spark中资源调度任务调度
在spark的资源调度中
1、集群启动worker向master汇报资源情况
2、Client向集群提交app,向master注册一个driver(需要多少core、memery),启动一个driver
3、Driver将当前app注册给master,(当前app需要多少资源),并请求启动对应的Executor
4、driver分发任务给Executor的Thread Pool。
根据Spark源码可以知道:
1、一个worker默认为一个Application启动一个Executor
2、启动的Executor默认占用这个worker的全部资源
3、如果要在一个worker上启动多个Executor,(前提:在内存充足的情况下)需要设置--executor-cores num 参数
宽依赖、窄依赖
窄依赖:父RDD与子RDD,partition之间是一对一的关系,或者多对一的关系。
宽依赖:父RDD与子RDD,partition之间是一对多,多对多的关系。
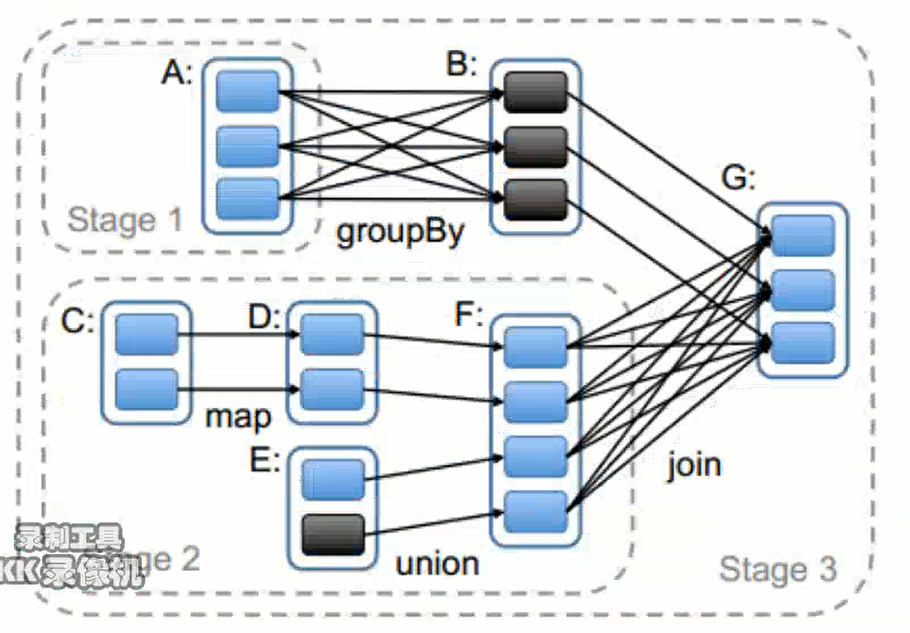
注意:
1、Stage的划分是根据宽窄依赖进行的,Satge与Satge之间是根据宽依赖划分的,每个Satge内部是窄依赖的。
2、窄依赖内部父RDD与子RDD之间的Partition是一对一的关系。
3、一个Satge内部是由多个RDD组成,在运行的过程中,会形成一个个并行的task,每个task形成一个pipeline。
4、在pipeline的运行过程中,数据不会落地,只有在右侧的join阶段的shuffle write才会数据落地。
Spark任务调度
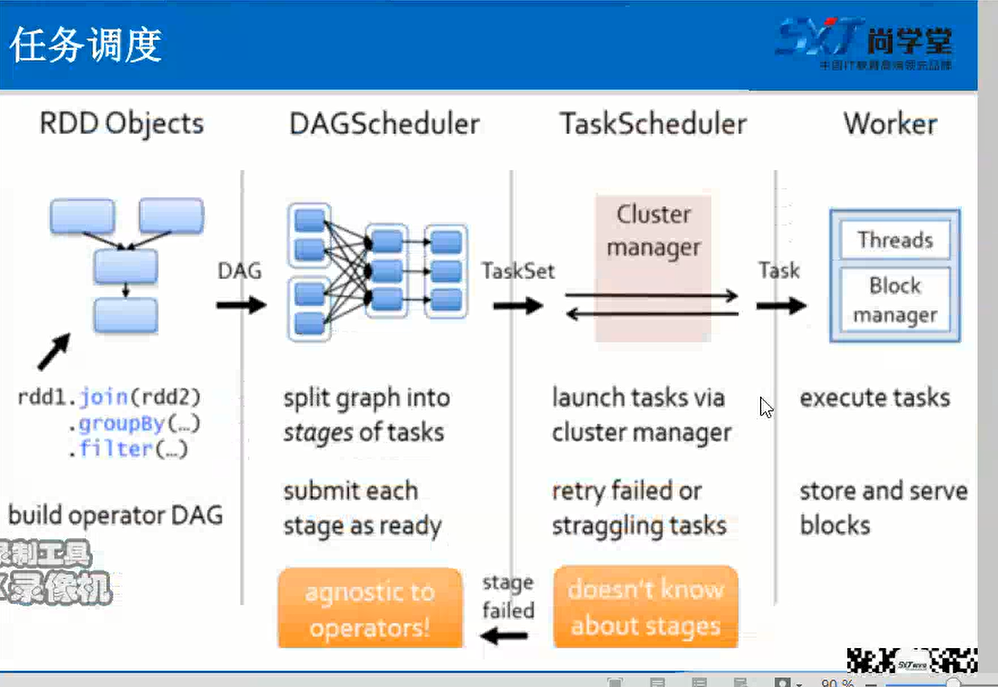
Spark的任务调度过程
RDD之间有依赖关系,所以可以根据依赖关系倒推回去,寻找到RDD的所有依赖关系,形成DAG(有向无环图)
由RDD Object将DAG传递给DAGScheduler
DAGScheduler会根据宽依赖将有向无环图划分为一个个的Satge
DAGScheduler将taskSet传递给TaskScheduler(实际上taskScheduler和Stage是相同的,只是叫法不同)
TaskScheduler会将TaskSet划分为一个个的task,传递给worker
worker会将task放入反序列化放入自己的线程池中,进行执行。
注意:
默认情况下TaskScheduler会对计算失败的task重试3次
默认情况下DAGScheduler会对计算失败的Stage重试4次
一共重试3*4=12次
未避免在对数据库操作时,操作一半失败,重试导致数据重复插入问题,可以采取两个办法
(1)设置主键
(2)关闭推测执行(默认是关闭的)
特殊情况:
如果task在执行的过程中报错shuffle file not find错误信息,此时TaskScheduler是不负责重试的,直接抛出对应的Satge运行失败,由DAGScheduler负责重试,如果DAGScheduler4次重试失败,则直接显示Job运行失败。
spark中资源调度任务调度的更多相关文章
- Spark中资源调度和任务调度
Spark比MR快的原因 1.Spark基于内存的计算 2.粗粒度资源调度 3.DAG有向无环图:可以根据宽窄依赖划分出可以并行计算的task 细粒度资源调度 MR是属于细粒度资源调度 优点:每个ta ...
- 【Spark篇】---Spark中资源和任务调度源码分析与资源配置参数应用
一.前述 Spark中资源调度是一个非常核心的模块,尤其对于我们提交参数来说,需要具体到某些配置,所以提交配置的参数于源码一一对应,掌握此节对于Spark在任务执行过程中的资源分配会更上一层楼.由于源 ...
- Spark Core_资源调度与任务调度详述
