solr特点九:word(分词)
在Solr中配置中文分词IKAnalyzer
1、在配置文件schema.xml(位置{SOLR_HOME}/config/下),配置信息如下:
<!-- IKAnalyzer 中文分词-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" isMaxWordLength="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" isMaxWordLength="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
2、在IKAnalyzer相关的jar包(IKAnalyzer2012_u6.jar 本博客不提供下载)放在{SOLR_HOME}/lib下。
3、测试IKAnalyzer中文分词 效果:
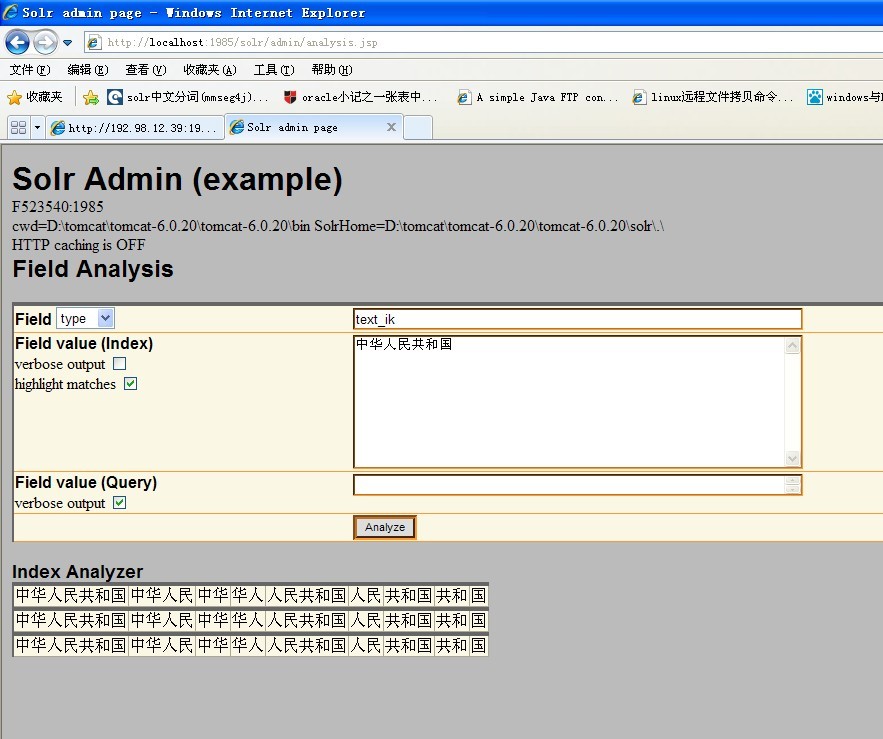
ikanlyzer分词效果还是不错的 ,通过配置可以扩展个人词典、自定义停顿词等。配置信息如下:
IKAnalyzer.cfg.xml配置文件
把stopword.dic和IKAnalyzer.cfg.xml复制到class根目录就可以启用停用词功能和扩展自己的词典
<?xmlversion="1.0"encoding="UTF-8"?>
<!DOCTYPEpropertiesSYSTEM"http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entrykey="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entrykey="ext_stopwords">stopword.dic;</entry>
</properties>
如果想在solr中使用IK来加载扩展词典,需要将以上的配置文件和词典扩展文件放在tomcat/webapps/solr/WEB-INF/classes下。同时,比如我的ext.dic中有以下内容:

那么在solr中分词效果便是:

solr特点九:word(分词)的更多相关文章
- Solr多核心及分词器(IK)配置
Solr多核心及分词器(IK)配置 多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索 ...
- Java——word分词·自定义词库
word: https://github.com/ysc/word word-1.3.1.jar 需要JDK8word-1.2.jar c语言给解析成了“语言”,自定义词库必须为UTF-8 程序一旦运 ...
- 全文检索引擎Solr系列——整合中文分词组件mmseg4j
默认Solr提供的分词组件对中文的支持是不友好的,比如:“VIM比作是编辑器之神”这个句子在索引的的时候,选择FieldType为”text_general”作为分词依据时,分词效果是: 它把每一个词 ...
- 在Solr中配置中文分词IKAnalyzer
李克华 云计算高级群: 292870151 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch 在Solr中配置中文分词IKAnalyzer 1.在配置文件schema.xml ...
- Solr整合Ansj中文分词器
Ansj的使用和相关资料下载参考:http://iamyida.iteye.com/blog/2220833 参考 http://www.cnblogs.com/luxh/p/5016894.html ...
- 三、Solr多核心及分词器(IK)配置
多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 ...
- solr配置ik中文分词(二)
上一篇文章主要介绍了solr的安装与配置,这篇文章主要记录如何使用ik分词器对中文进行分词. 步骤: 1.下载ik分词jar包:ik-analyzer-solr5-5.x.jar. 2.将下载的jar ...
- 全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- solr建立pdf/word/excel索引的方法
PS: 本文假设你已经成功的搭建了一个Solr服务器步骤如下:(1)准备好一份Solr的源码,假设现在保存在c:\apache-solr-1.4.1\目录下(2)从https://issues.apa ...
随机推荐
- javascript的创建对象object.create()和属性检测hasOwnPrototype()和propertyIsEnumerable()
Object.create("参数1[,参数2]")是E5中提出的一种新的对象的创建方式. 第一个参数是要继承到新对象原型上的对象; 第二个参数是对象属性.这个参数可选,默认为fa ...
- user_add示例
#!/usr/bin/python3# -*- coding: utf-8 -*-# @Time : 2018/5/28 16:51# @File : use_test_add.py 数据 ...
- logger5步走
https://www.cnblogs.com/GGGGGGZX/p/9114378.html'''打印日志11/26/2017 10:44:21 PM bug 24 并写入文件example.log ...
- Java并发编程-Thread类的使用
在前面2篇文章分别讲到了线程和进程的由来.以及如何在Java中怎么创建线程和进程.今天我们来学习一下Thread类,在学习Thread类之前,先介绍与线程相关知识:线程的几种状态.上下文切换,然后接着 ...
- TCAM CAM 说明 原理 结构 Verilog 硬件实现
TCAM 三态内容地址查找存储器,CAM内容地址查找存储器.区别在于TCAM多了一级掩码功能,也就是说可以指定某几位是dont care.匹配的时候0,1都行的意思. 广泛应用于数据流处理领域,本文简 ...
- UNITY 复制对象后局部坐标和世界坐标的变化问题
void Start () { var pgo = transform.Find ("Button").gameObject; obtn = Instantiate (pgo); ...
- XMLHttpRequest对象的常用方法和属性(相当重要!!!)
方法:写在这里的为必选参数或者经常用到的可选参数 一, open(); 书上解释: 用于设置请求的目标url请求方法, 以及其他参数信息 个人理解: 发送请求的页面在不刷新的情况能将参数传给一个服务器 ...
- 16.3Sum Closest (Two-Pointers)
Given an array S of n integers, find three integers in S such that the sum is closest to a given num ...
- JAVA获取时间的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ...
- nvidia显卡驱动
http://blog.csdn.net/Monica__2012/article/details/75577522 $nvidia-smi