍一款更加强大的部署WordPress的集成工具--宝塔面板.宝塔面板不仅提供免费版本,还 ...
- Redis五种基础与三种高级数据结构解析
记得点赞+关注呦. 前言 在 Redis 最重要最基础就属 它丰富的数据结构了,Redis 之所以能脱颖而出很大原因是他数据结构丰富,可以支持多种场景.并且 Redis 的数据结构实现以及应用场景在面 ...
- 自动按需引入组件用不了(Vant)
按照官网的自动按需引入之后,这样写是报错的,直接在vue页面中这样引用也是报错的. 正确的使用方法是这样的
- Docker笔记--ubuntu安装docker
Docker笔记--ubuntu安装docker 1.更换国内软件源,推荐中国科技大学的源,稳定速度快(可选) sudo cp /etc/apt/sources.list /etc/apt/sourc ...
- [源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark
[源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark ...