性能调优的本质、Spark资源使用原理和调优要点分析
本课主题
- 大数据性能调优的本质
- Spark 性能调优要点分析
- Spark 资源使用原理流程
- Spark 资源调优最佳实战
- Spark 更高性能的算子
引言
我们谈大数据性能调优,到底在谈什么,它的本质是什么,以及 Spark 在性能调优部份的要点,这两点让在进入性能调优之前都是一个至关重要的问题,它的本质限制了我们调优到底要达到一个什么样的目标或者说我们是从什么本源上进行调优。希望这篇文章能为读者带出以下的启发:
- 了解大数据性能调优的本质
- 了解 Spark 性能调优要点分析
- 了解 Spark 在资源优化上的一些参数调优
- 了解 Spark 的一些比较高效的 RDD 操作算子
大数据性能调优的本质
编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论做什么类型的编程,最终思考的都是硬件方面的问题!最终思考都是在一秒、一毫秒、甚至一纳秒到底是如何运行的,并且基于此进行算法实现和性能调优,最后都是回到了硬件!
在大数据性能的调优,它的本质是硬件的调优!即基于 CPU(计算)、Memory(存储)、IO-Disk/ Network(数据交互) 基础上构建算法和性能调优!我们在计算的时候,数据肯定是存储在内存中的。磁盘IO怎么去处理和网络IO怎么去优化。
Spark 性能调优要点分析
在大数据性能本质的思路上,我们应该需要在那些方面进行调优呢?比如:
- 并行度
- 压缩
- 序例化
- 数据倾斜
- JVM调优 (例如 JVM 数据结构化优化)
- 内存调优
- Task性能调优 (例如包含 Mapper 和 Reducer 两种类型的 Task)
- Shuffle 网络调优 (例如小文件合并)
- RDD 算子调优 (例如 RDD 复用、自定义 RDD)
- 数据本地性
- 容错调优
- 参数调优
大数据最怕的就是数据本地性(内存中)和数据倾斜或者叫数据分布不均衡、数据转输,这个是所有分布式系统的问题!数据倾斜其实是跟你的业务紧密相关的。所以调优 Spark 的重点一定是在数据本地性和数据倾斜入手。
- 资源分配和使用:你能够申请多少资源以及如何最优化的使用计算资源
- 关发调优:如何基于 Spark 框架内核原理和运行机制最优化的实现代码功能
- Shuffle调优:分布式系统必然面临的杀手级别的问题
- 数据倾斜:分布式系统业务本身有数据倾斜
Spark 资源使用原理流程
这是一张来至于官方的经典资源使用流程图,这里有三大组件,第一部份是 Driver 部份,第二就是具体处理数据的部份,第三就是资源管理部份。这一张图中间有一个过程,这表示在程序运行之前向资源管理器申请资源。在实际生产环境中,Cluster Manager 一般都是 Yarn 的 ResourceManager,Driver 会向 ResourceManager 申请计算资源(一般情况下都是在发生计算之前一次性进行申请请求),分配的计算资源就是 CPU Core 和 Memory,我们具体的 Job 里的 Task 就是基于这些分配的内存和 Cores 构建的线程池来运行 Tasks 的。
[下图是 Spark 官方网站上的经典Spark架框图]
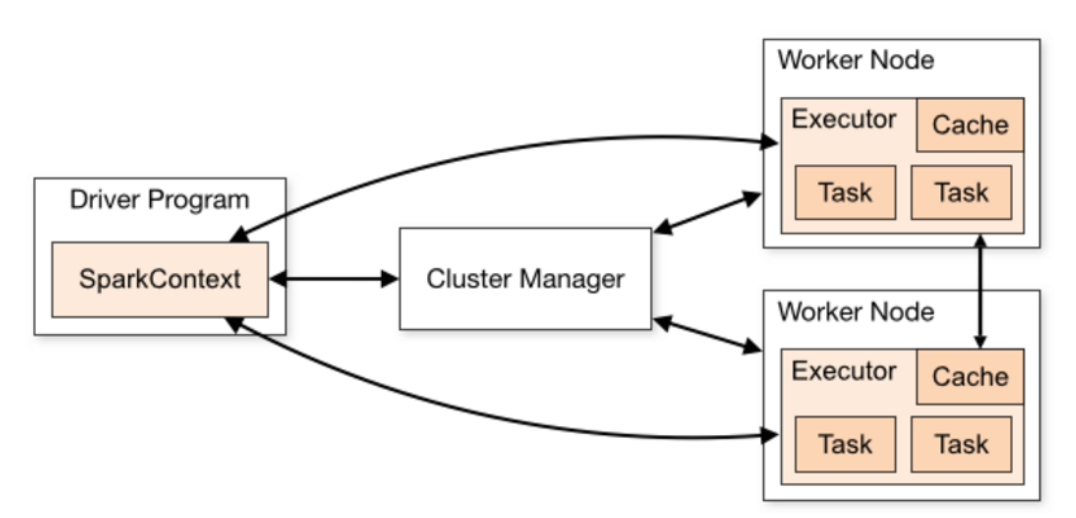
当然在 Task 运行的过程中会大量的消耗内存,而Task又分为 Mapper 和 Reducer 两种不同类型的 Task,也就是 ShuffleMapTask 和 ResultTask 两种类型,这类有一个很关建的调优点就是如何对内存进行使用。在一个 Task 运行的时候,默应会占用 Executor 总内存的 20%,Shuffle 拉取数据和进行聚合操作等占用了 20% 的内存,剩下的大概有 60% 是用于 RDD 持久化 (例如 cache 数据到内存),Task 在运行时候是跑在 Core 上的,比较理想的是有足够的 Core 同时数据分布比较均匀,这个时候往往能够充分利用集群的资源。
核心调优参数如下:
|
1
2
3
4
5
6
7
|
num-executorsexecutor-memoryexecutor-coresdriver-memoryspark.default.parallelizmspark.storage.memoryFractionspark.shuffle.memoryFraction |
- num-executors:该参数一定会被设置,Yarn 会按照 Driver 的申请去最终为当前的 Application 生产指定个数的 Executors,实际生产环境下应该分配80个左右 Executors 会比较合适呢。
- executor-memory:这个定义了每个 Executor 的内存,它与 JVM OOM 紧密相关,很多时候甚至决定了 Spark 运行的性能。实际生产环境下建义是 8G 左右,很多时候 Spark 运行在 Yarn 上,内存占用量不要超过 Yarn 的内存资源的 50%。
- executor-cores:决定了在 Executors 中能够并行执行的 Tasks 的个数。实际生产环境下应该分配4个左右,一般情况下不要超过 Yarn 队列中 Cores 总数量的 50%。
