SIFT,SuperPoint在图像特征提取上的对比实验
SIFT,SuperPoint都具有提取图片特征点,并且输出特征描述子的特性,本篇文章从特征点的提取数量,特征点的正确匹配数量来探索一下二者的优劣。
视角变化较大的情况下
| 原图1 | 原图2 | SuperPoint特征点数 | SIFT提取到的特征点数 |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| SuperPoint特征点匹配情况 | SIFT特征点匹配情况 |
|---|---|
 |
 |
 |
 |
 |
 |
- SuperPoint提取到的特征点数量要少一些,可以理解,我想原因大概是SuperPoint训练使用的是合成数据集,含有很多形状,并且只标出了线段的一些拐点,而sift对图像的像素值变化敏感。
 SuperPoint下MagicPoint训练集样例
SuperPoint下MagicPoint训练集样例
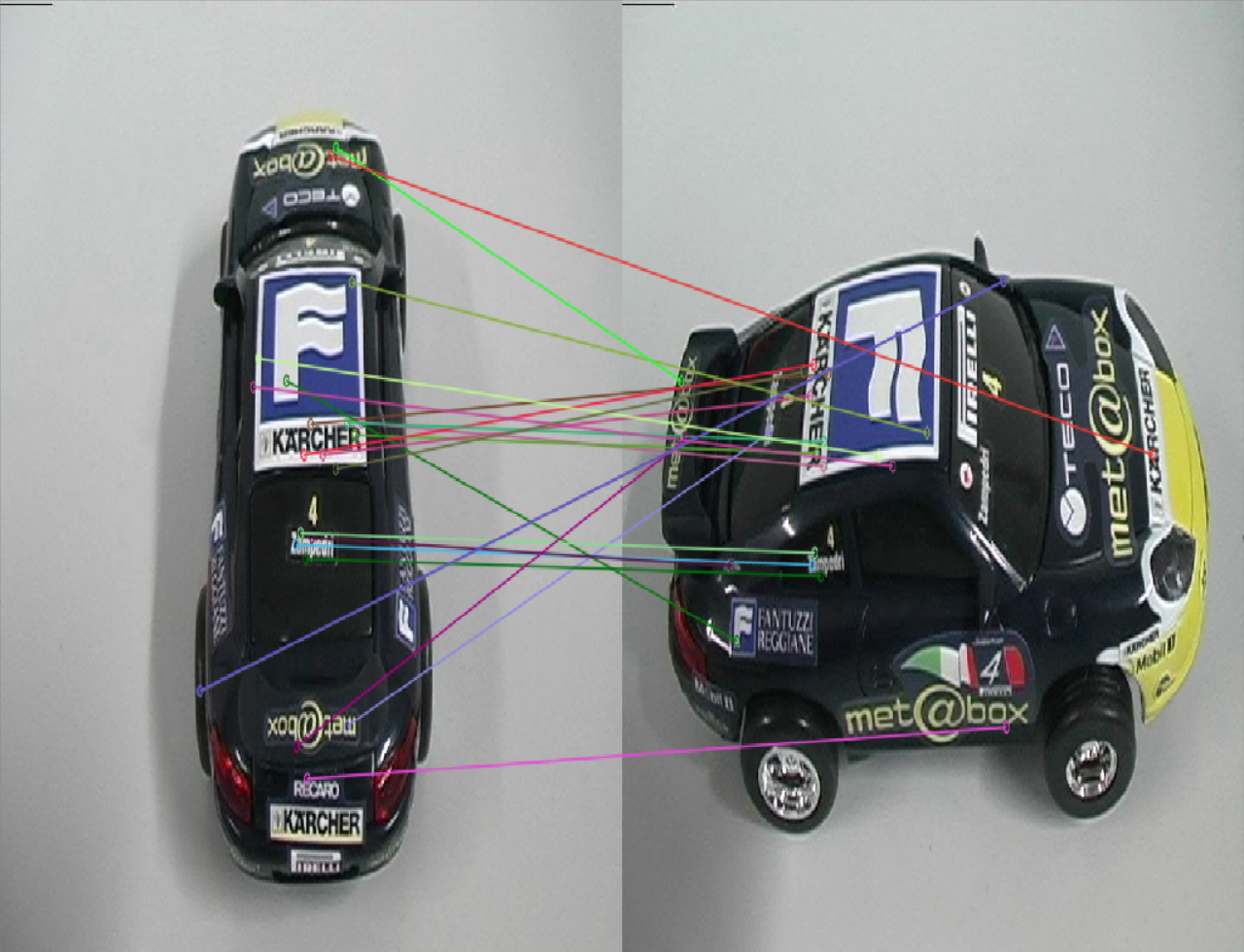
- 在特征点匹配上,感觉不出有什么明显的差异,但是很明显,SuperPoint的鲁棒性更高一些,sift匹配有很多的错点,比如
SIFT第三幅图中的牛奶盒子,由于物体没有上下的起伏,可以认为连线中的斜线都是错匹配。
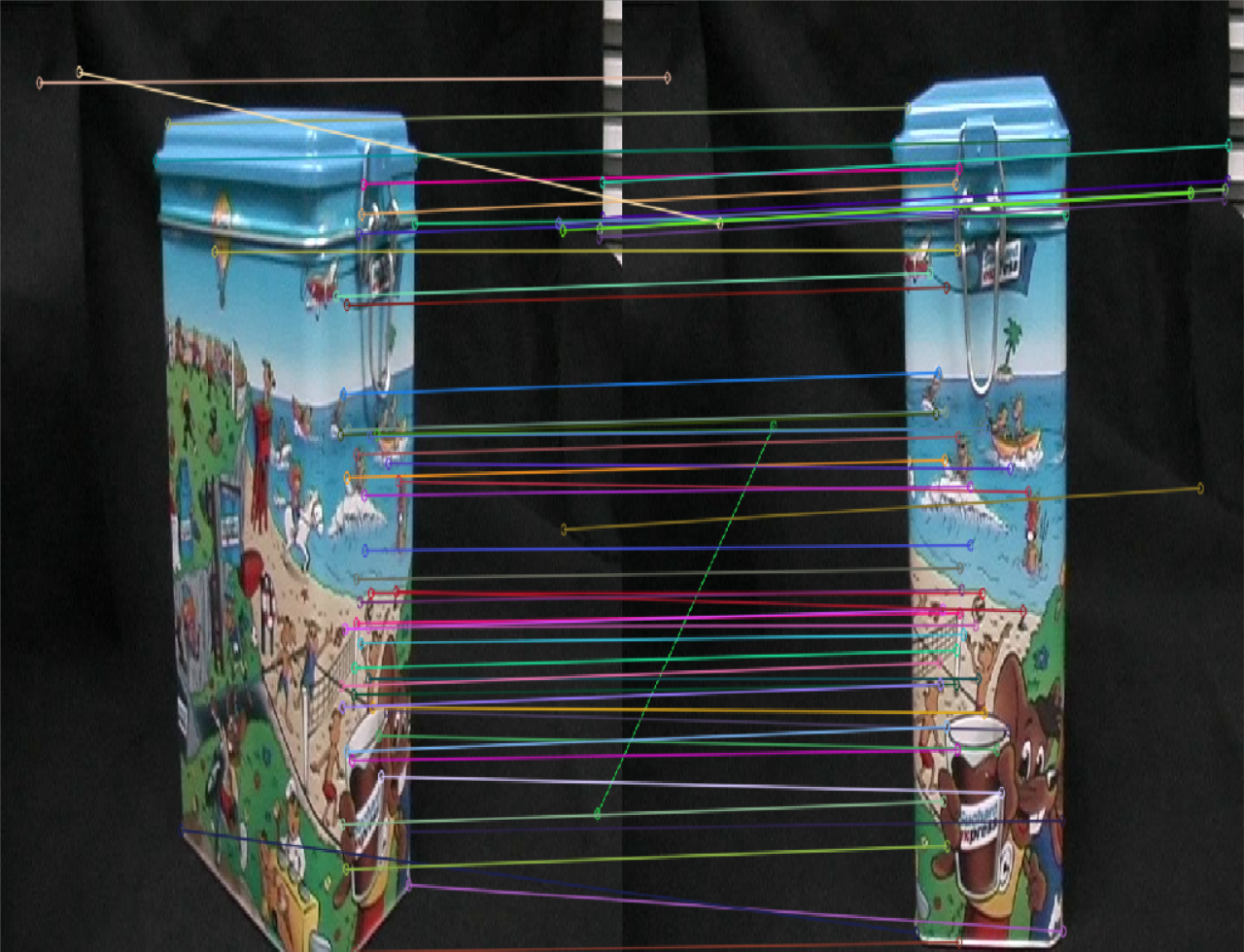
在形状较为复杂的情况下
正如上文所说,SuperPoint对形状较多的图片敏感。
| 原图1 | 原图2 | SuperPoint特征点数 | SIFT提取到的特征点数 |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
| SuperPoint特征点匹配情况 | SIFT特征点匹配情况 |
|---|---|
 |
 |
 |
 |
