字典树 trie
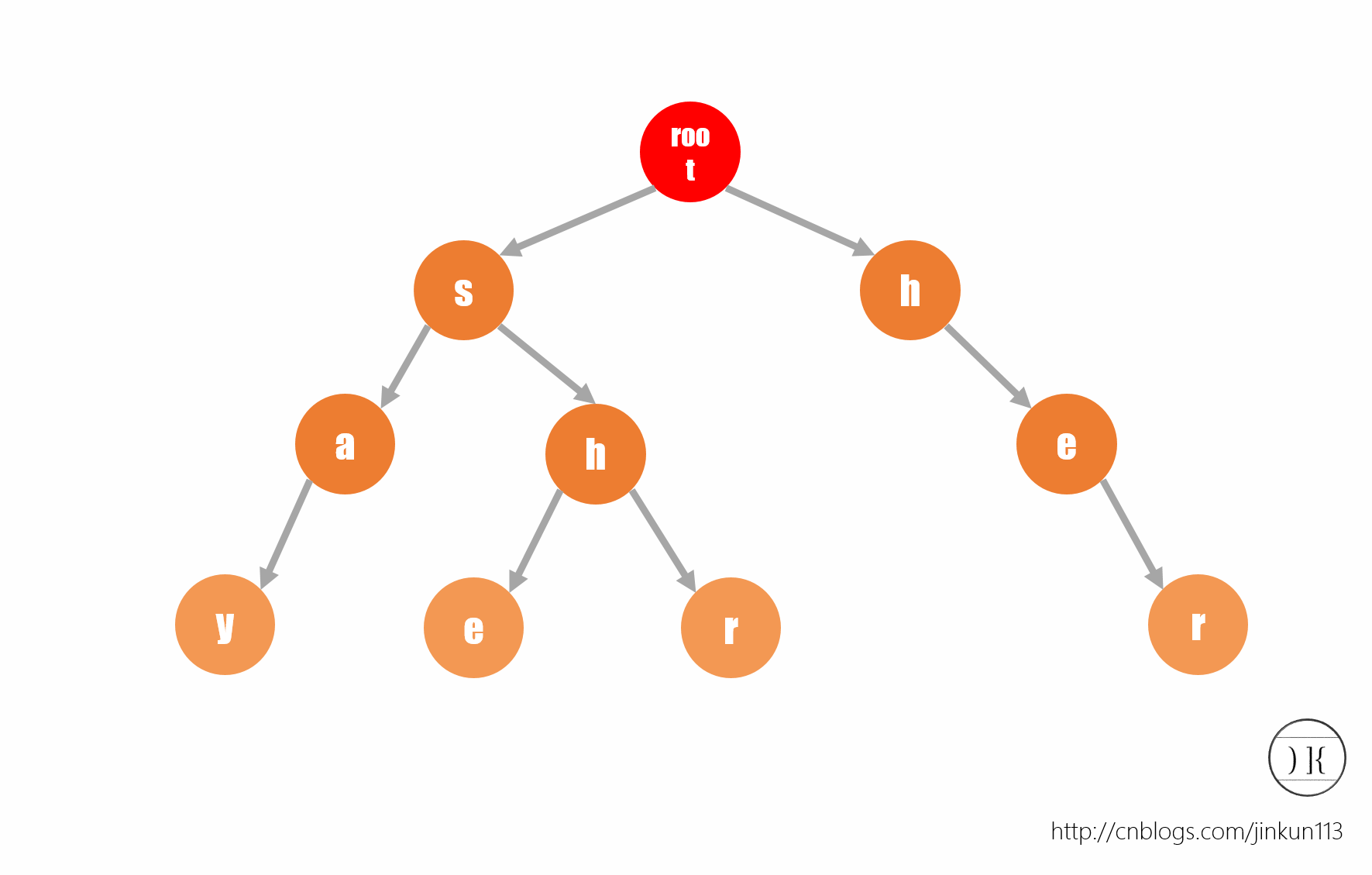
如图所示,该字符串保存了say,she,shr,her四个字符串。有个小小的问题:在建树的时候,我们注意到最坏情况可能为二十六叉树,空间复杂度可想而知。所以,如果用指针可能更省空间。
Applications 应用
Trie (we pronounce "try") or prefix tree is a tree data structure, which is used for retrieval of a key in a dataset of strings. There are various applications of this very efficient data structure such as :
1. Autocomplete

Figure 1. Google Suggest in action.
