MySQL的select(极客时间学习笔记)
查询语句
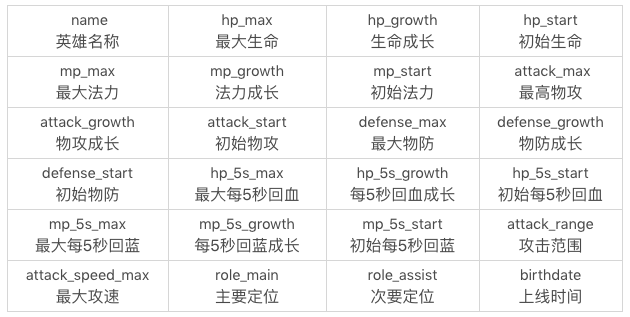
首先, 准备数据, 地址是: https://github.com/cystanford/sql_heros_data, 除了id以外, 24个字段的含义如下:
查询
查询分为单列查询, 多列查询, 全部查询等等:
SELECT name FROM heros; // 单列查询
SELECT name, hp_max, mp_max, attack_max, defense_max FROM heros; // 多列查询
SELECT * FROM heros; // 全部查询
学习阶段可以使用SELECT *, 但是在生产环境不要用, 因为效率会非常低.
起别名
起别名是一种技巧, 可以对原有名称进行简化, 让SQL语句看起来更加精简, 这个在多表连接查询的时候非常有用:
SELECT name AS n, hp_max AS hm, mp_max AS mm, attack_max AS am, defense_max AS dm FROM heros; // 起别名查询
查询常数
SELECT 查询可以对常数进行查询, 简单说就是在SELECT查询结果中增加一列固定的常数列. 一般用于整合不同的数据源, 用常数作为这个表的标记.
SELECT '王者荣耀' as platform, name FROM heros; // 查询常数
虚构了一个platform字段, 注意的是, 字符串常数要是用单引引起来, 否则会被当做列名来进行查询, 会报错, 如果是数字的话不需要添加单引号.
去除重复行
去除重复行是个非常少实用的操作, 关键字是DISTINCT:
SELECT DISTINCT attack_range FROM heros;
SELECT DISTINCT attack_range, name FROM heros
需要注意的是:
- DISTINCT需要放在所有的列名之前, 也就是SELECT 之后.
- DISTINCT其实是对后面所有列名的组合进行去除, 并不是对某一列进行去重. 这也是为什么DISTINCT要放在所有的列名之前的原因.
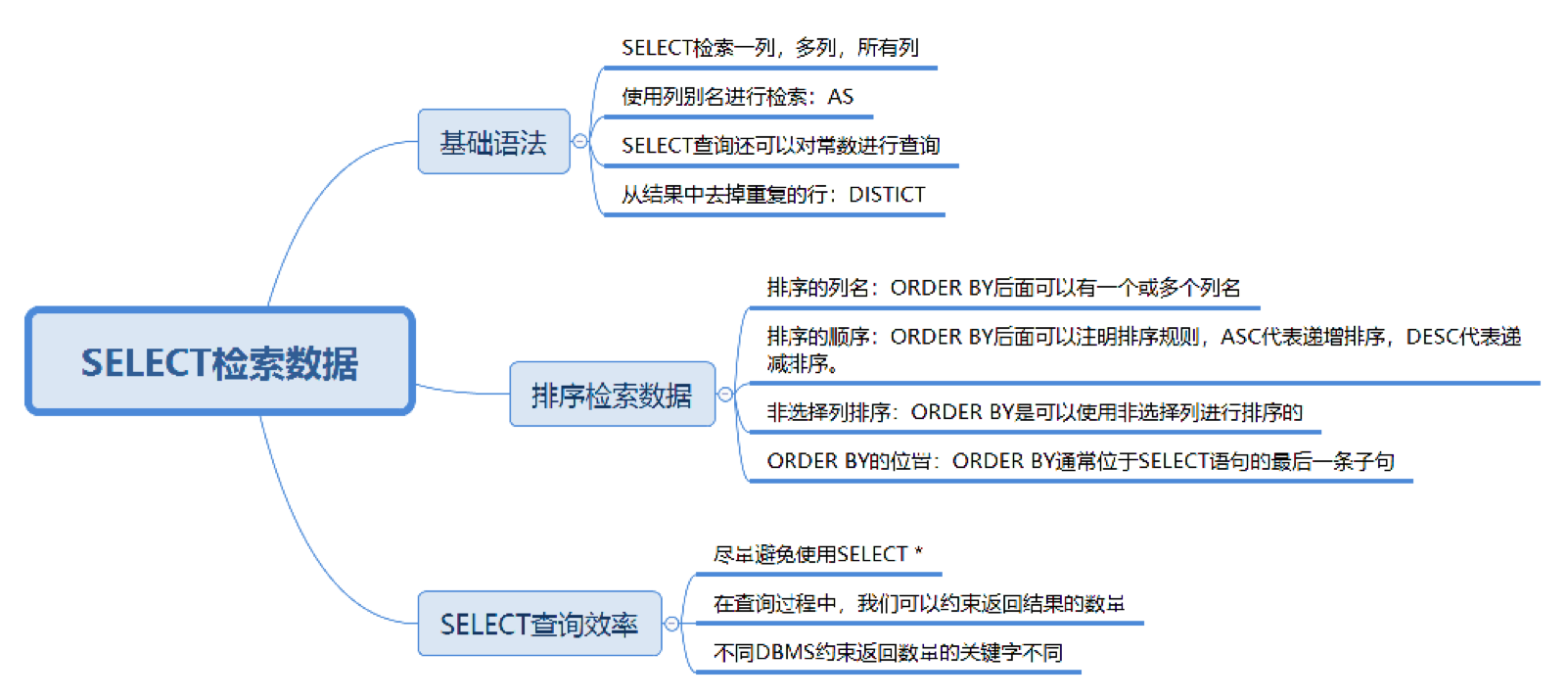
排序检索数据
检索数据的时候, 可以按照某种顺序来进行结果的返回, 比如说查询所有的英雄, 按照最大生命从高到低的顺序进行排列, 这个时候排序就要使用到 ORDER BY 子句了, 注意点如下:
- 排序的列名: ORDER BY后面可以有一个或多个列名, 如果是多个列名进行排序, 会按照后面第一个列先进行排序, 当第一个列的值相同的时候, 再按照第二个列进行排序, 以此类推.
- 排序的顺序: ORDER BY后面可以注明排序规则, ASC代表递增排序, DESC代表递减排序, 没有注明规则, 默认是递增排序. 还有对数值类型字段的排序很容易理解, 那如果是文本数据呢? 需要参考数据库的设置方式, 才可以进行判断.
- 非选择列排序: ORDER BY 可以使用非选择列进行排序, 也就是说SELECT后面没有这个列名, 同样可以放到ORDER BY后面进行排序.
- ORDER BY的位置: ORDER BY通常位于SELECT语句的最后一条子句, 否则会报错.
