【C/C++】two pointers/归并排序/原理/理解/实现/算法笔记4.6
1.two pointers
思路:对序列进行扫描的时候,根据序列本身的特性用两个下标i和j对序列进行扫描,从而降低算法复杂度。
·例1 在递增序列中找a + b = M
while (i<j)
{
if(a[i] + a[j] == M)
{
i++;
j++;
}
else if (a[i] + a[j] < M)
{
i++;
}
else j--;
}
·例2 序列合并问题
思路:将两个从小到大排序的序列排序出一个新的从小到大排序的序列
用两个标记i和j比较A和B中哪个小就填入哪个,剩下的多的填完。
int merge(int A[], int B[], int C[], int n, int m) //n:A长度 m:B长度 从小到大排序
{
int i = 0, j = 0;
int index = 0;
while(i < n && j < m)
{
if (A[i] <= B[j])
{
C[index++] = A[i++];
}
else
{
C[index++] = B[j++];
}
}
while (i < n) C[index++] = A[i++];
while (j < m) C[index++] = B[j++];
return index;
}
2. 归并排序
我找到一个动图特别好理解,尤其是最后分成每个是一个。
思路:2路归并排序,就是把待排序数组每次两两分组,分到每组只剩一个以后开始合并。
合并的时候遵从上面例2的方式。
因为分组是按照数组的顺序分组的,所以分组对数组的顺序其实是没有改变的。每次使用mergeSort递归只是为了获得一个更新以后的坐标,然后带入上面的序列合并的坐标位置。
真正改变的是在合并的时候
可以说这个排序是由合并本身实现的
递归边界条件是left < right,因为最后只剩一个的时候是left = right
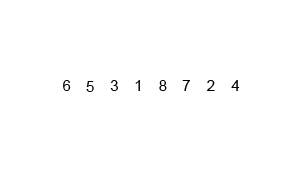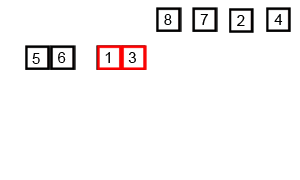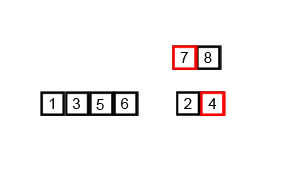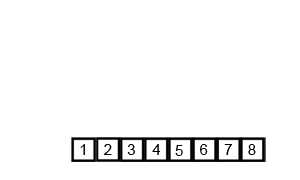
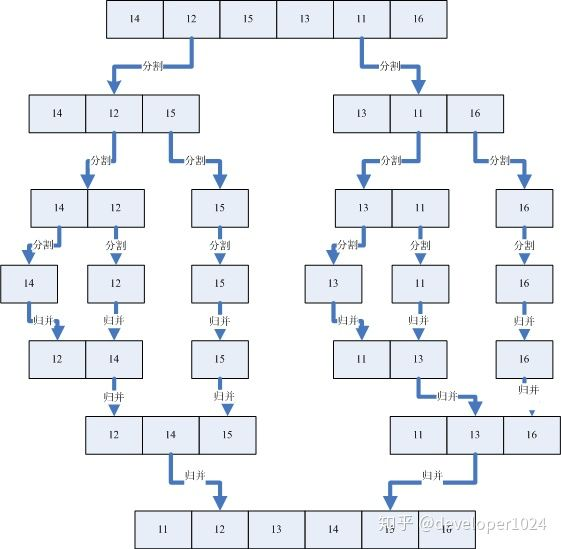
归并排序的实现:
1.递归方式
#include <iostream>
using namespace std;
const int maxn = 100;
//从小到大排序 合并函数
void merge(int A[], int L1, int R1, int L2, int R2)
{
int temp[maxn];
int index = 0; //记录temp的数
int i = L1;
int j = L2;
while (i <= R1 && j <= R2)
{
if (A[i] <= A[j])
{
temp[index++] = A[i++];
}
else
{
temp[index++] = A[j++];
}
}
while (i <= R1)
{
temp[index++] = A[i++];
}
while (j <= R2)
{
temp[index++] = A[j++];
}
for(i = 0; i < index; i++)
{
A[L1 + i] = temp[i];
}
}
//分裂
void mergeSort(int A[], int left, int right)
{
if (left < right)
{
int mid = (left + right)/2;
mergeSort(A, left, mid);
mergeSort(A, mid + 1, right);
merge(A, left, mid, mid+1, right); //注意这句一定要在if判断里面 这样才能退到边缘以后直接返回每一层的输出
}
}
int main()
{
int a[] = {6,5,3,1,8,7,2,4};
mergeSort(a, 0, 7);
int len = sizeof(a)/sizeof(a[0]);
for(int i = 0; i < len; i++)
{
printf("%d ", a[i]);
}
printf("\n");
system("pause");
}
