elastic-job(lite)使用的一些注意事项
前段时间项目开发中用到了当当开源的elastic-job,使用过程遇到一些问题,虽然不见得会影响写代码,但作为一个致力于搬好每一块砖的码农,当碰到问题时,我们不应该逃避,应该本着有困难也要上,没有困难创造困难也要上的精神冲上去搞定它,这样才能更容易了解事情的本质,才能有利于以后搬好每一块砖,佝偻者承蜩如是,我等搬砖亦复如是。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
1、官方提到“同一台服务器只能运行一个相同作业实例,因为作业运行时是按照ip注册和管理的”,那么:假如程序在同一台电脑上部署两个作业实例,结果会如何,会进行正常分片么?
该问题测试结果为:分片参数以shardingItemParameters=0=A,1=B,2=C,3=D,4=E,5=F,6=G,7=H,8=I,9=J为例:
a:同一机器,运行两个不同端口的tomcat--------不能分片,因tomcat端口未注册到zk,程序无法识别这两个tomcat,这两个tomcat不会触发分片,如果只部署一台机器,
两个tomcat拿到的分片参数都是全部的分片参数0=A,1=B,2=C,3=D,4=E,5=F,6=G,7=H,8=I,9=J
b:同一机器,部署两个docker(或者其它能提供ip的容器),分别在其中用tomcat运行程序--------可以分片,两个docker的不同的ip会被注册到zk,从而触发分片。
测试图如下:
两个镜像:testdocker:v1根testdocker:v2
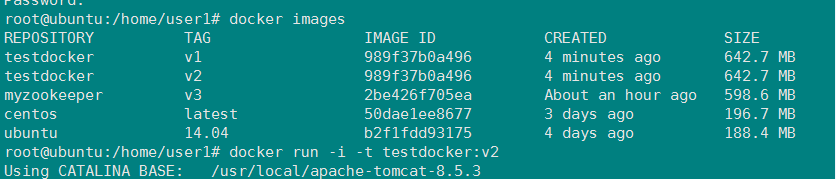
两个docker中控制台日志截图

对此问题,官方说明很清楚,作业是按照ip进行注册和管理的,同一个ip只能运行一个相同name的作业。因为zk上区分不同的服务器就是靠ip来区分的,程序在zk上注册的信息如下图:

可以看到,zk中只有服务器ip,并无容器的端口之类信息,因此,,,,
2、运维界面中,【暂停】按钮有何作用,因为官方说明中,运维程序只作监控,并不能操作任务的启停,此处按钮作用作何理解?(目前该部分说明已因改版而从官网删除)
此处当时应为版本遗留问题,文档未做更新导致,新版运维程序界面中有4个按钮,比原来多了两个,暂停、恢复等均为字面意思,不作解释。该问题本地测试结果如下:

可以看到,蓝色服务器在2016-07-23 15:19:50--15:20:09隔了19秒,这段时间只有白色服务器在运行。白色服务器并没有受到蓝色暂停的影响,分片参数仍按蓝色正常进行计算。
在运维界面点击【恢复】后,蓝色服务器又开始运行。
此处注意,若暂停的为主节点服务器(主节点一栏为对号的),会暂停所有服务器的该任务,运维界面有提示文字说明该情况。
3、分片不均,服务器执行任务时间不等的情况下,是否会出现相互等待的情况?
测试结果为: A、B两台服务器,都是5秒执行一次,A执行很快(认为是0s)B执行很慢(需要8秒),A并不会等待B。验证图如下:

此问题,曾有小伙伴怀疑是否跟配置相关,并附代码如下:

