字符编码:ASCII,Unicode,UTF-8
1.ASCII码
美国制定的一套字符编码,对英语字符和二进制位之间的关系,做了统一规定。
ASCII码一共规定了128个字符(包括32个不能打印出来的控制符号)的编码,占用一个字节,字节的最前面1位统一为0,其实只占用了后面7位
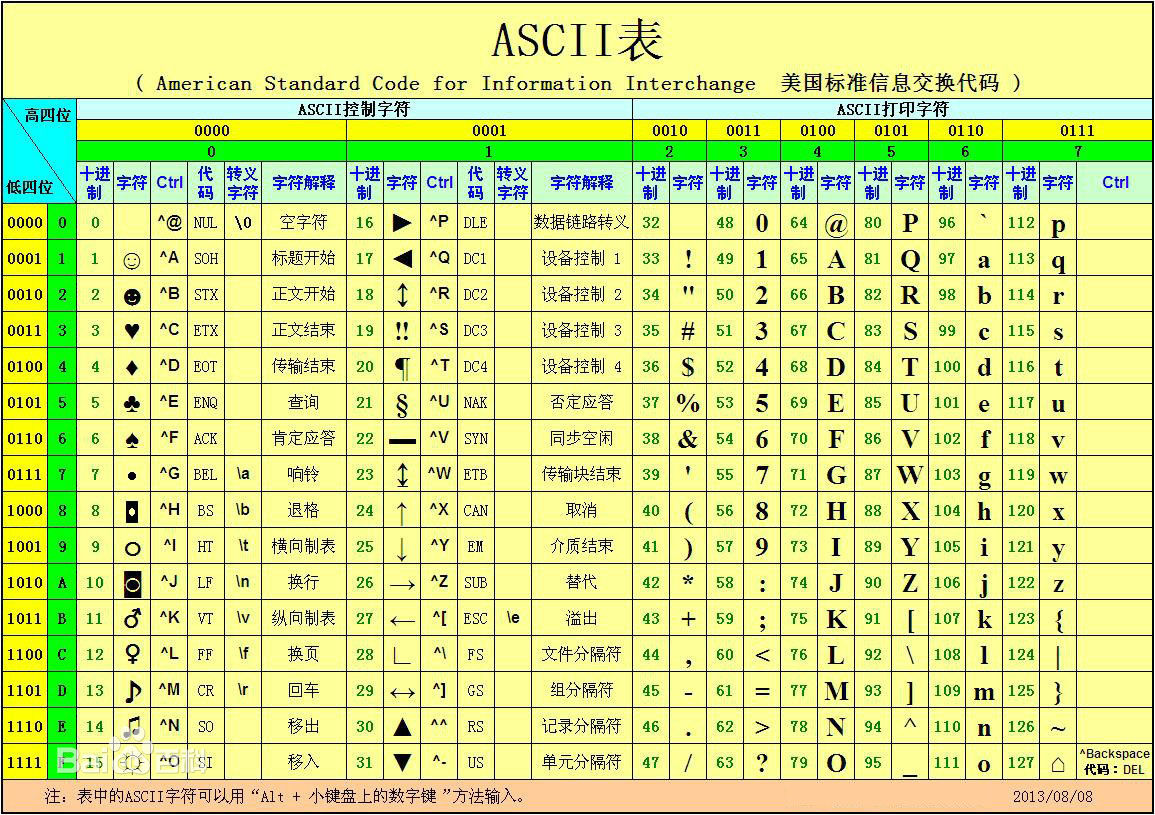
2.Unicode
英语用128个符号编码就够了,但其他语言是不够的。于是产生了多种编码方式。同一个二进制数组也可以被解释成不同的符号。因此,解读一个文件必须知道它的编码方式,否则就会出现乱码。
如果有一种编码,将世界上所有的符号纳入其中,每一个符号给予一个独一无二的编码,那么乱码问题就会消失,这就是Unicode
Unicode规定了符号的二进制代码,但没有规定这个二进制代码如何存储。
比如,汉子“严”的unicode是十六进制数4E25,可以看出这个符号的表示至少需要2个字节,表示其他更大的符号,可能需要3个字节,4个字节或更多。
那么就存在两个问题,
1)如何区别Unicode和ASCII?
计算机是怎么知道三个字节表示一个符号,还是分别表示三个符号
2)英文字母用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,对于存储来说是极大的浪费
3.UTF-8
UTF-8是Unicode的实现方式之一。
编码规则有两条:
1)对于单字节的符号,字节的第一位是0,后面7位是这个符号的unicode码。对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
解读UTF-8编码很简单,如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
以汉字“严”为例,UTF-8编码如下:
已知“严”的unicode是4E25(100111000100101),根据上表,4E25处在第三行的范围内(0000 0800-0000 FFFF),因此,“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0.这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
4.Unicode和UTF-8之间的转换
由上例,“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者不一样,但可以相互转换。
5.Little endian和Big endian
以汉字“严”为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储时,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
计算机是怎么知道某一个文件到底采用哪一种方式编码的呢?
