第7章 Scrapy突破反爬虫的限制
7-1 爬虫和反爬的对抗过程以及策略
Ⅰ、爬虫和反爬虫基本概念
- 爬虫:自动获取网站数据的程序,关键是批量的获取。
- 反爬虫:使用技术手段防止爬虫程序的方法。
- 误伤:反爬虫技术将普通用户识别为爬虫,如果误伤过高,效果再高也不能用。
- 成本:反爬虫需要的人力和机器成本。
- 拦截:成功拦截爬虫,一般拦截率越高,误伤率越高。
Ⅱ、反爬虫的目的
- 初级爬虫----简单粗暴,不管服务器压力,容易弄挂网站。
- 数据保护
- 失控的爬虫----由于某些情况下,忘记或者无法关闭的爬虫。
- 商业竞争对手
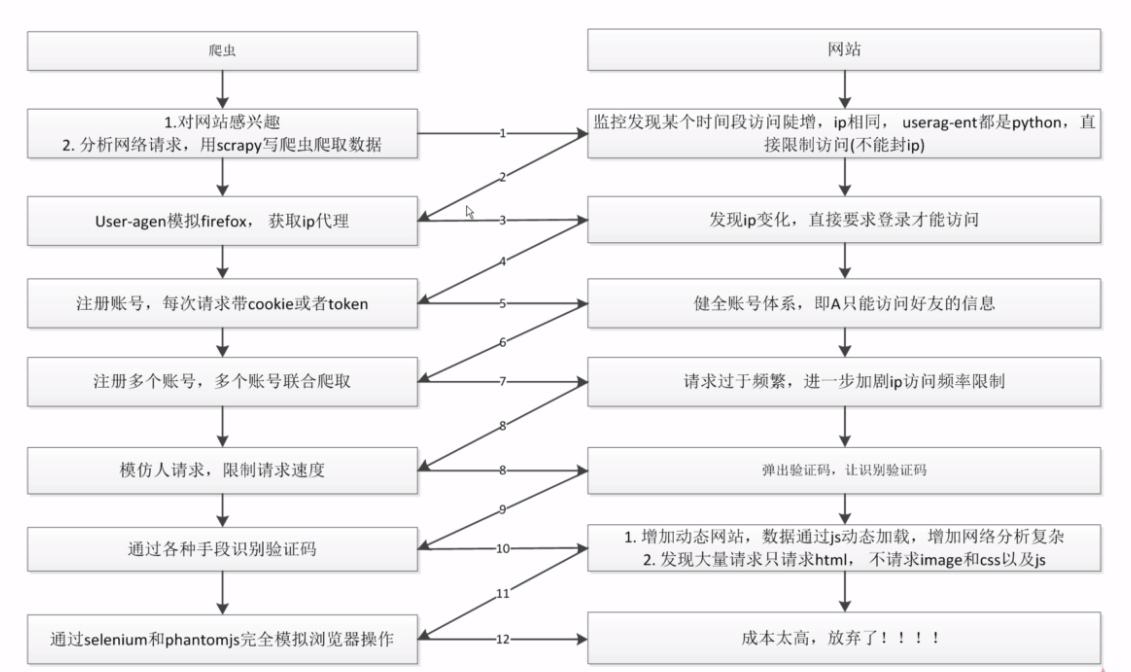
Ⅲ、爬虫和反爬虫对抗过程
7-2 scrapy架构源码分析
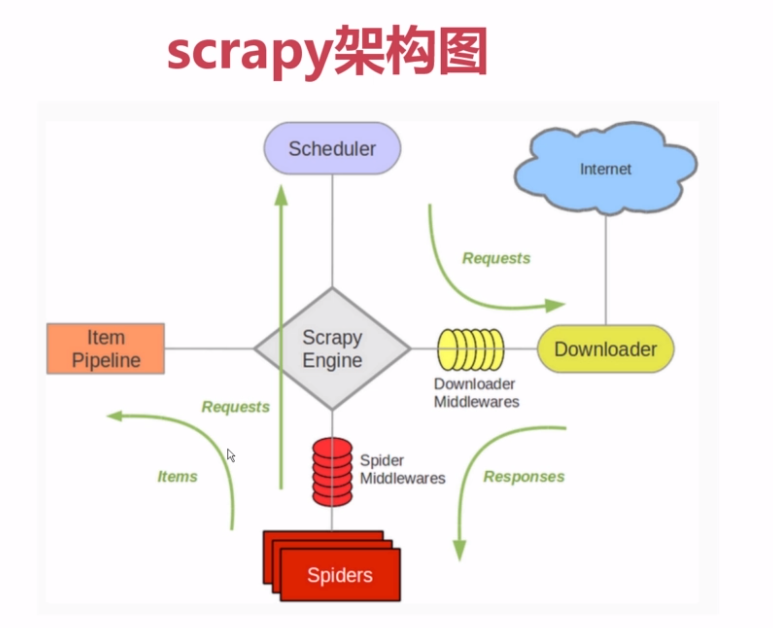
原理图:
我最早接触scrapy的时候就是看这张原理图,如下图
现在有新的原理图,更加直观,如下图
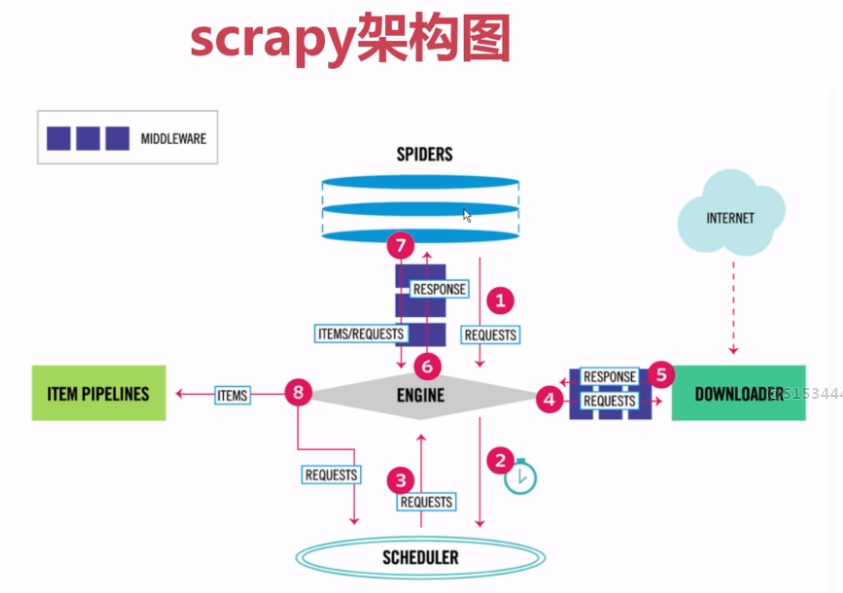
看了视频讲的源码解析,看一遍根本看不懂,后期还要多看叫上项目的练习才行。
7-3 Requests和Response介绍
可以看scrapy文档: http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 查看相关的说明即可。
模拟登陆后,Request会自动传递cookies,不用我们添加。
7-4~5 通过downloadmiddleware随机更换user-agent
这是个模版以后直接拿来用即可
#middlewares.py文件
from fake_useragent import UserAgent #这是一个随机UserAgent的包,里面有很多UserAgent
class RandomUserAgentMiddleware(object):
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__() self.ua = UserAgent()
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE', 'random') #从setting文件中读取RANDOM_UA_TYPE值 @classmethod
def from_crawler(cls, crawler):
return cls(crawler) def process_request(self, request, spider):
def get_ua():
'''Gets random UA based on the type setting (random, firefox…)'''
return getattr(self.ua, self.ua_type) user_agent_random=get_ua()
request.headers.setdefault('User-Agent', user_agent_random) #这样就是实现了User-Agent的随即变换
#settings.py文件
DOWNLOADER_MIDDLEWARES = {
'Lagou.middlewares.RandomUserAgentMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None, #这里要设置原来的scrapy的useragent为None,否者会被覆盖掉