这里也可以看出,SuperPoint的匹配精度要优于SIFT,不会出现很多杂乱的线。
在3D建模object的表现
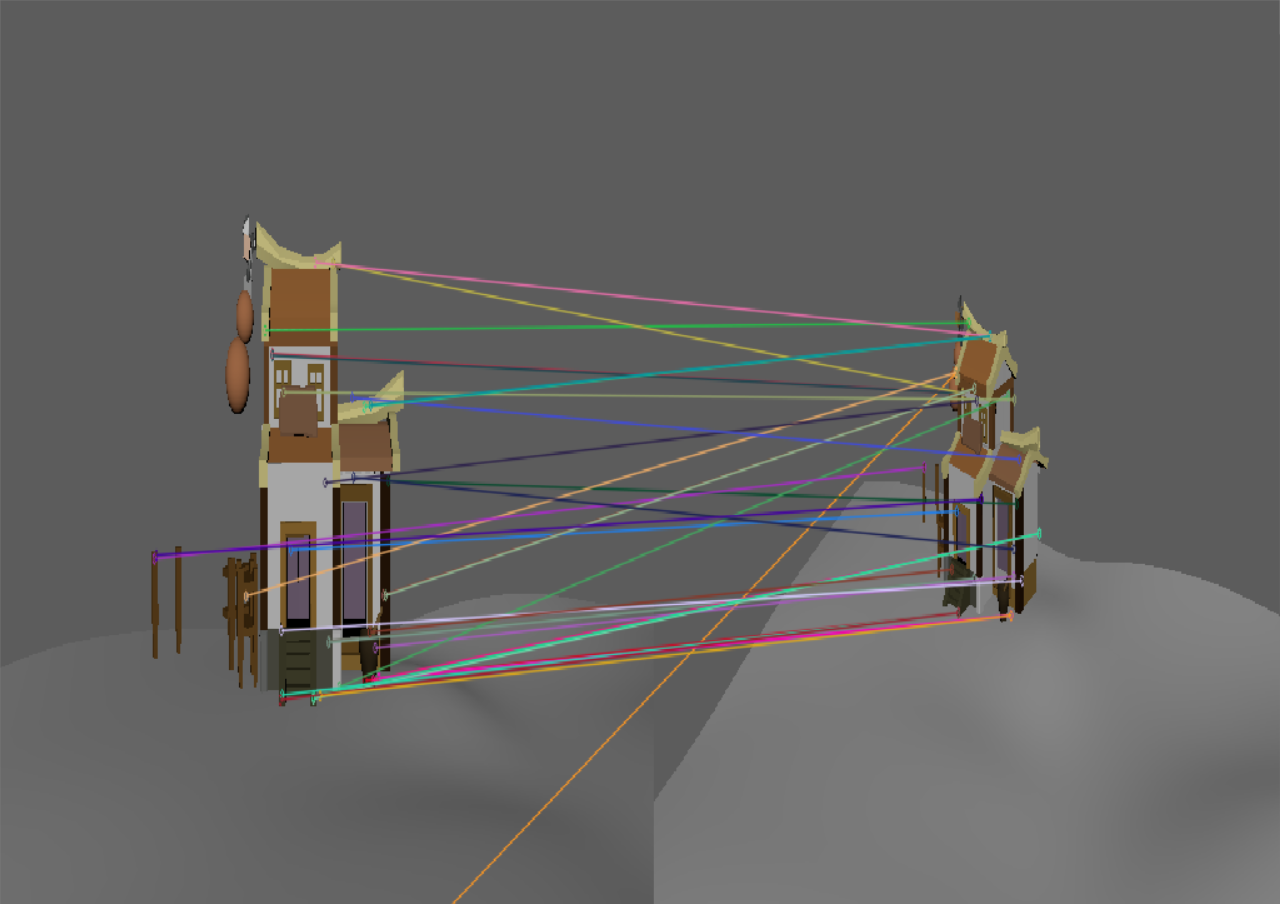
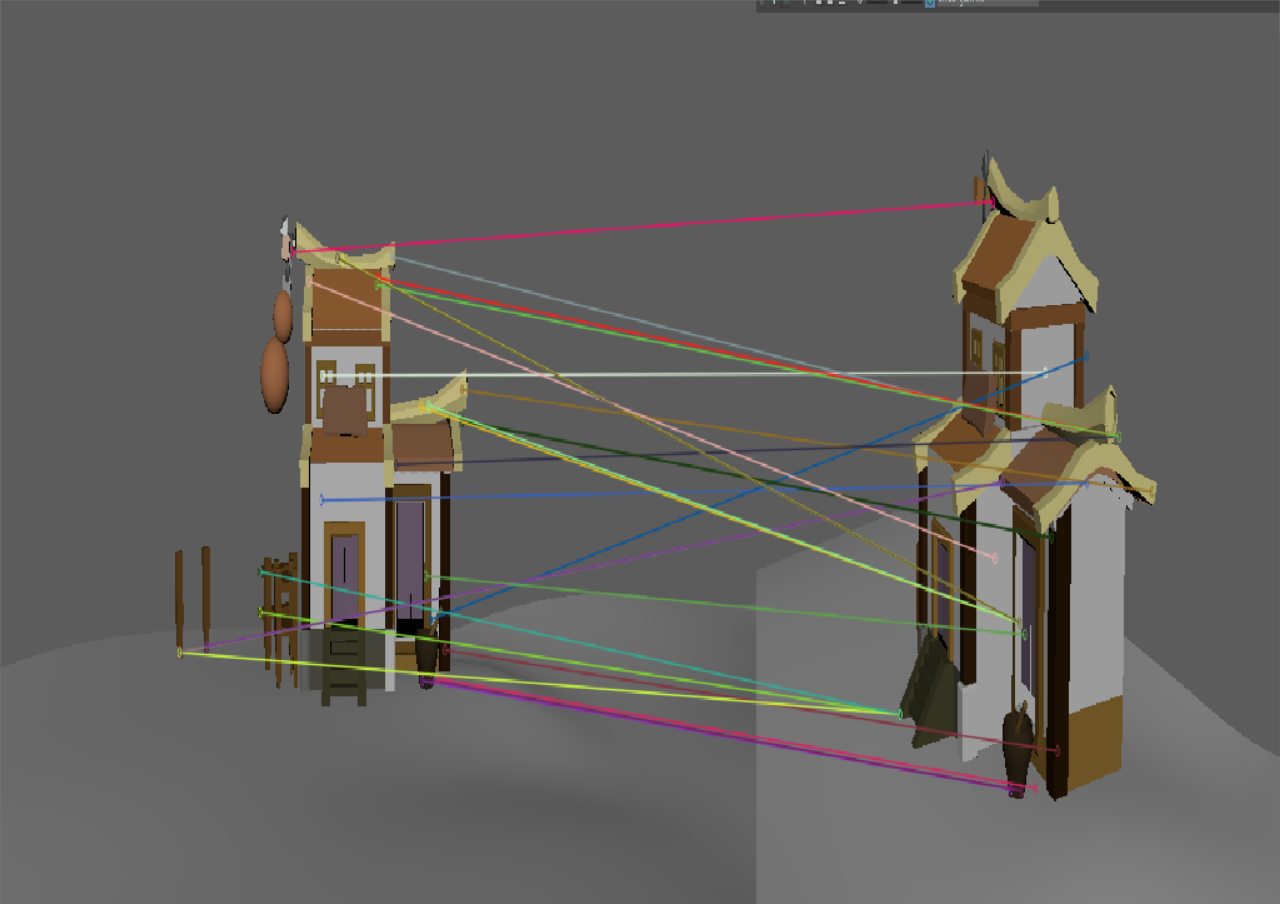
我尝试了之前自己的建模,并且观察了不同旋转角度对特征匹配的影响
| 主视角 | 小角度 | 视角缩放 | 旋转角度过大时 | |
|---|---|---|---|---|
 |
SuperPoint |  |
 |
 |
| SIFT |  |
 |
 |
|
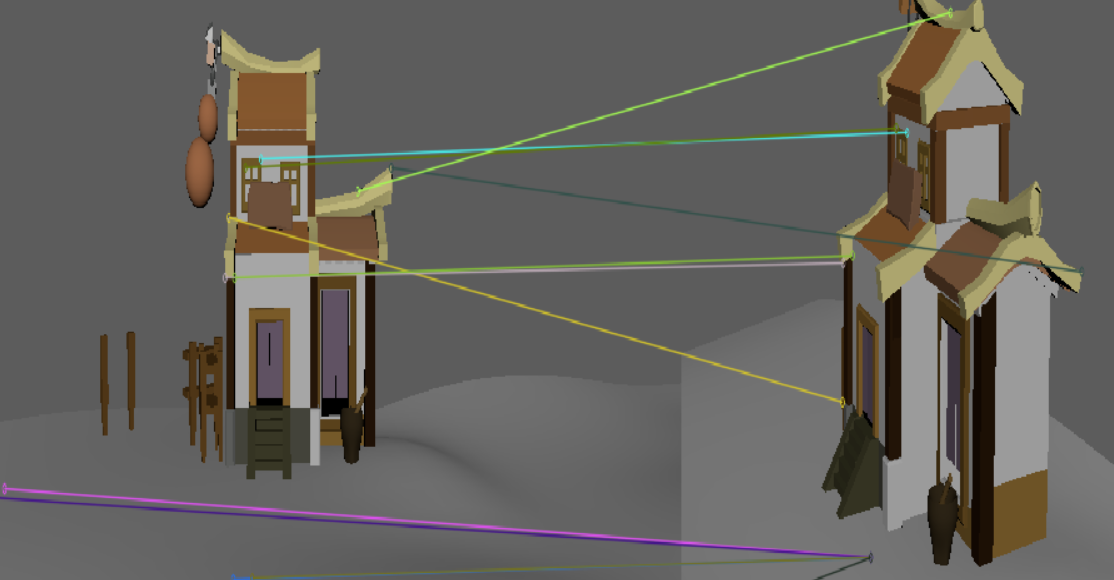
| 此时二者差距不大 | 这个虽然sift匹配的点更多,但是基本上都是错的。 | 这个虽然sift匹配的点更多,但是基本上都是错的。 |
SIFT特征点检测情况对比:
 |
 |
|---|
SuperPoint特征点检测情况对比:
 |
 |
|---|
同样值得注意的是,第一张图的窗子的点,SuperPoint并没有检测出来。
总结
- 在捕捉特征点的时候,SuperPoint对形状的特征点敏感,SIFT对像素的变化敏感
- 在进行特征点匹配的时候,SuperPoint的特征描述子鲁棒性更好一些
- 视角变化较大的情况下,二者的表现都差强人意
代码
SIFT.py:
from __future__ import print_function
import cv2 as cv
import numpy as np
import argparse
pic1 = "./1.ppm"
pic2 = "./6.ppm"
parser = argparse.ArgumentParser(description='Code for Feature Matching with FLANN tutorial.')
