Hadoop学习笔记(8) ——实战 做个倒排索引
Hadoop学习笔记(8)
——实战 做个倒排索引
倒排索引是文档检索系统中最常用数据结构。根据单词反过来查在文档中出现的频率,而不是根据文档来,所以称倒排索引(Inverted Index)。结构如下:
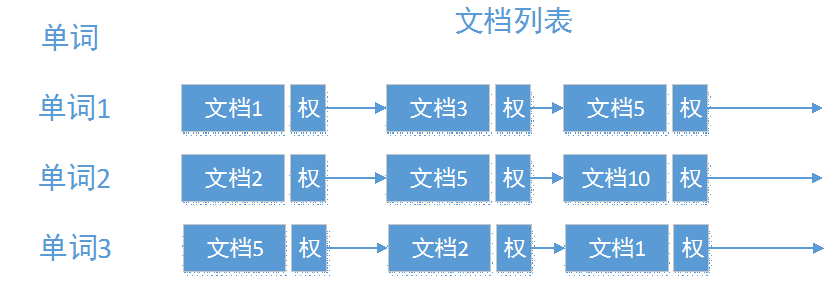
这张索引表中, 每个单词都对应着一系列的出现该单词的文档,权表示该单词在该文档中出现的次数。现在我们假定输入的是以下的文件清单:
|
T1 : hello world hello china T2 : hello hadoop T3 : bye world bye hadoop bye bye |
输入这些文件,我们最终将会得到这样的索引文件:
|
bye T3:4; china T1:1; hadoop T2:1;T3:1; hello T1:2;T2:1; world T1:1;T3:1; |
接下来,我们就是要想办法利用hadoop来把这个输入,变成输出。从上一章中,其实也就是分析如何将hadoop中的步骤个性化,让其工作。整个步骤中,最主要的还是map和reduce过程,其它的都可称之为配角,所以我们先来分析下map和reduce的过程将会是怎样?
首先是Map的过程。Map的输入是文本输入,一条条的行记录进入。输出呢?应该包含:单词、所在文件、单词数。 Map的输入是key-value。 那这三个信息谁是key,谁是value呢? 数量是需要累计的,单词数肯定在value里,单词在key中,文件呢?不同文件内的相同单词也不能累加的,所以这个文件应该在key中。这样key中就应该包含两个值:单词和文件,value则是默认的数量1,用于后面reduce来进行合并。
所以Map后的结果应该是这样的:
|
Key value Hello;T1 1 Hello:T1 1 World:T1 1 China:T1 1 Hello:T2 1 … |
即然这个key是复合的,所以常归的类型已经不能满足我们的要求了,所以得设置一个复合健。复合健的写法在上一章中描述到了。所以这里我们就直接上代码:
- public static class MyType implements WritableComparable<MyType>{
- public MyType(){
- }
- private String word;
- public String Getword(){return word;}
- public void Setword(String value){ word = value;}
- private String filePath;
- public String GetfilePath(){return filePath;}
- public void SetfilePath(String value){ filePath = value;}
- @Override
- public void write(DataOutput out) throws IOException {
- out.writeUTF(word);
- out.writeUTF(filePath);
- }
- @Override
- public void readFields(DataInput in) throws IOException {
- word = in.readUTF();
- filePath = in.readUTF();
- }
- @Override
- public int compareTo(MyType arg0) {
- if (word != arg0.word)
- return word.compareTo(arg0.word);
- return filePath.compareTo(arg0.filePath);
- }
- }
有了这个复合健的定义后,这个Map函数就好写了:
- public static class InvertedIndexMapper extends
- Mapper<Object, Text, MyType, Text> {
- public void map(Object key, Text value, Context context)
- throws InterruptedException, IOException {
- FileSplit split = (FileSplit) context.getInputSplit();
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens()) {
- MyType keyInfo = new MyType();
- keyInfo.Setword(itr.nextToken());
- keyInfo.SetfilePath(split.getPath().toUri().getPath().replace("/user/zjf/in/", ""));
- context.write(keyInfo, "));
- }
- }
- }
注意:第13行,路径是全路径的,为了看起来方便,我们把目录替换掉,直接取文件名。
有了Map,接下来就可以考虑Recude了,以及在Map之后的Combine。Map的输出的Key类型是MyType,所以Reduce以及Combine的输入就必须是MyType了。
如果直接将Map的结果送到Reduce后,发现还需要做大量的工作来将Key中的单词再重排一下。所以我们考虑在Reduce前加一个Combine,先将数量进行一轮合并。
这个Combine将会输入下面的值:
|
Key value bye T3:4; china T1:1; hadoop T2:1; hadoop T3:1; hello T1:2; hello T2:1; world T1:1; world T3:1; |
代码如下:
- public static class InvertedIndexCombiner extends
- Reducer<MyType, Text, MyType, Text> {
- public void reduce(MyType key, Iterable<Text> values, Context context)
- throws InterruptedException, IOException {
- int sum = 0;
- for (Text value : values) {
- sum += Integer.parseInt(value.toString());
- }
- context.write(key, new Text(key.GetfilePath()+ ":" + sum));
- }
- }
有了上面Combine后的结果,再进行Reduce就容易了,只需要将value结果进行合并处理:
- public static class InvertedIndexReducer extends
- Reducer<MyType, Text, Text, Text> {