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做“零宽度非换行空格”(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正还是两个字节,而且FF比FE大1
如果一个文本文件的头两个字节是FEFF,表示该文件采用大头方式;如果头两个字节是FFFE,表示该文件采用小头方式。
6.实例
打开记事本程序Notepad.exe,新建一个文本文件,内容就是一个“严”字,分别用ANSI,Unicode,Unicode bigendian和UTF-8编码方式保存。
然后,用文本编辑软件UltraEdit的“十六进制功能”,观察该文件的内部编码方式。
1)ANSI:文件的编码是两个字节“D1 CF”,这正是“严”的GB2312编码。
2)Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”表明是小头方式存储,真正的编码是4E25
3)Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE FF”表明是大头存储方式
4)UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”是严的具体编码,存储顺序和编码顺序是一致的
参考资料:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
字符编码:ASCII,Unicode,UTF-8的更多相关文章
- 字符编码 ASCII,Unicode和UTF-8的关系
转自:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143166410626 ...
- 字符编码 ASCII unicode UTF-8
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(b ...
- 彻底搞清楚字符编码: ASCII, ISO_8859, GB2312,UCS, Unicode, Utf-8
彻底搞清楚字符编码: ASCII, ISO_8859, GB2312,UCS, Unicode, U 1.ASCII: 0-127(128-255未使用),美国标准 2.IS0-8859-1(lati ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 字符编码 ASCII,Unicode 和 UTF-8 概念扫盲
今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步搞清楚. 下面就是我的笔记,主要用来整理自己的思 ...
- 字符编码 ASCII、Unicode和UTF-8的关系
摘抄自廖雪峰 教程 字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机 ...
- 字符编码ASCII,Unicode 和 UTF-8
一直对编码的概念很模糊,今天抽空突然想了解下,就找到了这个文章,看完真的豁然开朗,必须感谢阮一峰先生. 一.ASCII 码 我们知道,计算机内部,所有信息最终都是一个二进制值.每一个二进制位(bit) ...
- Java 字符编码 ASCII、Unicode、UTF-8、代码点和代码单元
1 ASCII码 统一规定英语字符与二进制位之间的关系.ASCII码一共规定了128个字符的编码.例如,空格“SPACE”是32(二进制00100000),大写字母A是65(二进制01000001). ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端(zz)
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 字符编码ASCII、Unicode、GB
计算机的存储都是二进制的,那么我们平时看到的各种字符都需要通过按照一定的格式转换成为二进制才能在被计算机识别与处理.这个过程便成为编码.常见的编码方式有ASCII.Unicode.GB2312等. 1 ...
随机推荐
- Linux 如何判断自己的服务器是否被入侵
如何判断自己的服务器是否被入侵了呢?仅仅靠两只手是不够的,但两只手也能起到一些作用,我们先来看看UNIX系统上一些入侵检测方法,以LINUX和solaris为例. 1.检查系统密码文件 首先从明显的入 ...
- while(cin>>word)时的结束方法
有一个要注意的地方,以前不理解在while里面用cin >> val是什么意思,用这个当条件的话,通过检测其流的状态来判断结束: (1)若流是有效的,即流未遇到错误,那么检测成功: (2) ...
- 网速变慢解决方法.Tracert与PathPing(转)
Tracert命令与PathPing命令你常用吗: 前段时间本网吧网速不太正常.每晚8点后到11点之间网速爆慢.其余时间则正常.在8~11点间PING电信DNS TIME值要100多MS以上,但PIN ...
- 非IT人士的云栖酱油之行 (程序猿迷妹的云栖之行)
摘要: 熟悉我的人都知道,我是一个贪玩儿且不学无术的姑娘,对于互联网我也是知之甚少:这次去到杭州参加阿里巴巴集团主办的为期4天的科技大会也是很例外:但是不得不说这次的会议真是让我很震惊.今天我就和大家 ...
- 开源APP 源码
作者:wjh2005链接:http://www.zhihu.com/question/28518265/answer/88750562来源:知乎著作权归作者所有,转载请联系作者获得授权. 1. Cod ...
- python标准日志模块logging的使用方法
参考地址 最近写一个爬虫系统,需要用到python的日志记录模块,于是便学习了一下.python的标准库里的日志系统从Python2.3开始支持.只要import logging这个模块即可使用.如果 ...
- js replaceChild
//父亲元素.replaceChild(新,旧) 1 <ul id="city"> <li id="bj">北京</li> ...
- HDUOJ-----Difference Between Primes
Difference Between Primes Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Jav ...
- web development blog(转)
Top 10 jQuery Mobile Code Snippets that you need to know jQuery Mobile is a framework for mobile web ...
- linux下判断文件和目录是否存在
1.前言 工作中涉及到文件系统,有时候需要判断文件和目录是否存在.我结合APUE第四章文件和目录,总结一下如何正确判断文件和目录是否存在,方便以后查询. 2.stat系列函数 stat函数用来返回与文 ...