Spark记录(一):Spark全景概述
一、Spark是什么
Spark是一个开源的大数据处理引擎。
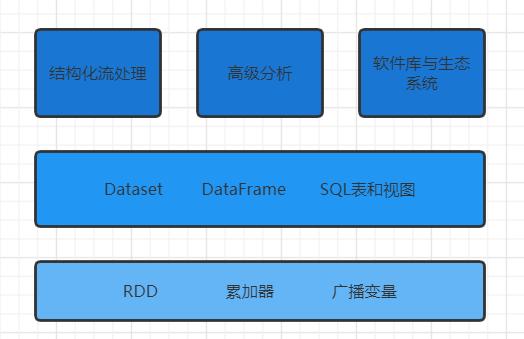
二、Spark的主要组件如下图所示:
三、Spark运行时架构
Spark共有三种运行模式:本地模式、集群模式、客户端模式。
生产环境基本都是用集群模式。集群模式需要用到集群管理器,三个核心的集群管理器为:Spark自带的独立集群管理器、Yarn、Mesos。
集群模式运行时,单个Spark任务的架构图为:
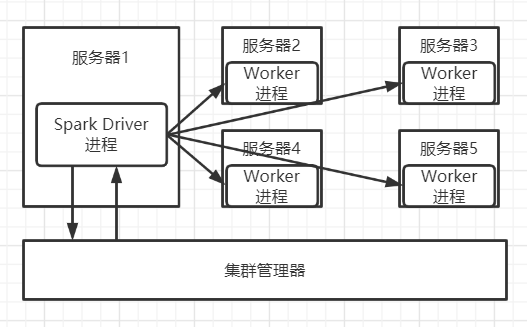
其中集群管理器负责分配/回收服务器资源和监控整个Spark任务是否完成。
四、IDEA环境准备
1、准备Scala的SDK
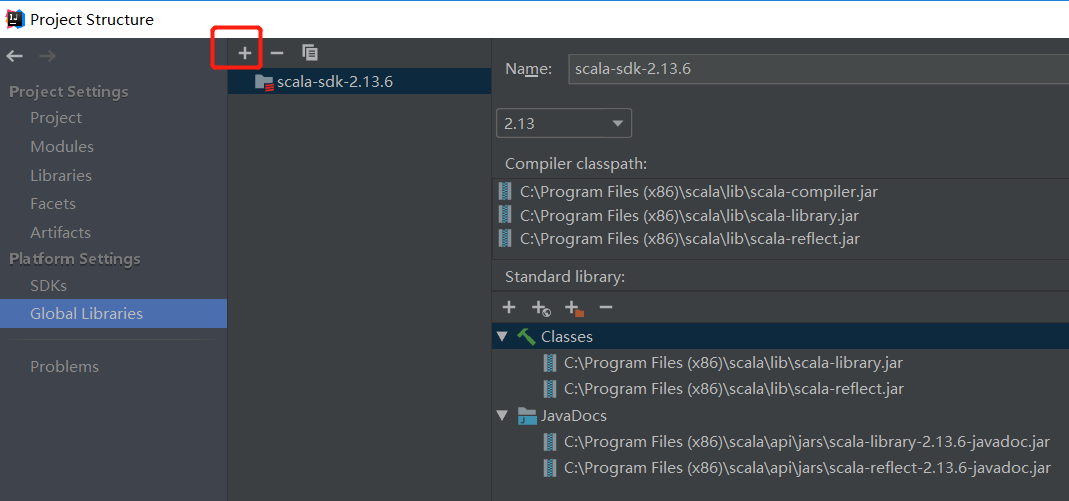
若用Scala开发的话,需做此步。下载Scala的msi文件本地安装之后,在IDEA中如下图所示的加号位处导入Scala的SDK目录,导入之后会如下图所示:
2、在Plugins中安装名叫Scala的插件
自行安装即可
3、配置项目支持Scala
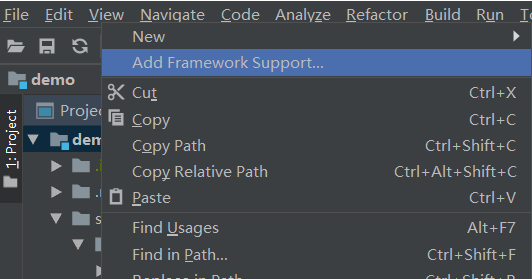
选中项目最高级目录后右键,选择【Add Framework Support】,然后在里面勾选Scala选项
如此之后,便可以在包里面右键new Scala类了:
4、导入maven依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
版本用的是:
<spark.version>3.2.0</spark.version>
<scala.version>2.13</scala.version>
5、编写个简单的脚本运行
def main(args: Array[String]): Unit = {
val ss = SparkSession.builder().appName("localhost").master("local[*]").getOrCreate()
val df1 = ss.range(2, 100, 2).toDF()
val df2 = ss.range(2, 100, 4).toDF()
val df11 = df1.repartition(5)
val df21 = df2.repartition(6)
val df12 = df11.selectExpr("id * 5 as id")
val df3 = df2.join(df12, "id")
val df4 = df3.selectExpr("sum(id)")
df4.collect().foreach(println(_))
df4.explain()
}
运行结果:

Intersting Number!
explain打印出来的逻辑计划,有时间再详细解读。
另附:
1、下载历史Hadoop版本的地址:
http://archive.apache.org/dist/hadoop/core/
2、下载winutils.exe、hadoop.dll文件的地址:
https://blog.csdn.net/ytp552200ytp/article/details/107223357
Spark记录(一):Spark全景概述的更多相关文章
- Spark记录-本地Spark读取Hive数据简单例子
注意:将mysql的驱动包拷贝到spark/lib下,将hive-site.xml拷贝到项目resources下,远程调试不要使用主机名 import org.apache.spark._ impor ...