parser.add_argument('--input1', help='Path to input image 1.', default=pic1)
parser.add_argument('--input2', help='Path to input image 2.', default=pic2)
args = parser.parse_args()
img_object = cv.imread(pic1)
img_scene = cv.imread(pic2)
if img_object is None or img_scene is None:
print('Could not open or find the images!')
exit(0)
#-- Step 1: Detect the keypoints using SURF Detector, compute the descriptors
minHessian = 600
detector = cv.xfeatures2d_SURF.create(hessianThreshold=minHessian)
keypoints_obj, descriptors_obj = detector.detectAndCompute(img_object, None)
keypoints_scene, descriptors_scene = detector.detectAndCompute(img_scene, None)
#-- Step 2: Matching descriptor vectors with a FLANN based matcher
# Since SURF is a floating-point descriptor NORM_L2 is used
matcher = cv.DescriptorMatcher_create(cv.DescriptorMatcher_FLANNBASED)
knn_matches = matcher.knnMatch(descriptors_obj, descriptors_scene, 2)
#-- Filter matches using the Lowe's ratio test
ratio_thresh = 0.75
good_matches = []
for m,n in knn_matches:
if m.distance < ratio_thresh * n.distance:
good_matches.append(m)
print("The number of keypoints in image1 is", len(keypoints_obj))
print("The number of keypoints in image2 is", len(keypoints_scene))
#-- Draw matches
img_matches = np.empty((max(img_object.shape[0], img_scene.shape[0]), img_object.shape[1]+img_scene.shape[1], 3), dtype=np.uint8)
cv.drawMatches(img_object, keypoints_obj, img_scene, keypoints_scene, good_matches, img_matches, flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv.namedWindow("Good Matches of SIFT", 0)
cv.resizeWindow("Good Matches of SIFT", 1024, 1024)
cv.imshow('Good Matches of SIFT', img_matches)
cv.waitKey()
使用sift.py时,只需要修改第6,7行的图片路径即可。
SuperPoint
import numpy as np
import os
import cv2
import torch
# Jet colormap for visualization.
myjet = np.array([[0., 0., 0.5],
[0., 0., 0.99910873],
[0., 0.37843137, 1.],
[0., 0.83333333, 1.],
[0.30044276, 1., 0.66729918],
[0.66729918, 1., 0.30044276],
[1., 0.90123457, 0.],
[1., 0.48002905, 0.],
[0.99910873, 0.07334786, 0.],
[0.5, 0., 0.]])
class SuperPointNet(torch.nn.Module):
""" Pytorch definition of SuperPoint Network. """
def __init__(self):
super(SuperPointNet, self).__init__()
self.relu = torch.nn.ReLU(inplace=True)
self.pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)
c1, c2, c3, c4, c5, d1 = 64, 64, 128, 128, 256, 256
# Shared Encoder.
self.conv1a = torch.nn.Conv2d(1, c1, kernel_size=3, stride=1, padding=1)
self.conv1b = torch.nn.Conv2d(c1, c1, kernel_size=3, stride=1, padding=1)
self.conv2a = torch.nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1)
self.conv2b = torch.nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1)
self.conv3a = torch.nn.Conv2d(c2, c3, kernel_size=3, stride=1, padding=1)
self.conv3b = torch.nn.Conv2d(c3, c3, kernel_size=3, stride=1, padding=1)
self.conv4a = torch.nn.Conv2d(c3, c4, kernel_size=3, stride=1, padding=1)
self.conv4b = torch.nn.Conv2d(c4, c4, kernel_size=3, stride=1, padding=1)
# Detector Head.
self.convPa = torch.nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
self.convPb = torch.nn.Conv2d(c5, 65, kernel_size=1, stride=1, padding=0)
# Descriptor Head.
self.convDa = torch.nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
self.convDb = torch.nn.Conv2d(c5, d1, kernel_size=1, stride=1, padding=0)
def forward(self, x):
""" Forward pass that jointly computes unprocessed point and descriptor
tensors.
Input
x: Image pytorch tensor shaped N x 1 x H x W.
Output
semi: Output point pytorch tensor shaped N x 65 x H/8 x W/8.
desc: Output descriptor pytorch tensor shaped N x 256 x H/8 x W/8.
"""
# Shared Encoder.
x = self.relu(self.conv1a(x))
x = self.relu(self.conv1b(x))
x = self.pool(x)
x = self.relu(self.conv2a(x))
x = self.relu(self.conv2b(x))
x = self.pool(x)
x = self.relu(self.conv3a(x))
x = self.relu(self.conv3b(x))
x = self.pool(x)
x = self.relu(self.conv4a(x))
x = self.relu(self.conv4b(x))
# Detector Head.
cPa = self.relu(self.convPa(x))
semi = self.convPb(cPa)
# Descriptor Head.
cDa = self.relu(self.convDa(x))
desc = self.convDb(cDa)
dn = torch.norm(desc, p=2, dim=1) # Compute the norm.
desc = desc.div(torch.unsqueeze(dn, 1)) # Divide by norm to normalize.
return semi, desc
class SuperPointFrontend(object):
""" Wrapper around pytorch net to help with pre and post image processing. """
def __init__(self, weights_path, nms_dist, conf_thresh, nn_thresh,
cuda=False):
self.name = 'SuperPoint'
self.cuda = cuda
self.nms_dist = nms_dist
self.conf_thresh = conf_thresh
self.nn_thresh = nn_thresh # L2 descriptor distance for good match.
self.cell = 8 # Size of each output cell. Keep this fixed.
self.border_remove = 4 # Remove points this close to the border.
