solr特点九:word(分词)
在Solr中配置中文分词IKAnalyzer
1、在配置文件schema.xml(位置{SOLR_HOME}/config/下),配置信息如下:
<!-- IKAnalyzer 中文分词-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" isMaxWordLength="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" isMaxWordLength="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
2、在IKAnalyzer相关的jar包(IKAnalyzer2012_u6.jar 本博客不提供下载)放在{SOLR_HOME}/lib下。
3、测试IKAnalyzer中文分词 效果:
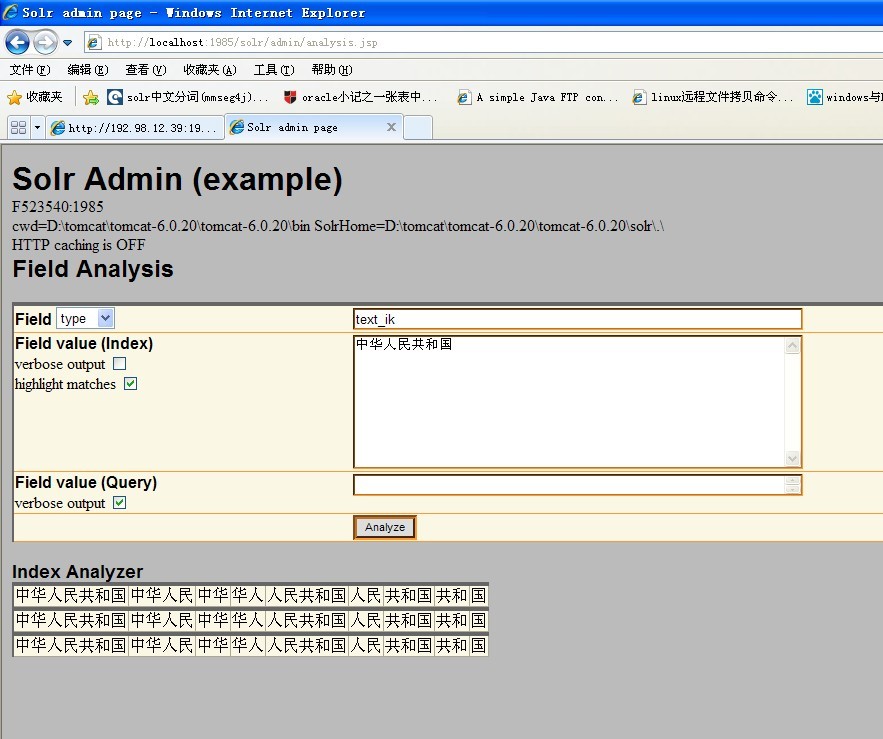
ikanlyzer分词效果还是不错的 ,通过配置可以扩展个人词典、自定义停顿词等。配置信息如下:
IKAnalyzer.cfg.xml配置文件
把stopword.dic和IKAnalyzer.cfg.xml复制到class根目录就可以启用停用词功能和扩展自己的词典
<?xmlversion="1.0"encoding="UTF-8"?>
<!DOCTYPEpropertiesSYSTEM"http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entrykey="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entrykey="ext_stopwords">stopword.dic;</entry>
</properties>
如果想在solr中使用IK来加载扩展词典,需要将以上的配置文件和词典扩展文件放在tomcat/webapps/solr/WEB-INF/classes下。同时,比如我的ext.dic中有以下内容:

那么在solr中分词效果便是:

solr特点九:word(分词)的更多相关文章
- Solr多核心及分词器(IK)配置
Solr多核心及分词器(IK)配置 多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索 ...
- Java——word分词·自定义词库
word: https://github.com/ysc/word word-1.3.1.jar 需要JDK8word-1.2.jar c语言给解析成了“语言”,自定义词库必须为UTF-8 程序一旦运 ...
- 全文检索引擎Solr系列——整合中文分词组件mmseg4j
默认Solr提供的分词组件对中文的支持是不友好的,比如:“VIM比作是编辑器之神”这个句子在索引的的时候,选择FieldType为”text_general”作为分词依据时,分词效果是: 它把每一个词 ...
- 在Solr中配置中文分词IKAnalyzer
李克华 云计算高级群: 292870151 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch 在Solr中配置中文分词IKAnalyzer 1.在配置文件schema.xml ...
- Solr整合Ansj中文分词器
Ansj的使用和相关资料下载参考:http://iamyida.iteye.com/blog/2220833 参考 http://www.cnblogs.com/luxh/p/5016894.html ...
- 三、Solr多核心及分词器(IK)配置
多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 ...
- solr配置ik中文分词(二)
上一篇文章主要介绍了solr的安装与配置,这篇文章主要记录如何使用ik分词器对中文进行分词. 步骤: 1.下载ik分词jar包:ik-analyzer-solr5-5.x.jar. 2.将下载的jar ...
- 全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- solr建立pdf/word/excel索引的方法
PS: 本文假设你已经成功的搭建了一个Solr服务器步骤如下:(1)准备好一份Solr的源码,假设现在保存在c:\apache-solr-1.4.1\目录下(2)从https://issues.apa ...
随机推荐
- LLMNR欺骗工具Responder
LLMNR(Link-Local Multicast Name Resolution,链路本地多播名称解析)协议是一种基于DNS包格式的协议.它可以将主机名解析为IPv4和IPv6的IP地址.这样用户 ...
- xmlns:app
Android自定义控件的属性,网上文章已经很多,之前看了也照着写了,其中有一个就是要自定义一个xml的命名空间后然后再给自定义属性赋值,后来发现不知道什么时候开始Android把这个改了,统一用 x ...
- Conv
folly/Conv.h folly/Conv.h is a one-stop-shop for converting values across types. Its main features a ...
- [POJ] Financial Management
Financial Management Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 182193 Accepted: ...
- springcloud(九) springboot Actuator + admin 监控
前一章讲的都是Feign项目(调用方)的监控.接下来讲的是服务提供方的监控 一.springboot actuator + springboot admin Spring Boot Admin 是一个 ...
- linux编程vim设置
linux环境下c网络编程vim编辑工具设置,包括自动缩进,tab键对齐等.
- Spring MVC 学习 之 - 拦截器
public class GlobalInterceptor implements HandlerInterceptor { public boolean preHandle(HttpServletR ...
- spring mvc 映射器和适配器
映射器和适配器 1.非注解的映射器和适配器 a. 入门程序中的单个映射 BeanNameUrlHandlerMapping SimpleControllerHandlerAdapter b.另一种ma ...
- 【331】python 下载文件:wget / urllib
参考:python下载文件的三种方法(去掉-) 方法一:wget import wget, os # 设置下载路径 os.chdir(r"D:/tmp") url="ht ...
- Glow Shader
[Glow Shader] Glow Shader基于BlurShader来实现.总的来说分为2步: 1.利用BlurShader渲染出BlurTexture. 2.将BlurTexture与SrcT ...