此处依据是否开启monitorexecution,从而判断是否等待其它服务器;但需要注意的是,这里是重新分片时候的操作,注释中说的明白,如果要分片,且当前为主服务器,且开启了monitorexecution,则等待,跟本小节讨论的问题不是同一问题。因此,目前未发现与此问题相关的配置;当前版本是1.0.7。
4、失效转移(failover)问题究竟怎么理解,对性能有何影响?
官网的解释不多,此问题可以理解为:开启失效转移的情况下,如果任务执行过程中一台服务器失去连接,那么已经分配到该服务器的任务,将会在下次任务执行之前被当前集群中正常的服务器获取分片并执行,执行结束后再进行下一次任务;未开启失效转移,那么服务器丢失后,程序将不作任务处理,任由其丢失,但下次任务会重新分片。
两台机器(一个物理机,一个虚拟机),10个分片,每1分钟执行一次任务(每个任务sleep10s,模拟任务执行花费的时间),执行过程中中断虚拟机网络,使其失去跟zk的连接,测试结果如下:

图1:虚拟机日志截图

图2:物理机eclipse日志截图
观察两图,可以看到以下四个过程:
1、物理机先启动并执行第一次任务,获取全部分片;
2、然后虚拟机启动,第二次任务执行时,两台机器各分5个分片,该次任务两台机器均正常执行;
3、第三次任务开始,两台机器各获取5分片,任务执行的10s内,虚拟机断开跟物理机zk的连接:
这时候,断开的虚拟机仍然正常执行自己已经获得的分片任务,物理机开始阶段也正常执行自己获得的分片任务,但执行完毕后32s,又获得了分片4=E,这时候可以看到时间并未
到达1分钟,也就是并未达到下次任务开始时间;稍后又分多次获取了本次分给虚拟机的其它分片,我们可以看到获取到所有分片的时间已经超过了1分钟;分片执行结束后,并未
等待,而是直接执行了下一次任务(原来都是1分钟整点执行,这次是在22s执行);
4、虚拟机丢失,物理机获取所有分片信息,并且执行时间变成了从22s开始执行。
注意:该过程中,分片0-4对应的业务信息,实际被执行了两次,可能会对业务数据产生影响。
failover对性能有影响有一个前提是开启monitor-execution,这个监控是造成性能下降的关键。failover=true,monitor-execution=false的情况下,failover不会生效(本地测试结果如此,需要monitor-execution的支持)。
官方早起版本monitor-execution默认开启,在我们当时用的1.07版本中,该属性默认关闭。
对于该属性,官方的观点是短期执行的任务不建议开启,会明显影响性能。对于执行周期很长且业务需求的才建议开启。若丢失的服务器,下次重新分片后,原来丢失的分片不影响业务,仍可以不开启。
也就是说,开启会造成性能问题;关闭,如果有服务器丢失:
1、跟zk断开,跟其它没断开,本次任务仍然正常运行,不会对业务造成影响;
2、跟zk断开,跟其它也断开,本次任务出现异常(数据库连接失败等),会影响业务;需要程序处理异常或者事后人工处理;
3、跟zk没断,跟其它断开,任务分片会正常过来,但任务执行异常,会影响业务,需要程序处理异常或者事后人工处理;
------------------------------------------------------------------------------------------------------------------------------------------------------------------
以上问题为实际开发过程中遇到的疑问,自己在本地测试的结果,难免有考虑不周的情况,有错误之处欢迎留言讨论。
ps:今天看了下官网,发现官方已经推出elastic-job-cloud了!这是个什么东东?!看上去貌似很好很强大,稍后得看一下,努力追赶各路开源大神的脚步,,,,,
elastic-job(lite)使用的一些注意事项的更多相关文章
- Job控制台(elastic job lite console)
elastic job lite console: 设计理念 1.本控制台和Elastic Job并无直接关系,是通过读取Elastic Job的注册中心数据展现作业状态,或更新注册中心数据修改全局配 ...
- 浅尝 Elastic Stack (一) Elasticsearch、Kibana、Beats 安装
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash,也称为 ELK Stack.能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据进 ...
- Elastic数据迁移方法及注意事项