# Load the network in inference mode.
self.net = SuperPointNet()
if cuda:
# Train on GPU, deploy on GPU.
self.net.load_state_dict(torch.load(weights_path))
self.net = self.net.cuda()
else:
# Train on GPU, deploy on CPU.
self.net.load_state_dict(torch.load(weights_path,
map_location=lambda storage, loc: storage))
self.net.eval()
def nms_fast(self, in_corners, H, W, dist_thresh):
"""
Run a faster approximate Non-Max-Suppression on numpy corners shaped:
3xN [x_i,y_i,conf_i]^T
Algo summary: Create a grid sized HxW. Assign each corner location a 1, rest
are zeros. Iterate through all the 1's and convert them either to -1 or 0.
Suppress points by setting nearby values to 0.
Grid Value Legend:
-1 : Kept.
0 : Empty or suppressed.
1 : To be processed (converted to either kept or supressed).
NOTE: The NMS first rounds points to integers, so NMS distance might not
be exactly dist_thresh. It also assumes points are within image boundaries.
Inputs
in_corners - 3xN numpy array with corners [x_i, y_i, confidence_i]^T.
H - Image height.
W - Image width.
dist_thresh - Distance to suppress, measured as an infinty norm distance.
Returns
nmsed_corners - 3xN numpy matrix with surviving corners.
nmsed_inds - N length numpy vector with surviving corner indices.
"""
grid = np.zeros((H, W)).astype(int) # Track NMS data.
inds = np.zeros((H, W)).astype(int) # Store indices of points.
# Sort by confidence and round to nearest int.
inds1 = np.argsort(-in_corners[2, :])
corners = in_corners[:, inds1]
rcorners = corners[:2, :].round().astype(int) # Rounded corners.
# Check for edge case of 0 or 1 corners.
if rcorners.shape[1] == 0:
return np.zeros((3, 0)).astype(int), np.zeros(0).astype(int)
if rcorners.shape[1] == 1:
out = np.vstack((rcorners, in_corners[2])).reshape(3, 1)
return out, np.zeros((1)).astype(int)
# Initialize the grid.
for i, rc in enumerate(rcorners.T):
grid[rcorners[1, i], rcorners[0, i]] = 1
inds[rcorners[1, i], rcorners[0, i]] = i
# Pad the border of the grid, so that we can NMS points near the border.
pad = dist_thresh
grid = np.pad(grid, ((pad, pad), (pad, pad)), mode='constant')
# Iterate through points, highest to lowest conf, suppress neighborhood.
count = 0
for i, rc in enumerate(rcorners.T):
# Account for top and left padding.
pt = (rc[0] + pad, rc[1] + pad)
if grid[pt[1], pt[0]] == 1: # If not yet suppressed.
grid[pt[1] - pad:pt[1] + pad + 1, pt[0] - pad:pt[0] + pad + 1] = 0
grid[pt[1], pt[0]] = -1
count += 1
# Get all surviving -1's and return sorted array of remaining corners.
keepy, keepx = np.where(grid == -1)
keepy, keepx = keepy - pad, keepx - pad
inds_keep = inds[keepy, keepx]
out = corners[:, inds_keep]
values = out[-1, :]
inds2 = np.argsort(-values)
out = out[:, inds2]
out_inds = inds1[inds_keep[inds2]]
return out, out_inds
def run(self, img):
""" Process a numpy image to extract points and descriptors.
Input
img - HxW numpy float32 input image in range [0,1].
Output
corners - 3xN numpy array with corners [x_i, y_i, confidence_i]^T.
desc - 256xN numpy array of corresponding unit normalized descriptors.
heatmap - HxW numpy heatmap in range [0,1] of point confidences.
"""
assert img.ndim == 2, 'Image must be grayscale.'
assert img.dtype == np.float32, 'Image must be float32.'
H, W = img.shape[0], img.shape[1]
inp = img.copy()
inp = (inp.reshape(1, H, W))
inp = torch.from_numpy(inp)
inp = torch.autograd.Variable(inp).view(1, 1, H, W)
if self.cuda:
inp = inp.cuda()
# Forward pass of network.
outs = self.net.forward(inp)
semi, coarse_desc = outs[0], outs[1]
# Convert pytorch -> numpy.
semi = semi.data.cpu().numpy().squeeze()
# --- Process points.
# C = np.max(semi)
# dense = np.exp(semi - C) # Softmax.
# dense = dense / (np.sum(dense)) # Should sum to 1.
dense = np.exp(semi) # Softmax.
dense = dense / (np.sum(dense, axis=0) + .00001) # Should sum to 1.