2. Spell checker
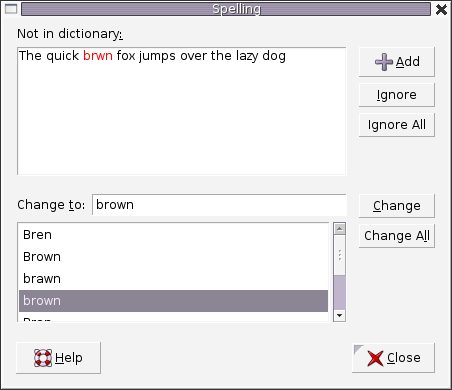
Figure 2. A spell checker used in word processor.
3. IP routing (Longest prefix matching)
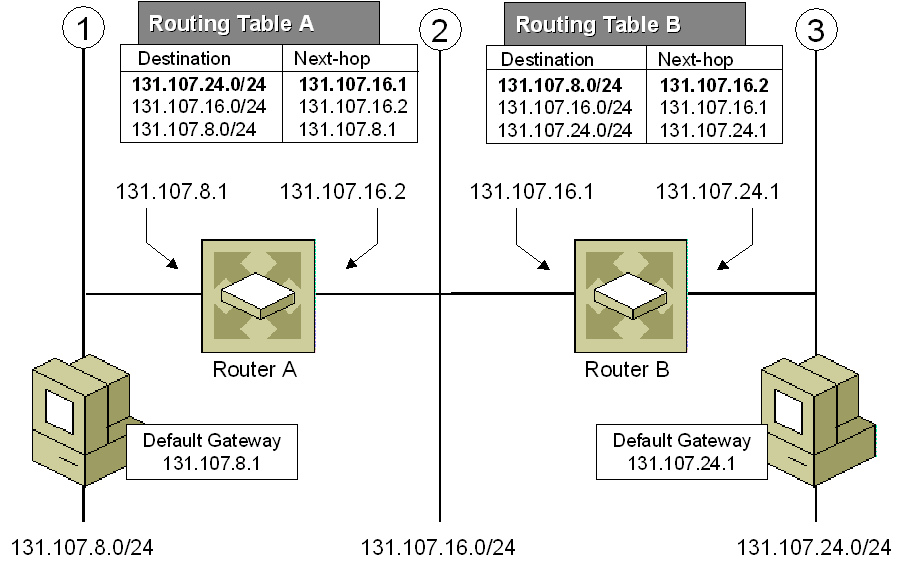
Figure 3. Longest prefix matching algorithm uses Tries in Internet Protocol (IP) routing to select an entry from a forwarding table.
4. T9 predictive text
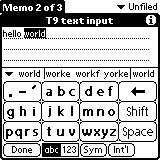
Figure 4. T9 which stands for Text on 9 keys, was used on phones to input texts during the late 1990s.
5. Solving word games

Figure 5. Tries is used to solve Boggle efficiently by pruning the search space.
There are several other data structures, like balanced trees and hash tables, which give us the possibility to search for a word in a dataset of strings. Then why do we need trie? Although hash table has O(1)O(1) time complexity for looking for a key, it is not efficient in the following operations :
平衡树根hash表可以实现字符串搜索,为什么还需要trie?在以下操作时很低效
- Finding all keys with a common prefix.
- Enumerating a dataset of strings in lexicographical order.
- 寻找所有keys的共同前缀
- 以编辑顺序枚举所有的字符串
Another reason why trie outperforms hash table, is that as hash table increases in size, there are lots of hash collisions and the search time complexity could deteriorate to O(n)O(n), where nn is the number of keys inserted. Trie could use less space compared to Hash Table when storing many keys with the same prefix. In this case using trie has only O(m)O(m) time complexity, where mm is the key length. Searching for a key in a balanced tree costs O(m \log n)O(mlogn) time complexity.
另一个原因,key变多之后,hash表会不断变大,导致冲突,时间复杂度会退化到O(n).
Trie node structure
Trie is a rooted tree. Its nodes have the following fields:
- Maximum of RR links to its children, where each link corresponds to one of RR character values from dataset alphabet. In this article we assume that RR is 26, the number of lowercase latin letters.
- Boolean field which specifies whether the node corresponds to the end of the key, or is just a key prefix.