需求 ES集群Cluster_A里的数据(某个索引或某几个索引),需要迁移到另外一个ES集群Cluster_B中. 环境 Linux:Centos7 / Centos6.5/ Centos6.4Ela ...
- ios app 提交评审注意事项
在网络上看到的一个文档是这样写,原文的出处无法确认了 基本要点 · 不能导致手机故障(比如崩溃或屏幕问题) · 长时间/过度使用之后反应仍然很快 · 应 ...
- elk部署之前注意事项
注意事项: 1.不能使用root用户登录,需要是用root 之外的用户登录到系统. 2.centos系统 运行内存不能小于2G,若低于2G需要修改jvm. vi {jvm_home}/config/ ...
- elastic job配置
zookeeper注册中心配置 1 package com.zwh.pay.account.worker; import com.dangdang.ddframe.job.reg.zookeeper. ...
- APP上线审核注意事项
基本要点 · 不能导致手机故障(比如崩溃或屏幕问题) · 长时间/过度使用之后反应仍然很快 · 应用内的所有价格信息中不能用固定值代替可变变量 · ...
- AWS云创建EC2与使用注意事项-踩坑记录
目录 AWS 一 创建 EC2(云服务器) 二.AWS 注意事项 三.AWS 申请 SSL 证书 四. 创建VPC AWS 文章 GitHub 地址: 点我 AWS云服务器价格计算器 AWS WEB ...
- elastic search&logstash&kibana 学习历程(一)es基础环境的搭建
elastic search 6.1.x 常用框架: 1.Lucene Apache下面的一个开源项目,高性能的.可扩展的工具库,提供搜索的基本架构: 如果开发人员需用使用的话,需用自己进行开发,成本 ...
随机推荐
- ubantu 文件解压缩
对于刚刚接触Linux的人来说,一定会给Linux下一大堆各式各样的文件名给搞晕.别个不说,单单就压缩文件为例,我们知道在Windows下最常见 的压缩文件就只有两种,一是,zip,另一个是.rar. ...
- Oracle PLSQL Demo - 17.游标查询个别字段(非整表)
declare Type ref_cur_variable IS REF cursor; cur_variable ref_cur_variable; v_empno scott.emp.empno% ...
- 开发song-list组件;
注意点: 1.song-list的高度是通过计算动态获取的: 2.可以直接在{{}}调用函数,来显示函数的返回值: <template> <div class="song- ...
- Date函数基础知识整理
Date类型:1.Date.parse()接收一个表示日期的字符串参数,然后再根据这个字符串返回响应的日期的毫秒数:如:创建一个日期: <script> // var someDate=n ...
- 将ASCII字符串转换为UNICODE字符串
写在前面的话:在MFC的网络编程中,由于现在项目都是使用UNICODE编码,但是网络API的许多函数却只能接受const char*的参数,所以经常会遇到需要将char*转换为TCHAR*的时候,有一 ...
- js怎么让时间函数的秒数在页面上显示是变化的
<input type="text" id="showtime" value="" /><script type=&quo ...
- Celery+python+redis异步执行定时任务
我之前的一篇文章中写了[Celery+django+redis异步执行任务] 博文:http://blog.csdn.net/apple9005/article/details/54236212 你会 ...
- AMQP学习 & RabbitMQ 与 ActiveMQ、ZeroMQ以及Kafka的比较
之前写了一篇文章关于Active以及消息队列推拉模式的文章,可以参考:link 关于 Active 与 RabbitMQ以及其他的比较,有如下记录: 这篇文章 link 提到: 基本介绍RabbitM ...
- 一款基于jquery的侧边栏导航
之前为大家介绍了好多导航菜单,今天给大家分享一款基于jquery的侧边栏导航.这款导航侧边滑出,适合放在手机网页或webapp.一看下实现的效果图: 在线预览 源码下载 实现的代码. html代码 ...
- Android-——多线程之Handler(转)
Android--多线程之Handler 原文地址:http://www.cnblogs.com/shirley-1019/p/3557800.html 前言 Android的消息传递机制是另外一种形 ...