# Remove dustbin.
nodust = dense[:-1, :, :]
# Reshape to get full resolution heatmap.
Hc = int(H / self.cell)
Wc = int(W / self.cell)
nodust = nodust.transpose(1, 2, 0)
heatmap = np.reshape(nodust, [Hc, Wc, self.cell, self.cell])
heatmap = np.transpose(heatmap, [0, 2, 1, 3])
heatmap = np.reshape(heatmap, [Hc * self.cell, Wc * self.cell])
xs, ys = np.where(heatmap >= self.conf_thresh) # Confidence threshold.
if len(xs) == 0:
return np.zeros((3, 0)), None, None
pts = np.zeros((3, len(xs))) # Populate point data sized 3xN.
pts[0, :] = ys
pts[1, :] = xs
pts[2, :] = heatmap[xs, ys]
pts, _ = self.nms_fast(pts, H, W, dist_thresh=self.nms_dist) # Apply NMS.
inds = np.argsort(pts[2, :])
pts = pts[:, inds[::-1]] # Sort by confidence.
# Remove points along border.
bord = self.border_remove
toremoveW = np.logical_or(pts[0, :] < bord, pts[0, :] >= (W - bord))
toremoveH = np.logical_or(pts[1, :] < bord, pts[1, :] >= (H - bord))
toremove = np.logical_or(toremoveW, toremoveH)
pts = pts[:, ~toremove]
# --- Process descriptor.
D = coarse_desc.shape[1]
if pts.shape[1] == 0:
desc = np.zeros((D, 0))
else:
# Interpolate into descriptor map using 2D point locations.
samp_pts = torch.from_numpy(pts[:2, :].copy())
samp_pts[0, :] = (samp_pts[0, :] / (float(W) / 2.)) - 1.
samp_pts[1, :] = (samp_pts[1, :] / (float(H) / 2.)) - 1.
samp_pts = samp_pts.transpose(0, 1).contiguous()
samp_pts = samp_pts.view(1, 1, -1, 2)
samp_pts = samp_pts.float()
if self.cuda:
samp_pts = samp_pts.cuda()
desc = torch.nn.functional.grid_sample(coarse_desc, samp_pts)
desc = desc.data.cpu().numpy().reshape(D, -1)
desc /= np.linalg.norm(desc, axis=0)[np.newaxis, :]
return pts, desc, heatmap
if __name__ == '__main__':
print('==> Loading pre-trained network.')
# This class runs the SuperPoint network and processes its outputs.
fe = SuperPointFrontend(weights_path="superpoint_v1.pth",
nms_dist=4,
conf_thresh=0.015,
nn_thresh=0.7,
cuda=True)
print('==> Successfully loaded pre-trained network.')
pic1 = "./1.ppm"
pic2 = "./6.ppm"
image1_origin = cv2.imread(pic1)
image2_origin = cv2.imread(pic2)
image1 = cv2.imread(pic1, cv2.IMREAD_GRAYSCALE).astype(np.float32)
image2 = cv2.imread(pic2, cv2.IMREAD_GRAYSCALE).astype(np.float32)
image1 = image1 / 255.
image2 = image2 / 255.
if image1 is None or image2 is None:
print('Could not open or find the images!')
exit(0)
# -- Step 1: Detect the keypoints using SURF Detector, compute the descriptors
keypoints_obj, descriptors_obj, h1 = fe.run(image1)
keypoints_scene, descriptors_scene, h2 = fe.run(image2)
## to transfer array ==> KeyPoints
keypoints_obj = [cv2.KeyPoint(keypoints_obj[0][i], keypoints_obj[1][i], 1)
for i in range(keypoints_obj.shape[1])]
keypoints_scene = [cv2.KeyPoint(keypoints_scene[0][i], keypoints_scene[1][i], 1)
for i in range(keypoints_scene.shape[1])]
print("The number of keypoints in image1 is", len(keypoints_obj))
print("The number of keypoints in image2 is", len(keypoints_scene))
# -- Step 2: Matching descriptor vectors with a FLANN based matcher
# Since SURF is a floating-point descriptor NORM_L2 is used
matcher = cv2.DescriptorMatcher_create(cv2.DescriptorMatcher_FLANNBASED)
knn_matches = matcher.knnMatch(descriptors_obj.T, descriptors_scene.T, 2)
# -- Filter matches using the Lowe's ratio test
ratio_thresh = 0.75
good_matches = []
for m, n in knn_matches:
if m.distance < ratio_thresh * n.distance:
good_matches.append(m)
# -- Draw matches
img_matches = np.empty((max(image1_origin.shape[0], image2_origin.shape[0]), image1_origin.shape[1] + image2_origin.shape[1], 3),
dtype=np.uint8)
cv2.drawMatches(image1_origin, keypoints_obj, image2_origin, keypoints_scene, good_matches, img_matches,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv2.namedWindow("Good Matches of SuperPoint", 0)
cv2.resizeWindow("Good Matches of SuperPoint", 1024, 1024)
cv2.imshow('Good Matches of SuperPoint', img_matches)
cv2.waitKey()
superpoint.py是基于官方给出的代码修改得到,使用步骤如下:
- 去官网下载模型的预训练文件,https://github.com/magicleap/SuperPointPretrainedNetwork
将预训练文件与文中给出的superpoint代码放在统一目录下
修改
254,255行的图片路径运行即可
SIFT,SuperPoint在图像特征提取上的对比实验的更多相关文章
- [OpenCV-Python] OpenCV 中图像特征提取与描述 部分 V (二)
部分 V图像特征提取与描述 OpenCV-Python 中文教程(搬运)目录 34 角点检测的 FAST 算法 目标 • 理解 FAST 算法的基础 • 使用 OpenCV 中的 FAST 算法相关函 ...