}
RANDOM_UA_TYPE='random'
7-6~8 scrapy实现ip代理池
这是个模版以后直接拿来用即可
#middlewares.py文件
class RandomProxyMiddleware(object):
'''动态设置ip代理'''
def process_request(self,request,spider):
get_ip = GetIP() #这里的函数是传值ip的
request.meta["proxy"] = get_ip
#例如
#get_ip = GetIP() #这里的函数是传值ip的
#request.meta["proxy"] = 'http://110.73.54.0:8123' #settings.py文件
DOWNLOADER_MIDDLEWARES = {
'Lagou.middlewares.RandomProxyMiddleware':542,
'Lagou.middlewares.RandomUserAgentMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None, #这里要设置原来的scrapy的useragent为None,否者会被覆盖掉
}
1.sql语言取出随机记录:在此是随机取出一条记录是ip和端口组成代理IP
select ip,port from proxy_ip
order by rand()
limit 1
2.使用xpath选择器:
可以使用scrapy中的selector,代码如下:
from scrapy.selector import Selector
html=requests.get(url)
Selector=Selector(text=html.text)
Selector.xpath()
3.if __name__ == "__main__"问题
如果没有这个,调用时会默认运行以下命令
if __name__ == "__main__":
get_ip=GetIp()
get_ip.get_random_ip()
7-9 云打码实现验证码识别
验证码识别方法
- 编码实现(tesseract-ocr)
- 在线打码----打码平台(云打码、若快)
- 人工打码
7-10 cookie禁用、自动限速、自定义spider的settings
如果用不到cookies的,就不要让对方知道你的cookies--设置---COOKIES_ENABLED = False
自定义setting中的参数可以这样写:
#在spider.py文件中
custom_settings={
"COOKIES_ENABLED":True,
"":"",
"":"",
}
作者:今孝
出处:http://www.cnblogs.com/jinxiao-pu/p/6762636.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
第7章 Scrapy突破反爬虫的限制的更多相关文章
- Python Scrapy突破反爬虫机制(项目实践)
对于 BOSS 直聘这种网站,当程序请求网页后,服务器响应内容包含了整个页面的 HTML 源代码,这样就可以使用爬虫来爬取数据.但有些网站做了一些“反爬虫”处理,其网页内容不是静态的,而是使用 Jav ...
