spark中资源调度任务调度
在spark的资源调度中
1、集群启动worker向master汇报资源情况
2、Client向集群提交app,向master注册一个driver(需要多少core、memery),启动一个driver
3、Driver将当前app注册给master,(当前app需要多少资源),并请求启动对应的Executor
4、driver分发任务给Executor的Thread Pool。
根据Spark源码可以知道:
1、一个worker默认为一个Application启动一个Executor
2、启动的Executor默认占用这个worker的全部资源
3、如果要在一个worker上启动多个Executor,(前提:在内存充足的情况下)需要设置--executor-cores num 参数
宽依赖、窄依赖
窄依赖:父RDD与子RDD,partition之间是一对一的关系,或者多对一的关系。
宽依赖:父RDD与子RDD,partition之间是一对多,多对多的关系。
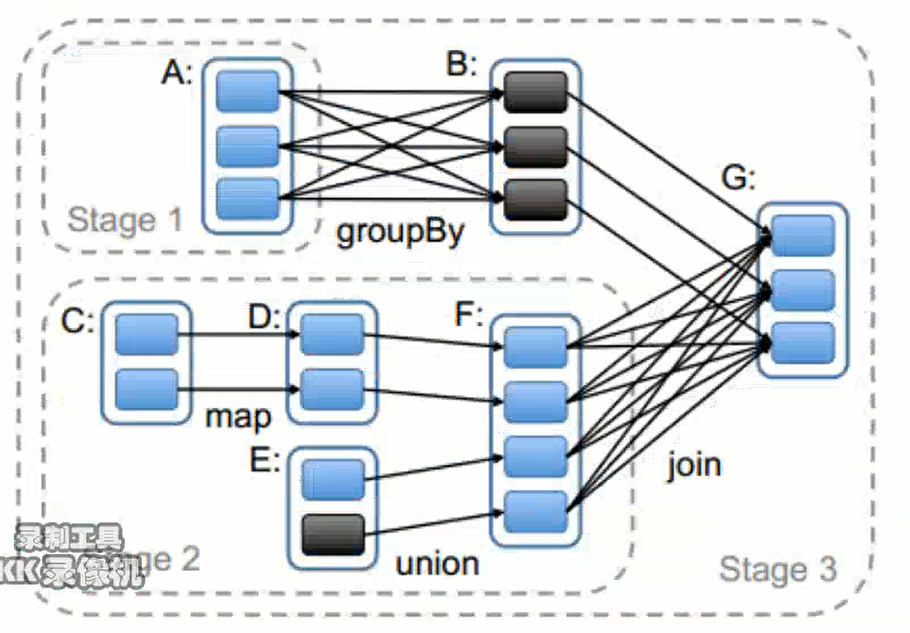
注意:
1、Stage的划分是根据宽窄依赖进行的,Satge与Satge之间是根据宽依赖划分的,每个Satge内部是窄依赖的。
2、窄依赖内部父RDD与子RDD之间的Partition是一对一的关系。
3、一个Satge内部是由多个RDD组成,在运行的过程中,会形成一个个并行的task,每个task形成一个pipeline。
4、在pipeline的运行过程中,数据不会落地,只有在右侧的join阶段的shuffle write才会数据落地。
Spark任务调度
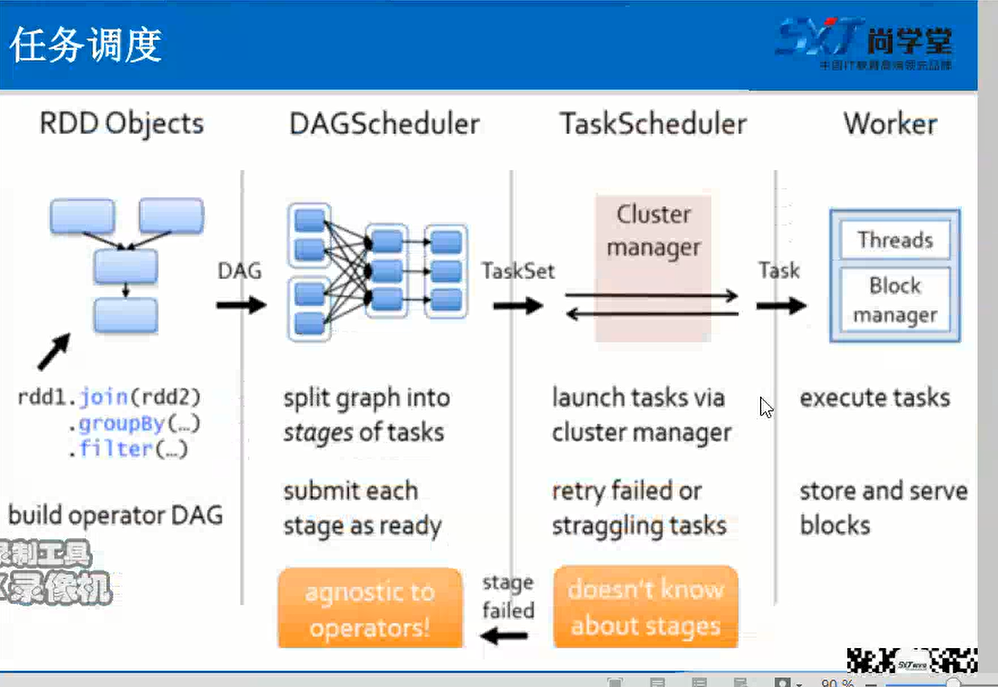
Spark的任务调度过程
RDD之间有依赖关系,所以可以根据依赖关系倒推回去,寻找到RDD的所有依赖关系,形成DAG(有向无环图)
由RDD Object将DAG传递给DAGScheduler
DAGScheduler会根据宽依赖将有向无环图划分为一个个的Satge
DAGScheduler将taskSet传递给TaskScheduler(实际上taskScheduler和Stage是相同的,只是叫法不同)
TaskScheduler会将TaskSet划分为一个个的task,传递给worker
worker会将task放入反序列化放入自己的线程池中,进行执行。
注意:
默认情况下TaskScheduler会对计算失败的task重试3次
默认情况下DAGScheduler会对计算失败的Stage重试4次
一共重试3*4=12次
未避免在对数据库操作时,操作一半失败,重试导致数据重复插入问题,可以采取两个办法
(1)设置主键
(2)关闭推测执行(默认是关闭的)
特殊情况:
如果task在执行的过程中报错shuffle file not find错误信息,此时TaskScheduler是不负责重试的,直接抛出对应的Satge运行失败,由DAGScheduler负责重试,如果DAGScheduler4次重试失败,则直接显示Job运行失败。
spark中资源调度任务调度的更多相关文章
- Spark中资源调度和任务调度
Spark比MR快的原因 1.Spark基于内存的计算 2.粗粒度资源调度 3.DAG有向无环图:可以根据宽窄依赖划分出可以并行计算的task 细粒度资源调度 MR是属于细粒度资源调度 优点:每个ta ...