- [OpenCV-Python] OpenCV 中图像特征提取与描述 部分 V (一)
部分 V图像特征提取与描述 OpenCV-Python 中文教程(搬运)目录 29 理解图像特征 目标本节我会试着帮你理解什么是图像特征,为什么图像特征很重要,为什么角点很重要等.29.1 解释 我相 ...
- paper 1:图像特征提取
特征提取是计算机视觉和图像处理中的一个概念.它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征.特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点.连续的曲线或者连 ...
- 目标检测的图像特征提取之(一)HOG特征(转载)
目标检测的图像特征提取之(一)HOG特征 zouxy09@qq.com http://blog.csdn.net/zouxy09 1.HOG特征: 方向梯度直方图(Histogram of Orien ...
- 肺结节CT影像特征提取(二)——肺结节CT图像特征提取算法描述
摘自本人毕业论文<肺结节CT影像特征提取算法研究> 医学图像特征提取可以认为是基于图像内容提取必要特征,医学图像中需要什么特征基于研究需要,提取合适的特征.相对来说,医学图像特征提取要求更 ...
- 卷积和池化的区别、图像的上采样(upsampling)与下采样(subsampled)
1.卷积 当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去. ...
- 【数字图像处理】目标检测的图像特征提取之HOG特征
1.HOG特征 方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子.它通过计算和统计图像局部区域的梯 ...
- 【转】图像的上采样(upsampling)与下采样(subsampled)
转自:https://blog.csdn.net/stf1065716904/article/details/78450997 参考: http://blog.csdn.net/majinlei121 ...
- 图像的上采样(upsampling)与下采样(subsampled)
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:1.使得图像符合显示区域的大小:2.生成对应图像的缩略图. 放大图像(或称为上采样(upsampli ...
随机推荐
- E. Congruence Equation
E. Congruence Equation 思路: 中国剩余定理 \(a^n(modp) = a^{nmod(p-1)}(modp)\),那么枚举在\([0,n-2]\)枚举指数 求\(a^i\)关 ...
- 【LeetCode】423. Reconstruct Original Digits from English 解题报告(Python)
[LeetCode]423. Reconstruct Original Digits from English 解题报告(Python) 标签: LeetCode 题目地址:https://leetc ...
- idea使用教程-idea简介
集成开发环境(IDE,Integrated Development Environment )是用于提供程序开发环境的应用程序,一般包括代码编辑器.编译器.调试器和图形用户界面等工具.集成了代码编写功 ...
- Go package(3):io包介绍和使用
IO 操作的基本分类 在计算机中,处理文件和网络通讯等,都需要进行 IO 操作,IO 即是 input/ouput,计算机的输入输出操作. Go语言中的 IO 操作封装在如下几个包中: io 为 IO ...
- 搞一下vue生态,从vuex开始
Vuex vuex 是专门帮助vue管理的一个js库,利用了vue.js中细粒度数据响应机制来进行高效的状态更新. vuex核心就是store,store就是个仓库,这里采用了单一的store状态树, ...
- 一文搞懂Google Navigation Component
一文搞懂Google Navigation Component 应用中的页面跳转是一个常规任务, Google官方提供的解决方案是Android Jetpack的Navigation componen ...
- pod存在,但是deployment和statefulset不存在
pod存在,但是deployment和statefulset不存在 这样的话,可以看一下是不是ReplicaSet, kubectl get ReplicaSet -n iot
- SpringCloud发现服务代码(EurekaClient,DiscoveryClient)
1.说明 本文介绍SpringCloud发现服务代码的开发, 通过使用EurekaClient,DiscoveryClient来发现注册中心的服务等, 从而可以自定义客户端对注册中心的高级用法. 2. ...
- Eclipse远程调试Java代码的三种方法
Eclipse远程调试Java代码的三种方法, 第1种方法是用来调试已经启动的Java程序,Eclipse可以随时连接到远程Java程序进行调试, 第2种方法可以调试Java程序启动过程,但是Ecli ...
- unittest_expectedFailure预期用例失败(5)
在断言用例执行结果时,会出现预期结果与实际结果不一致的情况,此时我们明确知道用例执行结果为FAIL,不想看到打印错误信息怎么办? 使用装饰器@unittest.expectedFailure标记该用例 ...