转载请标明出处http://www.cnblogs.com/haozhengfei/p/0593214ae0a5395d1411395169eaabfa.html Spark Core_资源调度与任务 ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要: Tachyon是一种分布式文件系统,能够借助集群计算框架使得数据以内存的速度进行共享.当今的缓存技术优化了read过程,可是,write过程由于须要容错机制,就须要通过网络或者 ...
- Spark中资源与任务的关系
在介绍Spark中的任务和资源之前先解释几个名词: Dirver Program:运行Application的main函数(用户提交的jar包中的main函数)并新建SparkContext实例的程序 ...
- Spark中的术语图解总结
参考:http://www.raincent.com/content-85-11052-1.html 1.Application:Spark应用程序 指的是用户编写的Spark应用程序,包含了Driv ...
- Spark中常用工具类Utils的简明介绍
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
随机推荐
- Qt的安装和使用中的常见问题(详细版)
对于太长不看的朋友,可参考Qt的安装和使用中的常见问题(简略版). 目录 1.引入 2.Qt简介 3.Qt版本 3.1 查看安装的Qt版本 3.2 查看当前项目使用的Qt版本 3.3 查看当前项目使用 ...
- .NET基础 (19)多线程
多线程编程的基本概念1 请解释操作系统层面上的线程和进程2 多线程程序在操作系统里是并行执行的吗3 什么是纤程 .NET中的多线程1 如何在.NET程序中手动控制多个线程2 如何使用.NET的线程池3 ...
- Codeforces761B Dasha and friends 2017-02-05 23:34 162人阅读 评论(0) 收藏
B. Dasha and friends time limit per test 2 seconds memory limit per test 256 megabytes input standar ...
- Spring+shiro配置JSP权限标签+角色标签+缓存
Spring+shiro,让shiro管理所有权限,特别是实现jsp页面中的权限点标签,每次打开页面需要读取数据库看权限,这样的方式对数据库压力太大,使用缓存就能极大减少数据库访问量. 下面记录下sh ...
- MySQL—练习2
参考链接:https://www.cnblogs.com/edisonchou/p/3878135.html 感谢博主 https://blog.csdn.net/flycat296/articl ...
- ERROR Function not available to this responsibility.Change responsibilities or contact your System Administrator.
APPLIES TO: Navigation: Help > Diagnostics > Custom Code > Personalize or Help > Diag ...
- memory leak-----tomcat日志warn
web应用借助于结构:spring mvc + quartz结构,部署到tomcat容器时,shutdown时的error信息: appears to have started a thread na ...
- HTML5和App之争论
2013了,移动互联网火了几年,我们也看清了原生App的真面目,App很多很好,但是盈利很难,这时我们不得不把目光重新转向HTML5. 简单地说,HTML5是一个新技术,可以让开发者基于Web开发的A ...
- 三部曲搭建本地nuget服务器(图文版)
下载Demo: 1.新建web的空项目 2.引入nuget包 3.修改配置文件config(可以默认) 运行效果:
- [zepto]源码学习
$() : zepto选择器,与jquery选择器类似,但是不支持jquery的拓展css支持(:first,:eq,:last...) $("div")选择页面内的全部div元素 ...