Figure 6. Representation of a key "leet" in trie.
Insertion of a key to a trie
We insert a key by searching into the trie. We start from the root and search a link, which corresponds to the first key character. There are two cases :
- A link exists. Then we move down the tree following the link to the next child level. The algorithm continues with searching for the next key character.
- A link does not exist. Then we create a new node and link it with the parent's link matching the current key character. We repeat this step until we encounter the last character of the key, then we mark the current node as an end node and the algorithm finishes.
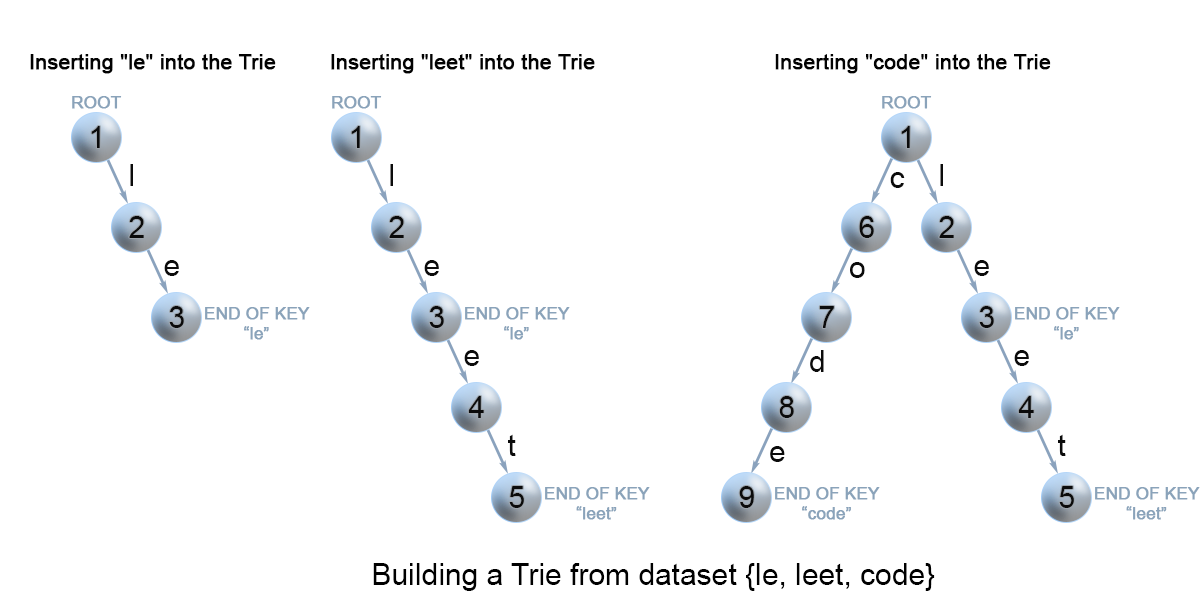
Figure 7. Insertion of keys into a trie.
Complexity Analysis
- Time complexity : O(m)O(m), where m is the key length.
In each iteration of the algorithm, we either examine or create a node in the trie till we reach the end of the key. This takes only mm operations.
- Space complexity : O(m)O(m).
In the worst case newly inserted key doesn't share a prefix with the the keys already inserted in the trie. We have to add mm new nodes, which takes us O(m)O(m) space.
Search for a key in a trie
Each key is represented in the trie as a path from the root to the internal node or leaf. We start from the root with the first key character. We examine the current node for a link corresponding to the key character. There are two cases :
- A link exist. We move to the next node in the path following this link, and proceed searching for the next key character.
A link does not exist. If there are no available key characters and current node is marked as
isEndwe return true. Otherwise there are possible two cases in each of them we return false :- There are key characters left, but it is impossible to follow the key path in the trie, and the key is missing.
- No key characters left, but current node is not marked as
isEnd. Therefore the search key is only a prefix of another key in the trie.