- public void reduce(MyType key, Iterable<Text> values, Context context)
- throws InterruptedException, IOException {
- Text result = new Text();
- String fileList = new String();
- for (Text value : values) {
- fileList += value.toString() + ";";
- }
- result.set(fileList);
- context.write(new Text(key.Getword()), result);
- }
- }
经过这个Reduce处理,就得到了下面的结果:
|
bye T3:4; china T1:1; hadoop T2:1;T3:1; hello T1:2;T2:1; world T1:1;T3:1; |
最后,MapReduce函数都写完后,就可以挂在Job中运行了。
- public static void main(String[] args) throws IOException,
- InterruptedException, ClassNotFoundException {
- Configuration conf = new Configuration();
- System.out.println("url:" + conf.get("fs.default.name"));
- Job job = new Job(conf, "InvertedIndex");
- job.setJarByClass(InvertedIndex.class);
- job.setMapperClass(InvertedIndexMapper.class);
- job.setMapOutputKeyClass(MyType.class);
- job.setMapOutputValueClass(Text.class);
- job.setCombinerClass(InvertedIndexCombiner.class);
- job.setReducerClass(InvertedIndexReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- Path path = new Path("out");
- FileSystem hdfs = FileSystem.get(conf);
- if (hdfs.exists(path))
- hdfs.delete(path, true);
- FileInputFormat.addInputPath(job, new Path("in"));
- FileOutputFormat.setOutputPath(job, new Path("out"));
- job.waitForCompletion(true);
- }
注:这里为了调试方便,我们把in和out都写死,不用传入执行参数了,并且,每次执行前,判断out文件夹是否存在,如果存在则删除。
Hadoop学习笔记(8) ——实战 做个倒排索引的更多相关文章
- 十六、Hadoop学习笔记————Zookeeper实战
所有服务器都会先将自己的服务器信息注册到servers中,然后每台服务器都会尝试注册master,哪台注册成功,则哪台就是master服务器. 所有的服务器都会关注master节点的删除事件,这样通过 ...
- Hadoop学习笔记系列
Hadoop学习笔记系列 一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(两)设置单节点集群
本文描写叙述怎样设置一个单一节点的 Hadoop 安装.以便您能够高速运行简单的操作,使用 Hadoop MapReduce 和 Hadoop 分布式文件系统 (HDFS). 參考官方文档:Hadoo ...
- Hadoop学习笔记(1)(转)
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
随机推荐
- H - Graphics(dfs)
H - Graphics Time Limit:1000MS Memory Limit:131072KB 64bit IO Format:%lld & %llu Submi ...
- Java io流完成复制粘贴功能
JAVA 中io字节输入输出流 完成复制粘贴功能: public static void main(String[] args) throws Exception{ // 创建输入流要读 ...
- Create Index using NEST .NET
Hello Guys, I have a doubt about how create index using NEST .NET. I created every fields in my C# m ...
- 读取Properties文件的六种方法
1.使用java.util.Properties类的load()方法 示例: InputStream in = new BufferedInputStream(new FileInputStream( ...
- JSP常用Form表单控件
[easyui]--combobox--赋值和获取选中的值 /初始化下拉选框 $('#communityIdDiv').combobox({ url:basepath+"pushContro ...
- axios跨域问题
最近遇到一个很奇怪的问题,在帮助测试妹子做一个小项目的时候,遇到了一个很棘手的问题,axios请求的时候报404,请求type是options,我当时的第一反应就是跨域问题,果然在console里面还 ...
- P4842 城市旅行
题目链接 题意分析 首先存在树上的删边连边操作 所以我们使用\(LCT\)维护 然后考虑怎么维护答案 可以发现 对于一条链 我们编号为\(1,2,3,...,n\) 那么期望就是 \[\frac{a_ ...
- Linux 线程调度策略与线程优先级
Linux内核的三种调度策略 SCHED_OTHER 分时调度策略. 它是默认的线程分时调度策略,所有的线程的优先级别都是0,线程的调度是通过分时来完成的.简单地说,如果系统使用这种调度策略,程序将无 ...
- js 移动端获取当前用户的经纬度
一.HTML5 geolocation的属性 if(navigator.geolocation){ navigator.geolocation.getCurrentPosition(onSuccess ...
- BZOJ3168. [HEOI2013]钙铁锌硒维生素(线性代数+二分图匹配)
题目链接 https://www.lydsy.com/JudgeOnline/problem.php?id=3168 题解 首先,我们需要求出对于任意的 \(i, j(1 \leq i, j \leq ...