这里我要加一些自己的理解。
测试序列:6 5 3 1 8 7 2 4
按照上述的原理,会被分成6 5;3 1;8 7;2 4;
当我们只剩下两个的时候,以6 5为例
他们分别是A[0]和A[1]
这个时候,left = 0, right = 1
计算出的mid = (left + right)/2 = 0
mid + 1 = 2
就是这个时候的left = 1 = mid, mid + 1 = 2 = right
把此时的数据带入下一步的mergeSort(A, left, mid)会因为left = right = 0而不满足mergesort中的left < right而导致无法进行下一步
这个时候就达到了递归转折退回的地方,回到了left = 0, right = 1的地方
带入merge函数,相当于执行merge(a, 0, 0, 1, 1)
其实就是排序了
以此类推
这是另外一种将mergesort和merge合并的写法
#include <stdio.h>
#include <stdlib.h>
// 归并排序(C-递归版)
void merge_sort_recursive(int arr[], int reg[], int start, int end) {
if (start >= end)
return;
int len = end - start, mid = (len >> 1) + start;
int start1 = start, end1 = mid;
int start2 = mid + 1, end2 = end;
merge_sort_recursive(arr, reg, start1, end1);
merge_sort_recursive(arr, reg, start2, end2);
int k = start;
while (start1 <= end1 && start2 <= end2)
reg[k++] = arr[start1] < arr[start2] ? arr[start1++] : arr[start2++];
while (start1 <= end1)
reg[k++] = arr[start1++];
while (start2 <= end2)
reg[k++] = arr[start2++];
for (k = start; k <= end; k++)
arr[k] = reg[k];
}
void merge_sort(int arr[], const int len) {
int reg[len];
merge_sort_recursive(arr, reg, 0, len - 1);
}
int main()
{
int a[] = {6,5,3,1,8,7,2,4};
int len = sizeof(a)/sizeof(a[0]);
merge_sort(a, len);
for (int i = 0; i < len; i++)
{
printf("%d ", a[i]);
}
system("pause");
}
2、非递归实现(迭代)
(注意:n = len,相同意思,指待排序的数组长度)
由二分的性质,直接对A[]进行排序(合并)
方法是:先取step = 2,然后对前step/2和后step/2进行合并排序。
如果组内元素 <= step/2,则不操作
当step/2 > n的时候结束排序
为什么不是step = n的时候结束呢?
因为如果n是奇数的话,step得多出一个(看图,每次最后一个因为不满足mid + 1 <= n而无法排序的最后一个数,在第一轮step = 2的时候就被排除在外了,多么可怜)
而要注意的是,多出一个step不能用step <= n+1来,因为step的变化是2倍变化的(step *= 2)
所以这里只能是step/2 <= n
我自己画了一个图来理解:

其实我们可以用step/2 < n就可以了:
因为如果长度为偶数的话,只需要满足 step <= n,举个栗子
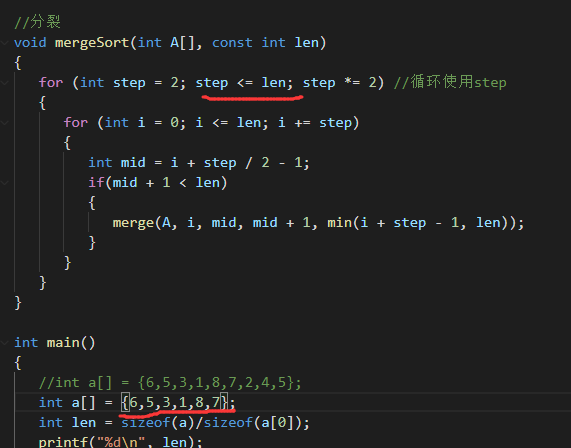
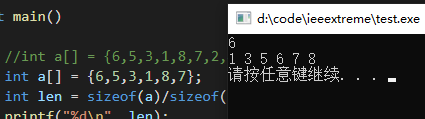
但是注意,不能是step < n,不然当数组长度刚好为step的倍数的时候最后会少一个,导致最后一个没法把两个合并。
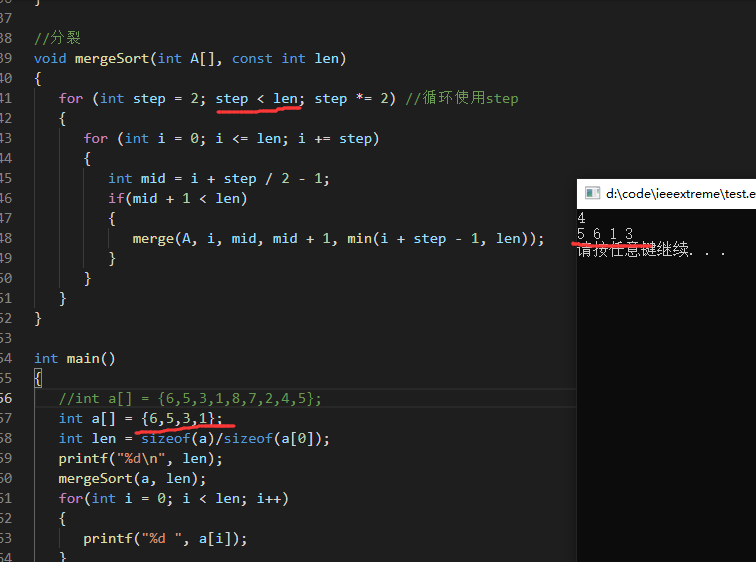
43和46行的等于好像也可以去掉,我觉得没有太大影响?