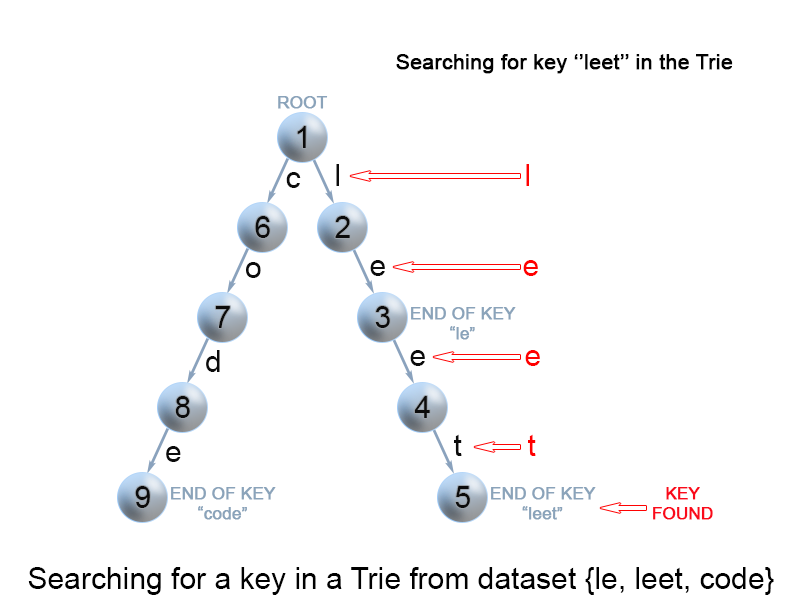
Figure 8. Search for a key in a trie.
Complexity Analysis
Time complexity : O(m)O(m) In each step of the algorithm we search for the next key character. In the worst case the algorithm performs mm operations.
Space complexity : O(1)O(1)
Search for a key prefix in a trie
The approach is very similar to the one we used for searching a key in a trie. We traverse the trie from the root, till there are no characters left in key prefix or it is impossible to continue the path in the trie with the current key character. The only difference with the mentioned above search for a key algorithm is that when we come to an end of the key prefix, we always return true. We don't need to consider the isEnd mark of the current trie node, because we are searching for a prefix of a key, not for a whole key.
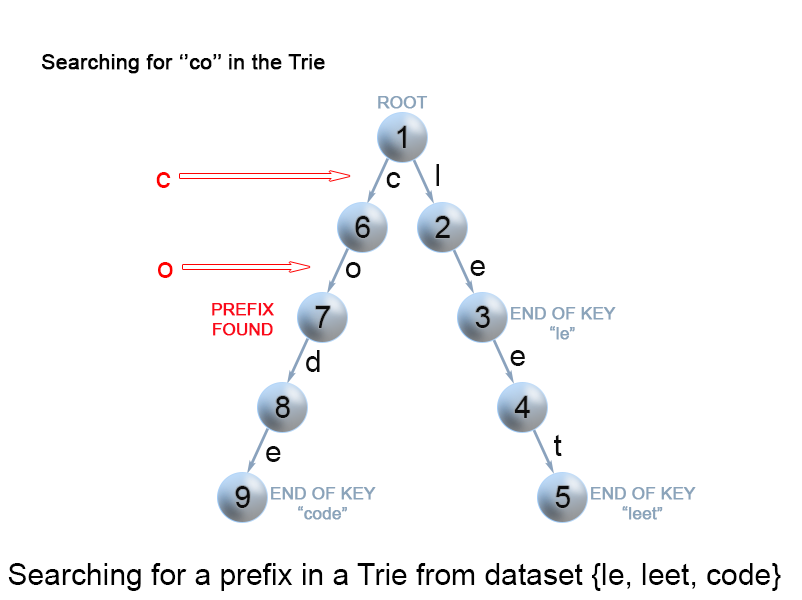
Figure 9. Search for a key prefix in a trie.
Complexity Analysis
Time complexity : O(m)O(m)
Space complexity : O(1)O(1)
Practice Problems
Here are some wonderful problems for you to practice which uses the Trie data structure.
- Add and Search Word - Data structure design - Pretty much a direct application of Trie.
- Word Search II - Similar to Boggle.
Analysis written by: @elmirap.
字典树 trie的更多相关文章
- [POJ] #1002# 487-3279 : 桶排序/字典树(Trie树)/快速排序
一. 题目 487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 274040 Accepted: 48891 ...
- 『字典树 trie』
字典树 (trie) 字典树,又名\(trie\)树,是一种用于实现字符串快速检索的树形数据结构.核心思想为利用若干字符串的公共前缀来节约储存空间以及实现快速检索. \(trie\)树可以在\(O(( ...