SELECT name, hp_max FROM heros ORDER BY hp_max DESC ; // 最大生命排序
SQL:SELECT name, hp_max FROM heros ORDER BY mp_max, hp_max DESC; // 最大法力升序, 法力相同, 生命值降序排序
约束返回结果的数量
约束返回结果的数量, 使用LIMIT关键字.
SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 5; // 最大生命值从高到低排序并返回前五条数据
注意的是在不同的DBMS中, 使用的关键字可能不同. 在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 关键字,而且需要放到 SELECT 语句的最后面。如果是 SQL Server 和 Access,需要使用 TOP 关键字
SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC;
如果是 DB2,使用FETCH FIRST 5 ROWS ONLY这样的关键字
SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY;
如果是 Oracle,你需要基于 ROWNUM 来统计行数:
SQL:SELECT name, hp_max FROM heros WHERE ROWNUM <=5 ORDER BY hp_max DESC;
约束返回结果数量可以减少数据表的网络传输量, 可以提升查询效率.
SELECT的执行顺序
这里要说的是两个顺序, 一个是关键字的顺序, 一个是SELECT语句的执行顺序:
- 关键字的顺序:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
- SELECT语句的执行顺序
FROM > WHERE > GROUP BY > HAVING > SELECT 的字段 > DISTINCT > ORDER BY > LIMIT
一条SQL语句, 关键字顺序和执行顺序如下:
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
在SELECT语句执行这些步骤的时候, 每个步骤都会生成一张虚拟表, 然后将这个虚拟表传入下一个步骤作为输入. 但是这些步骤是隐含在SQL的执行过程中, 对我们是不可见的.
SQL的执行原理
SELECT是先执行FROM这一步的, 这个阶段, 如果是多张表联查, 会经历下面的步骤:
- 首先通过笛卡尔积, 得到虚拟表vt(virtual table)1-1.
- 通过ON进行筛选, 在虚拟表vt1-1的基础上进行筛选, 得到虚拟表vt1-2.
- 添加外部行. 如果使用的是左连接、右连接或者是全连接, 就会涉及外部行, 也就是虚拟表v1-2的基础上增加外部行, 得到虚拟表vt1-3.
两张以上的表, 会重复上面的步骤, 直到所有的表都被处理完成, 这个过程得到的最后结论就是现在的原始数据.
拿到原始数据之后, 就可以在这个基础上再进行WHERE阶段了. 这个过程会再次得到一个虚拟表,假设为vt2.