- Scrapy突破反爬虫的限制
随机切换UserAgent https://github.com/hellysmile/fake-useragent scrapy使用fake-useragent 在全局配置文件中禁用掉默认的UA,将 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 自动更改IP地址反爬虫封锁,支持多线程(转)
8年多爬虫经验的人告诉你,国内ADSL是王道,多申请些线路,分布在多个不同的电信机房,能跨省跨市更好,我这里写好的断线重拨组件,你可以直接使用. ADSL拨号上网使用动态IP地址,每一次拨号得到的IP ...
- 深入细枝末节,Python的字体反爬虫到底怎么一回事
内容选自 即将出版 的<Python3 反爬虫原理与绕过实战>,本次公开书稿范围为第 6 章——文本混淆反爬虫.本篇为第 6 章中的第 4 小节,其余小节将 逐步放送 . 字体反爬虫开篇概 ...
- Python Scrapy反爬虫常见解决方案(包含5种方法)
爬虫的本质就是“抓取”第二方网站中有价值的数据,因此,每个网站都会或多或少地采用一些反爬虫技术来防范爬虫.比如前面介绍的通过 User-Agent 请求头验证是否为浏览器.使用 JavaScript ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- scrapy反反爬虫
反反爬虫相关机制 Some websites implement certain measures to prevent bots from crawling them, with varying d ...
随机推荐
- console使用技巧
http://heikezhi.com/yuanyi/10%E4%B8%AAchrome%20console%E5%AE%9E%E7%94%A8%E5%B0%8F%E6%8A%80%E5%B7%A7 ...
- 【OCP-12c】2019年CUUG OCP 071考试题库(78题)
78.View the exhibit and examine the structure of the CUSTOMERStable. Which two tasks would require s ...
- 使用html2canvas截图并用jspdf打印的问题
之前的方案确实可以打印出a4的大小的pdf,但是也呈现了诸多问题,因为这种方法是截图然后再进行打印的,所以打印出来的效果是模糊的,思前想后决定放弃了这种方式. 最终还是决定使用浏览器自带的打印方法. ...
- Linux 中使用 virsh 管理 KVM 虚拟机 (转)
术语 虚拟化指的是:在相同的物理(硬件)系统上,同时运行多个操作系统,且这几个系统相互隔离的可能性,而那个硬件在虚拟化架构中被称作宿主机(host).虚拟机监视器(也被称为虚拟机管理程序(hyperv ...
- jmeter ——JDBC Request中从数据库中读两个字段给接口取值
前置条件数据库: 给接口传:tid和shopid这俩字段 直接从JDBC Request开始: Variable name:这里写入数据库连接池的名字(和JDBC Connection Configu ...
- Spring Boot 入门系列
本系列博文版权 简书 面皮大师 所有,转载请标明原文及出处: http://www.jianshu.com/u/062bd8f1299c 项目地址: https://github.com/daleiw ...
- 哈工大ComingX-创新工场俱乐部正式成立
当我把这两个Logo放在一起的时候,我有一种感觉,这种感觉同样存在于ComingX队员的心中.大学我们走到了一起,非你我所预料,却又如此自然.在感恩节的零点,我迫不及待地告诉各位ComingX队员和关 ...
- C语言数据结构之二叉树的实现
本篇博文是博主在学习C语言算法与数据结构的一些应用代码实例,给出了以二叉链表的形式实现二叉树的相关操作.如创建,遍历(先序,中序后序遍历),求树的深度,树的叶子节点数,左右兄弟,父节点. 代码清单如下 ...
- CODEVS-1018单词接龙
单词接龙 原题:传送门 解题思路: 此题是典型的深搜题目,首先确定递归变量,表示字母的数量,每当满足一定条件,就往下一层递归,否则回溯 判断由哪个单词开始(因为可能字母首位可能相同),再确定之后所连单 ...
- MySQL Migration Tool报“initialized java loader”错误的问题
MySQL Migration Tool报“initialized java loader”错误的问题 运行MySQL Migration Tool时经常会提示“An error occured ...