- Spark记录-SparkSql官方文档中文翻译(部分转载)
1 概述(Overview) Spark SQL是Spark的一个组件,用于结构化数据的计算.Spark SQL提供了一个称为DataFrames的编程抽象,DataFrames可以充当分布式SQL查 ...
- Spark记录-SparkSQL相关学习
$spark-sql --help 查看帮助命令 $设置任务个数,在这里修改为20个 spark-sql>SET spark.sql.shuffle.partitions=20; $选择数据 ...
- Spark记录-实例和运行在Yarn
#运行实例 #./bin/run-example SparkPi 10 #./bin/spark-shell --master local[2] #./bin/pyspark --master l ...
- Spark记录-官网学习配置篇(一)
参考http://spark.apache.org/docs/latest/configuration.html Spark提供三个位置来配置系统: Spark属性控制大多数应用程序参数,可以使用Sp ...
- Spark记录-spark编程介绍
Spark核心编程 Spark 核心是整个项目的基础.它提供了分布式任务调度,调度和基本的 I/O 功能.Spark 使用一种称为RDD(弹性分布式数据集)一个专门的基础数据结构,是整个机器分区数据的 ...
- Spark记录-spark介绍
Apache Spark是一个集群计算设计的快速计算.它是建立在Hadoop MapReduce之上,它扩展了 MapReduce 模式,有效地使用更多类型的计算,其中包括交互式查询和流处理.这是一个 ...
- Spark记录-spark与storm比对与选型(转载)
大数据实时处理平台市场上产品众多,本文着重讨论spark与storm的比对,最后结合适用场景进行选型. 一.spark与storm的比较 比较点 Storm Spark Streaming 实时计算模 ...
- Spark记录-Spark on mesos配置
1.安装mesos #用centos6的源yum安装 # rpm -Uvh http://repos.mesosphere.io/el/6/noarch/RPMS/mesosphere-el-repo ...
随机推荐
- 网络协议之:WebSocket的消息格式
目录 简介 WebSocket的握手流程 webSocket的消息格式 Extensions和Subprotocols 总结 简介 我们知道WebSocket是建立在TCP协议基础上的一种网络协议,用 ...
- gin 源码阅读(1) - gin 与 net/http 的关系
gin 是目前 Go 里面使用最广泛的框架之一了,弄清楚 gin 框架的原理,有助于我们更好的使用 gin. 这个系列 gin 源码阅读会逐步讲明白 gin 的原理. gin 概览 想弄清楚 gin, ...
- 自学 Java开发(Java后台开发|Java后端开发)的书籍推荐
java编程思想java并发编程实战深入理解java虚拟机函数式编程思维tcp/ip详解鸟哥的linux私房菜spring mvc +mybatis开发从入门到精通spring技术内幕elastics ...
- centos7 设置dns
查看当前网络连接 nmcli connection show NAME UUID TYPE DEVICE eth0 5fb06bd0-0bb0-7ffb-45f1-d6edd65f3e03 802-3 ...
- [源码解析] PyTorch 流水线并行实现 (6)--并行计算
[源码解析] PyTorch 流水线并行实现 (6)--并行计算 目录 [源码解析] PyTorch 流水线并行实现 (6)--并行计算 0x00 摘要 0x01 总体架构 1.1 使用 1.2 前向 ...
- 小白自制Linux开发板 四. 通过SPI使用ESP8266做无线网卡
本文章基于 WhyCan Forum(哇酷开发者社区) https://whycan.com/t_4149.htmlhttps://whycan.com/t_5870.html整理而成. 为了尊重原作 ...
- flask 之上传本地图片
项目配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import os class Config(object): DEBUG = True SQLALCHEMY_DATABA ...
- Ysoserial Commons Collections7分析
Ysoserial Commons Collections7分析 写在前面 CommonsCollections Gadget Chains CommonsCollection Version JDK ...
- Coursera Deep Learning笔记 序列模型(三)Sequence models & Attention mechanism(序列模型和注意力机制)
参考 1. 基础模型(Basic Model) Sequence to sequence模型(Seq2Seq) 从机器翻译到语音识别方面都有着广泛的应用. 举例: 该机器翻译问题,可以使用" ...
- Java:ArrayList类小记
Java:ArrayList类小记 对 Java 中的 ArrayList类,做一个微不足道的小小小小记 概述 java.util.ArrayList 是大小可变的数组的实现,存储在内的数据称为元素. ...