MapReduce05 框架原理OutPutFormat数据输出
MapReduce 框架原理
1.InputFormat可以对Mapper的输入进行控制
2.Reducer阶段会主动拉取Mapper阶段处理完的数据
3.Shuffle可以对数据进行排序、分区、压缩、合并,核心部分。
4.OutPutFomat可以对Reducer的输出进行控制
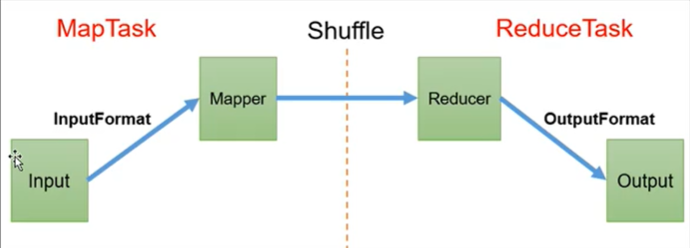
4.OutputFormat数据输出
OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有MapReduce输出都实现了OutputFormat接口
- OutputFormat
- FileOutputFormat
- TextOutputFormat 默认
- FileOutputFormat
自定义OutputFormat
应用场景
输出数据到MySQL/HBase等
自定义OutputFormat步骤
1.自定义一个类继承FileOutputFormat<k,v> 这里的kv是指输入的kv
2.重写getRecordWriter方法
3.创建返回类RecordWeiter,kv同1,改写输出数据的方法write()
自定义OutputFormat案例
需求
过滤输入的log日志,包含ranan的网站输出到D:\hadoop_data\output\ranan.log,不包含ranan的网站输出到D:\hadoop_data\output\other.log
输入数据:D:\hadoop_data\input\inputoutputformat\log.txt
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.ranan.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
需求分析
分区输出的文件名不能自己命名,所以这里采用自定义OutputFormat类
1.创建一个类LogRecordWriter继承RecordWriter
1.1 创建两个文件的输出流:rananOut、otherOut
1.2 如果包含ranan,输出到rananOut流,如果不包含ranan,输出到otherOut流
2.在job驱动中配置使用自定义类job.setOutFormatClass(LogRecordWriter.class)
案例实现
LogMapper类
输入的k是偏移量LongWritable,输入的v是一行Text。观察输出只需要一行网站,那么输出的k是一行类容,输出的v是NullWritable
为什么不k是空,因为k是会排序的,需要实现可排序
package ranan.mapreduce.outputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapper <LongWritable,Text,Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
LogReducer
只起到数据传递的作用
注意要防止两条一样的进来输出一条出去的情况
package ranan.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
for(NullWritable value:values){
context.write(key,NullWritable.get());
}
//直接写进来两条一样的只会输出一条出去
//context.write(key,NullWritable.get());
}
LogOutputFormat类
package ranan.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
//这里返回值需要RecordWriter类,创建这个类 传递job配置信息!
LogRecordWriter lrw = new LogRecordWriter(job);
return lrw;
}
}
LogRecordWriter类
作为RecordWriter方法的返回值,主要的实现写在这里
package ranan.mapreduce.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class LogRecordWriter extends RecordWriter<Text, NullWritable> {
private FSDataOutputStream rananOut;
private FSDataOutputStream otherOut;
//与自定义LogOutputFormat产生联系
public LogRecordWriter(TaskAttemptContext job) {
//创建两条输出流
try {
//get的报错直接处理,参数的配置信息使用job的配置信息
FileSystem fs = FileSystem.get(job.getConfiguration());
rananOut = fs.create(new Path("D:\\hadoop_data\\output\\ranan.log"));
otherOut = fs.create(new Path("D:\\hadoop_data\\output\\other.log"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
//具体写
//输入是每一行的内容,类型是Text
String log = key.toString();
if(log.contains("ranan")) {
rananOut.writeBytes(log);
}
else {
//writeBytes参数是string类型
otherOut.writeBytes(log);
}
}
//资源关闭
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
IOUtils.closeStream(rananOut);
IOUtils.closeStream(otherOut); //TOUtiles工具类
}
}
LogDriver类
虽然我们自定义OutputFormat继承了FileOutputFormat,自定义了输出路径。
而FileOutputFormat需要输出一个_SUCCESS文件,依旧需要设置一个输出路径输出_SUCCESS文件
package ranan.mapreduce.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 设置jar
job.setJarByClass(LogDriver.class);
//3 关联Mapper,Reducer
job.setMapperClass(LogMapper.class);
job.setReducerClass(LogReducer.class);
// 4 设置mapper 输出的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 5 设置最终数据输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置自定义的outputFormat
job.setOutputFormatClass(LogOutputFormat.class);
// 6 设置数据的输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\hadoop_data\\input\\inputoutputformat\\log.txt"));
//虽然我们自定义OutputFormat继承了FileOutputFormat,而FileOutputFormat需要输出一个_SUCCESS文件,依旧需要设置一个输出路径输出_SUCCESS文件
FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop_data\\output\\sucess"));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
输出结果

发现other.log里的网址连在一起了,输出的时候没输出回车
修改LogRecordWriter类
if(log.contains("ranan")) {
rananOut.writeBytes(log + "\n");
}
else {
//writeBytes参数是string类型
otherOut.writeBytes(log+ "\n");
}
MapReduce05 框架原理OutPutFormat数据输出的更多相关文章
- 新增访客数量MR统计之MR数据输出到MySQL
关注公众号:分享电脑学习回复"百度云盘" 可以免费获取所有学习文档的代码(不定期更新)云盘目录说明:tools目录是安装包res 目录是每一个课件对应的代码和资源等doc 目录是一 ...