- driver-memory:默应是 1G
- spark.default.parallelizm:并行度问题,如果不设置这个参数,Spark 会跟据 HDFS 中 Block 的个数去设置这一个数量,原理是默应每个 Block 会对应一个 Task,默应情况下,如果数据量不是太多就不可以充份利用 executor 设置的资源,就会浪费了资源。建义设置为 100个,最好 700个左右。Spark官方的建义是每一个 Core 负责 2-3 个 Task。
- spark.storage.memoryFraction:默应占用 60%,如果计算比较依赖于历史数据则可以调高该参数,当如果计算比较依赖 Shuffle 的话则需要降低该比例。
- spark.shuffle.memoryFraction:默应占用 20%,如果计算比较依赖 Shuffle 的话则需要调高该比例。
Spark 更高性能的算子
Shuffle 分开两部份,一个是 Mapper 端的Shuffle,另外一个就是 Reducer端的 Shuffle,性能调优有一个很重要的总结就是尽量不使用 Shuffle 类的算子,我们能避免就尽量避免,因为一般进行 Shuffle 的时候,它会把集群中多个节点上的同一个 Key 汇聚在同一个节点上,例如 reduceByKey。然后会优先把结果数据放在内存中,但如果内存不够的话会放到磁盘上。Shuffle 在进行数据抓取之前,为了整个集群的稳定性,它的 Mapper 端会把数据写到本地文件系统。这可能会导致大量磁盘文件的操作。如何避免Shuffle可以考虑以下:
- 采用 Map 端的 Join (RDD1 + RDD2 )先把一个 RDD1的数据收集过来,然后再通过 sc.broadcast( ) 把数据广播到 Executor 上;
- 如果无法避免Shuffle,退而求其次就是需要更多的机器参与 Shuffle 的过程,这个时候就需要充份地利用 Mapper 端和 Reducer 端机制的计算资源,尽量使用 Mapper 端的 Aggregrate 功能,e.g. aggregrateByKey 操作。相对于 groupByKey而言,更倾向于使用 reduceByKey( ) 和 aggregrateByKey( ) 来取代 groupByKey,因为 groupByKey 不会进行 Mapper 端的操作,aggregrateByKey 可以给予更多的控制。
- 如果一批一批地处理数据来说,可以使用 mapPartitions( ),但这个算子有可能会出现 OOM 机会,它会进行 JVM 的 GC 操作!
- 如果进行批量插入数据到数据库的话,建义采用foreachPartition( ) 。
- 因为我们不希望有太多的数据碎片,所以能批量处理就尽量批量处理,你可以调用 coalesce( ) ,把一个更多的并行度的分片变得更少,假设有一万个数据分片,想把它变得一百个,就可以使用 coalesce( )方法,一般在 filter( ) 算子之后就会用 coalesce( ),这样可以节省资源。
- 官方建义使用 repartitionAndSortWithPartitions( );
- 数据进行复用时一般都会进行持久化 persisit( );
- 建义使用 mapPartitionWithIndex( );
- 也建义使用 tree 开头的算子,比如说 treeReduce( ) 和 treeAggregrate( );
总结
大数据必然要思考的核心性能问题不外乎 CPU 计算、内存管理、磁盘和网络IO操作,这是无可避免的,但是可以基于这个基础上进行优化,思考如何最优化的使用计算资源,思考如何在优化代码,在代码层面上防避坠入性能弱点;思考如何减少网络传输和思考如何最大程度的实现数据分布均衡。
在资源管理调优方面可以设置一些参数,比如num-executors、executor-memory、executor-cores、driver-memory、spark.default.parallelizm、spark.storage.memoryFraction、spark.shuffle.memoryFraction
Shuffle 所导致的问题是所有分布式系统都无法避免的,但是如何把 Shuffle 所带来的性能问题减少最低,是一个很可靠的优化方向。Shuffle 的第一阶段即Mapper端在默应情况下会写到本地,而reducer通过网络抓取的同一个 Key 在不同节点上都把它抓取过来,内存可能不够,不够的话就写到磁盘中,这可能会导致大量磁盘文件的操作。在实际编程的时候,可以用一些比较高效的RDD算子,例如 reduceByKey、aggregrateByKey、coalesce、foreachPartition、repartitionAndSortWithPartitions。
性能调优的本质、Spark资源使用原理和调优要点分析的更多相关文章
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析
转载:http://www.cnblogs.com/jcchoiling/p/6440709.html 一.大数据性能调优的本质 编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论 ...