- 【Spark篇】---Spark中资源和任务调度源码分析与资源配置参数应用
一.前述 Spark中资源调度是一个非常核心的模块,尤其对于我们提交参数来说,需要具体到某些配置,所以提交配置的参数于源码一一对应,掌握此节对于Spark在任务执行过程中的资源分配会更上一层楼.由于源 ...
- Spark Core_资源调度与任务调度详述
转载请标明出处http://www.cnblogs.com/haozhengfei/p/0593214ae0a5395d1411395169eaabfa.html Spark Core_资源调度与任务 ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要: Tachyon是一种分布式文件系统,能够借助集群计算框架使得数据以内存的速度进行共享.当今的缓存技术优化了read过程,可是,write过程由于须要容错机制,就须要通过网络或者 ...
- Spark中资源与任务的关系
在介绍Spark中的任务和资源之前先解释几个名词: Dirver Program:运行Application的main函数(用户提交的jar包中的main函数)并新建SparkContext实例的程序 ...
- Spark中的术语图解总结
参考:http://www.raincent.com/content-85-11052-1.html 1.Application:Spark应用程序 指的是用户编写的Spark应用程序,包含了Driv ...
- Spark中常用工具类Utils的简明介绍
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
随机推荐
- Python爬虫进阶一之爬虫框架概述
综述 爬虫入门之后,我们有两条路可以走. 一个是继续深入学习,以及关于设计模式的一些知识,强化Python相关知识,自己动手造轮子,继续为自己的爬虫增加分布式,多线程等功能扩展.另一条路便是学习一些优 ...
- labview使用场景
测试测量:LABVIEW [6] 最初就是为测试测量而设计的,因而测试测量也就是现在LABVIEW最广泛的应用领域.经过多年的发展,LABVIEW在测试测量领域获得了广泛的承认.至今,大多数主流的测 ...
- UX最佳演练:交互驱动连接
以下内容由Mockplus团队翻译整理,仅供学习交流,Mockplus是更快更简单的原型设计工具 我们开展了最佳用户体验演练的系列活动,其涵盖了模式和格式塔理论是如何帮助我们设计便于用户理解的界面.如 ...
- 中介者模式c#(媒婆版)
using System;using System.Collections.Generic;using System.Linq;using System.Text; namespace 中介者模式{ ...
- Android Studio真机测试失败-----''No target device found"
手机成功连接电脑,并且手机已经设置了开发者模式,但是启动真机还是失败,最后发现居然自己没有配置android sdk的环境变量,配置之后 如果还是不能启动,点击android studio上的tool ...
- 友盟统计小白教程:创建应用,申请appkey
上回书讲到,我们已经和一个靠谱的人选择一个靠谱的统计平台注册了一个帐号,下面就该创建一个应用了. 介绍一个基础知识: appkey:友盟识别app的唯一标识,目前友盟平台上超过500000款App,每 ...
- 八种主流NoSQL数据库系统对比(转)
出处:http://database.51cto.com/art/201109/293029.htm 虽然SQL数据库是非常有用的工具,但经历了15年的一支独秀之后垄断即将被打破.这只是时间问题:被迫 ...
- centos搭建本地yum源,
比如将文件夹:/opt/mir/这个文件夹做成本地源: 1.在/etc/yum.repos.d/目录下新建一个.repo文件,比如mir-base.repo,在里面加入如下: [local]name= ...
- (转)SQL Server内存遭遇操作系统进程压榨案例
原文地址:http://www.cnblogs.com/zc_0101/p/3592259.html 场景: 最近一台DB服务器偶尔出现CPU报警,我的邮件报警阈(请读yù)值设置的是15%,开始时没 ...
- MySQL数据库Query性能定位
1.SQL前面加 EXPLAIN 定位到sql级别 各个属性的含义 id select查询的序列号 select_type select查询的类型,主要是区别普通查询和联合查询.子查询之类的复杂查询. ...