- 把数据输出到Word (组件形式)
上一篇的文章中我们介绍了在不使用第三方组件的方式,多种数据输出出到 word的方式,最后我们也提到了不使用组件的弊端,就是复杂的word我们要提前设置模板.编码不易控制.循环输出数据更是难以控制.接下 ...
- 把数据输出到Word (非插件形式)
项目开发过程中,我们要把数据以各种各样的形式展现给客户.把数据以文档的形式展现给客户相信是一种比较头疼的问题,如果没有好的方法会 使得我的开发繁琐,而且满足不了客户的需求.接下来我会通过两种开发方式介 ...
- jquery: json树组数据输出到表格Dom树的处理方法
项目背景 项目中需要把表格重排显示 处理方法 思路主要是用历遍Json数组把json数据一个个append到5个表格里,还要给每个单元格绑定个单击弹出自定义对话框,表格分了单双行,第一行最后还要改ro ...
- 【matlab】将matlab中数据输出保存为txt或dat格式
将matlab中数据输出保存为txt或dat格式 总结网上各大论坛,主要有三种方法. 第一种方法:save(最简单基本的) 具体的命令是:用save *.txt -ascii x x为变量 *.txt ...
- 将matlab中数据输出保存为txt或dat格式
:FID= FOPEN(filename,permission) 用指定的方式打开文件 FID=+N(N是正整数):表示文件打开成功,文件代号是N. FID=-1 : 表示文件打 ...
- ffmpeg 从内存中读取数据(或将数据输出到内存)
更新记录(2014.7.24): 1.为了使本文更通俗易懂,更新了部分内容,将例子改为从内存中打开. 2.增加了将数据输出到内存的方法. 从内存中读取数据 ffmpeg一般情况下支持打开一个本地文件, ...
- 使用MapReduce查询Hbase表指定列簇的全部数据输出到HDFS(一)
package com.bank.service; import java.io.IOException; import org.apache.hadoop.conf.Configuration;im ...
- 《物联网框架ServerSuperIO教程》- 22.动态数据接口增加缓存,提高数据输出到OPCServer和(实时)数据库的效率
22.1 概述及要解决的问题 设备驱动有DeviceDynamic接口,可以继承并增加新的实时数据属性,每次通讯完成后更新这些属性数据.原来是通过DeviceDynamic接口实体类反射的方式获 ...
随机推荐
- Asp.Net mvc4 +Spring
添加相应的引用对象.(以下全部) 修改mvc的Global.asax文件内容 需要将控制器中原来需要new出来的对象改成属性成员 添加这个属性的注入对象 再去修改spring对web.config的一 ...
- 转载: VIVADO的增量综合流程
http://xilinx.eetrend.com/content/2019/100044286.html 从 Vivado 2019.1 版本开始,Vivado 综合引擎就已经可以支持增量流程了.这 ...
- Django(74)drf-spectacular自动生成接口文档
介绍 drf-spectacular是为Django REST Framework生成合理灵活的OpenAPI 3.0模式.它可以自动帮我们提取接口中的信息,从而形成接口文档,而且内容十分详细,再也不 ...
- 自定义容器tomcat应用
看不懂可以先去看:https://www.cnblogs.com/leihongnu/p/14506704.html 1.将103服务器上的mytomcat镜像打包为mytomcat.gz(花时间比较 ...
- 不破不立,祝贺EDG夺得S11冠军。这一夜,我看到太多Flag成真
在昨晚11月6号夜进行的2021英雄联盟S11总决赛中,中国战队EDG夺冠!全国各地高校的男生宿舍像过年一般庆祝夺冠,高呼:EDG世界冠军! 前三局1:2的劣势下,第四局十分胶着,最终EDG顽 ...
- Maven下载、安装、配置
简介 Maven是一个项目管理工具,主要用于Java平台的项目构建.依赖管理和项目生命周期管理. 当然对于我这样的程序猿来说,最大的好处就是对jar包的管理比较方便,只需要告诉Maven需要哪些jar ...
- 在代码生成工具Database2Sharp中增加Vue&Element 工作流页面的快速生成
在我们基于框架开发系统的时候,往往对一些应用场景的页面对进行了归纳总结,因此对大多数情况下的页面呈现逻辑都做了清晰的分析,因此在我们基于框架的基础上,增量式开发业务功能的时候,能够事半功倍.代码生成工 ...
- Idea tomcat debug按钮灰色无法运行
打开Project Structure 2.选中src,点击按钮关闭界面,重启idea即可
- 菜鸡的Java笔记 数字操作类
数字操作类 Math 类的使用 Random 类的使用 BigInteger 和 BigDecimal 类的使用 Math 是一 ...
- Matplotlib (一)
Matplotlib 用于 创建出版质量图标的绘图工具库 目的是为python构建一个 Matlab 式的绘图接口 import matplotlib.pyplot as plt pyplot 模块包 ...