- 字典树trie学习
字典树trie的思想就是利用节点来记录单词,这样重复的单词可以很快速统计,单词也可以快速的索引.缺点是内存消耗大 http://blog.csdn.net/chenleixing/article/de ...
- 字典树(Trie)详解
详解字典树(Trie) 本篇随笔简单讲解一下信息学奥林匹克竞赛中的较为常用的数据结构--字典树.字典树也叫Trie树.前缀树.顾名思义,它是一种针对字符串进行维护的数据结构.并且,它的用途超级广泛.建 ...
- 字典树(Trie Tree)
在图示中,键标注在节点中,值标注在节点之下.每一个完整的英文单词对应一个特定的整数.Trie 可以看作是一个确定有限状态自动机,尽管边上的符号一般是隐含在分支的顺序中的.键不需要被显式地保存在节点中. ...
- 字典树(Trie树)实现与应用
一.概述 1.基本概念 字典树,又称为单词查找树,Tire数,是一种树形结构,它是一种哈希树的变种. 2.基本性质 根节点不包含字符,除根节点外的每一个子节点都包含一个字符 从根节点到某一节点.路径上 ...
- 字典树(Trie树)的实现及应用
>>字典树的概念 Trie树,又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构,如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树.与二叉查找树不同,Trie树的 ...
- 字典树trie的学习与练习题
博客详解: http://www.cnblogs.com/huangxincheng/archive/2012/11/25/2788268.html http://eriol.iteye.com/bl ...
- [转载]字典树(trie树)、后缀树
(1)字典树(Trie树) Trie是个简单但实用的数据结构,通常用于实现字典查询.我们做即时响应用户输入的AJAX搜索框时,就是Trie开始.本质上,Trie是一颗存储多个字符串的树.相邻节点间的边 ...
- Codevs 4189 字典(字典树Trie)
4189 字典 时间限制: 1 s 空间限制: 256000 KB 题目等级 : 大师 Master 传送门 题目描述 Description 最经,skyzhong得到了一本好厉害的字典,这个字典里 ...
随机推荐
- Webservice简单案例
东西不用,时间长了就会被忘掉.重新拾起来 做一个简单的Demo,便于以后的查询 服务器端--新建Calculator.asmx using System; using System.Collectio ...
- partition的分配策略简单代码实现
先说说partition的好处:Partition的好处是可以并发的获取同类数据,提高效率. 第一步需要实现Partitioner对象. public class ProducerPartitione ...
- TextSwitcher实现文本自动垂直滚动
实现功能:用TextSwitcher实现文本自动垂直滚动,类似淘宝首页广告条. 实现效果: 注意:由于网上横向滚动的例子比较多,所以这里通过垂直的例子演示. 实现步骤:1.extends TextSw ...
- On iPad, UIImagePickerController must be presented via UIPopoverController
本文转载至:http://blog.csdn.net/k12104/article/details/8537695 On iPad, UIImagePickerController must be p ...
- 《C++ Primer Plus》第11章 使用类 学习笔记
本章介绍了定义和使用类的许多重要方面.一般来说,访问私有类成员的唯一方法是使用类方法.C++使用友元函数来避开这种限制.要让函数称为友元,需要在类声明中声明该函数,并在声明前加上关键字friend.C ...
- <转>SVM实现之SMO算法
转自http://blog.csdn.net/zouxy09/article/details/17292011 终于到SVM的实现部分了.那么神奇和有效的东西还得回归到实现才可以展示其强大的功力.SV ...
- 【linux】安装rar,并解压被压缩成多个rar的文件
rar 官网:http://www.rarsoft.com/download.htm 选择 RAR for linux (注意你的系统是32位还是64位) 1 安装命令: $ cd /roo ...
- 【linux系列】vi模式下查找和替换
一.查找 1.查找命令 /pattern<Enter> :向下查找pattern匹配字符串 ?pattern<Enter> :向上查找匹配字符串 在使用了查找命令之后,使用如下 ...
- Windows Phone 自定义一个启动画面
1.新建一个UserControl <UserControl x:Class="LoadingPage.PopupSplash" xmlns="http://sch ...
- linux设置安全连接设置(私钥)
1.私钥制作工具:puttygen 连接工具:xshell和putty. 2.制作私钥和公钥 a.打开puttygen点击Generate生产公钥和私钥(鼠标需要晃动,进度条才会前进) b. 设置标签 ...