- spark 资源参数调优
资源参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了.所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使 ...
- 【Spark深入学习 -14】Spark应用经验与程序调优
----本节内容------- 1.遗留问题解答 2.Spark调优初体验 2.1 利用WebUI分析程序瓶颈 2.2 设置合适的资源 2.3 调整任务的并发度 2.4 修改存储格式 3.Spark调 ...
- Spark企业级应用开发和调优
1.Spark企业级应用开发和调优 Spark项目编程优化历程记录,主要介绍了Spark企业级别的开发过程中面临的问题和调优方法.包含合理分配分片,避免计算中间结果(大数据量)的collect,合理使 ...
- SQL运行内幕:从执行原理看调优的本质
相信大家看过无数的MySQL调优经验贴了,会告诉你各种调优手段,如: 避免 select *: join字段走索引: 慎用in和not in,用exists取代in: 避免在where子句中对字段进行 ...
- JVM性能调优的6大步骤,及关键调优参数详解
JVM性能调优方法和步骤1.监控GC的状态2.生成堆的dump文件3.分析dump文件4.分析结果,判断是否需要优化5.调整GC类型和内存分配6.不断分析和调整JVM调优参数参考 对JVM内存的系统级 ...
- 直通BAT必考题系列:JVM性能调优的6大步骤,及关键调优参数详解
JVM内存调优 对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数. 1.Full GC 会对整个堆进行整理,包括Young.Tenured和Perm.Full GC因为需要对 ...
- 一文读懂Java GC原理和调优
概述 本文介绍GC基础原理和理论,GC调优方法思路和方法,基于Hotspot jdk1.8,学习之后将了解如何对生产系统出现的GC问题进行排查解决 阅读时长约30分钟,内容主要如下: GC基础原理,涉 ...
随机推荐
- nodejs学习笔记二(get请求、post请求、 querystring模块,url模块)
请求数据 前台:form.ajax.jsonp 后台:接受请求并返回响应数据 前台<= http协议 =>后台 常用的请求的方式: 1.GET 数据在url ...
- MySQL---5、可视化工具Navicat for MySQL安装配置
一.安装文件包下载 Navicat for MySQL 安装软件和破解补丁: 链接:https://pan.baidu.com/s/1oKcErok_Ijm0CY9UjNMrnA 密码:4xb1 ...
- 初识JSP,第一天
1.什么JSP java Server Page java 服务端的页面,它和servlet 一样可以提供动态的html 响应. 不同的是 servlet 以 java 代码 为主 jsp 以html ...
- c# 根据父节点id,找到所有的子节点数据
转自:https://blog.csdn.net/q107770540/article/details/7708418 查的是表 Model_info中父节点为p_id时找到所有的子节点的集合 //通 ...
- 【SSH网上商城项目实战03】使用EasyUI搭建后台页面框架
转自:https://blog.csdn.net/eson_15/article/details/51312490 前面两节,我们整合了SSH并且抽取了service和action部分的接口,可以说基 ...
- HDU 4248 A Famous Stone Collector 组合数学dp ****
A Famous Stone Collector Time Limit: 30000/15000 MS (Java/Others) Memory Limit: 32768/32768 K (Ja ...
- RFC1939 POP3协议 中文版 (转载)
1.简介 对于在网络上的比较小的结点,支持消息传输系统(MTS)是不实际的.例如,一台工作站可能不具有充足的资源允许SMTP服务器和相当的本地邮件传送系统保持序驻留,并持续运行.同样的,将一台个人 ...
- Java与C++区别:重载(Overloading)
Java中一个类的函数重载可以在本类中的函数和来自父类中的函数之间进行,而C++类中的函数重载只能是本类中的(即不包括来自父类的函数),这是他们一个非常重要的区别.在其他方面的要求都是一致的,即要求函 ...
- sql: Oracle 11g create procedure
CREATE OR REPLACE PROCEDURE proc_Insert_BookKindList ( temTypeName nvarchar2, temParent int ) AS nco ...
- csharp:datagridview enter Half Width and Full Width characters
/// <summary> /// 全角 /// </summary> /// <param name="unicodeString">< ...