【C/C++】two pointers/归并排序/原理/理解/实现/算法笔记4.6的更多相关文章
- 归并排序的理解和实现(Java)
归并排序介绍 归并排序(Merge Sort)就是利用归并的思想实现的排序方法.它的原理是假设初始序列含有fn个记录,则可以看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到[n2\fr ...
- JUC回顾之-ConcurrentHashMap源码解读及原理理解
ConcurrentHashMap结构图如下: ConcurrentHashMap实现类图如下: segment的结构图如下: package concurrentMy.juc_collections ...
- POJ1523(割点所确定的连用分量数目,tarjan算法原理理解)
SPF Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 7406 Accepted: 3363 Description C ...
- java的classLoader原理理解和分析
java的classLoader原理理解和分析 学习了:http://blog.csdn.net/tangkund3218/article/details/50088249 ClassNotFound ...
- 深入理解KMP算法
前言:本人最近在看<大话数据结构>字符串模式匹配算法的内容,但是看得很迷糊,这本书中这块的内容感觉基本是严蔚敏<数据结构>的一个翻版,此书中给出的代码实现确实非常精炼,但是个人 ...
- KMP算法详解 --- 彻头彻尾理解KMP算法
前言 之前对kmp算法虽然了解它的原理,即求出P0···Pi的最大相同前后缀长度k. 但是问题在于如何求出这个最大前后缀长度呢? 我觉得网上很多帖子都说的不是很清楚,总感觉没有把那层纸戳破, 后来翻看 ...
- 更多细节的理解RSA算法
一.概述 RSA算法是1977年由Ron Rivest.Adi Shamir 和 Leonard Adleman三人组在论文A Method for Obtaining Digital Signatu ...
- 怎么理解RSA算法
原文地址:http://www.ittenyear.com/414/rsa/ 怎么理解RSA算法 能够把非对称加密算法里的公钥想象成一个带锁的箱子,把私钥想象成一把钥匙 能够把对称加密算法里的密钥想象 ...
- 支持向量机原理(四)SMO算法原理
支持向量机原理(一) 线性支持向量机 支持向量机原理(二) 线性支持向量机的软间隔最大化模型 支持向量机原理(三)线性不可分支持向量机与核函数 支持向量机原理(四)SMO算法原理 支持向量机原理(五) ...
随机推荐
- C#与dotNET项目想要另存为一个新项目sln文件丢了怎么办
如下图所示,我想要另存一个工程,把 V4.4整个的项目另存为V4.5,我可以把解决方案文件(.sln)改名字,但是我没法把文件夹改名字,改了打开sln就说找不到. 很简单的一个思路是反正sln是多余的 ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- SQL语句修改字段类型与第一次SQLServer试验解答
SQL语句修改字段类型 mysql中 alert table name modify column name type; 例子:修改user表中的name属性类型为varchar(50) alert ...
- [gym102832J]Abstract Painting
考虑每一个圆即对应于区间$[x_{i}-r_{i},x_{i}+r_{i}]$,可以看作对于每一个区间,要求所有右端点严格比其小的区间不严格包含左端点 用$f_{i}$表示仅考虑右端点不超过$i$的区 ...
- [bzoj1593]旅馆
用线段树维护区间中最大的一段连续的1,以左端点为左端点最大的一段连续的1,以右端点为右端点最大的一段连续的1,然后就可以支持区间修改和查询了 1 #include<bits/stdc++.h&g ...
- 深度揭秘Netty中的FastThreadLocal为什么比ThreadLocal效率更高?
阅读这篇文章之前,建议先阅读和这篇文章关联的内容. 1. 详细剖析分布式微服务架构下网络通信的底层实现原理(图解) 2. (年薪60W的技巧)工作了5年,你真的理解Netty以及为什么要用吗?(深度干 ...
- .Net Crank性能测试入门
Crank 是微软新出的一个性能测试框架,集成了多种基准测试工具,如bombardier.wrk等. Crank通过统一的配置,可以转换成不同基准测试工具命令进行测试.可参考Bombardier Jo ...
- springboot默认Thymeleaf模板引擎js的解决方案
<script th:inline="javascript"> var btnexam=[[${btnexam}]]; console.log(btnexam); va ...
- Date相关类
Date相关类 SimpleDateFormat类中format()和parse()方法 parse 字符串 --> 日期 format 日期 --> 字符串 Date类中getTime( ...
- 力扣 - 剑指 Offer 46. 把数字翻译成字符串
题目 剑指 Offer 46. 把数字翻译成字符串 思路1(递归,自顶向下) 这题和青蛙跳台阶很类似,青蛙跳台阶说的是青蛙每次可以跳一层或者两层,跳到第 n 层有多少种解法,而这题说的是讲数字翻译成字 ...