之后进入第三步和第四步, 也就是GROUP BY和HAVING阶段, 在vt2上进行分组和分组过滤, 得到中间的虚拟表vt3.
上面筛序就完成了, 接下来进入到SELECT阶段, 当然, 是先查询出所需要的列(字段), 之后就会进入到DISTINCT阶段, 这个也是两个阶段, 也会产生虚拟表.
字段选择并过滤重复之后就会进入到ORDER BY阶段进行排序, 再次得到虚拟表.
最后进入LIMIT阶段, 得到最终的结果.
在一条SQL中, 不存在的关键字, 中间的那部分阶段就会省略, 这些就是底层的原理.(疑惑是查询字段会使用到别名这些, 这些又是如何识别的呢?)
COUNT(*)的优化
- 一般情况下:
COUNT(*) = COUNT(1) > COUNT(字段), 所以尽量使用COUNT(*),当然如果你要统计的是就是某个字段的非空数据行数,那另当别论。毕竟执行效率比较的前提是要结果一样才行。 - 如果要统计
COUNT(*),尽量在数据表上建立二级索引,系统会自动采用key_len小的二级索引进行扫描,这样当我们使用SELECT COUNT(*)的时候效率就会提升,有时候提升几倍甚至更高都是有可能的。
MySQL的select(极客时间学习笔记)的更多相关文章
- MYSQL实战-------丁奇(极客时间)学习笔记
1.基础架构:一条sql查询语句是如何执行的? mysql> select * from T where ID=10: 2.基础架构:一条sql更新语句是如何执行的? mysql> upd ...
- MySQL的过滤(极客时间学习笔记)
数据过滤 SQL的数据过滤, 可以减少不必要的数据行, 从而可以达到提升查询效率的效果. 比较运算符 在SQL中, 使用WHERE子句对条件进行筛选, 筛选的时候比较运算符是很重要. 上面的比较运算符 ...
- Mysql中的sql是如何执行的 --- 极客时间学习笔记
MySQL中的SQL是如何执行的 MySQL是典型的C/S架构,也就是Client/Server架构,服务器端程序使用的mysqld.整体的MySQL流程如下图所示: MySQL是有三层组成: 连接层 ...
- SQL的概念与发展 - 极客时间学习笔记
了解SQL SQL的两个重要标准是SQL92和SQL99. SQL语言的划分 DDL,也叫Data Definition Language,也就是数据定义语言,用来定义数据库对象,包括数据库.数据表和 ...
- DDL创建数据库,表以及约束(极客时间学习笔记)
DDL DDL是DBMS的核心组件,是SQL的重要组成部分. DDL的正确性和稳定性是整个SQL发型的重要基础. DDL的基础语法及设计工具 DDL的英文是Data Definition Langua ...
- java并发编程实践——王宝令(极客时间)学习笔记
1.并发 分工:如何高效地拆解任务并分配给线程 同步:线程之间如何协作 互斥:保证同一时刻只允许一个线程访问共享资源 Fork/Join 框架就是一种分工模式,CountDownLatch 就是一种典 ...
- Mysql实战45讲 06讲全局锁和表锁:给表加个字段怎么有这么多阻碍 极客时间 读书笔记
Mysql实战45讲 极客时间 读书笔记 Mysql实战45讲 极客时间 读书笔记 笔记体会: 根据加锁范围:MySQL里面的锁可以分为:全局锁.表级锁.行级锁 一.全局锁:对整个数据库实例加锁.My ...
- Mysql实战45讲 05讲深入浅出索引(下)极客时间 读书笔记
极客时间 Mysql实战45讲 04讲深入浅出索引(下)极客时间 笔记体会: 回表:回到主键索引树搜索的过程,称为回表覆盖索引:某索引已经覆盖了查询需求,称为覆盖索引,例如:select ID fro ...
- mysql实战45讲 (三) 事务隔离:为什么你改了我还看不见 极客时间读书笔记
提到事务,你肯定不陌生,和数据库打交道的时候,我们总是会用到事务.最经典的例子就是转账,你要给朋友小王转100块钱,而此时你的银行卡只有100块钱. 转账过程具体到程序里会有一系列的操作,比如查询余额 ...
随机推荐
- 安装quickLook插件以及解决如何不能读取offic问题
目录 @(安装quickLook插件) quickLook插件是Mac上的快速浏览的一个功能,现在win10系统上也能安装插件,这个插件可以快速浏览txt,doc,图片,表格等文件如下图: 我认为最方 ...
- 渗透测试学习 二十三、常见cms拿shell
常见cms 良精.科讯.动易.aspcms.dz 米拓cms.phpcms2008.帝国cms.phpv9 phpweb.dedecms 良精 方法: 1.数据库备份拿shell 上传图片——点击数据 ...
- .Net Core使用Swagger来对接口文档化
参考文档来源:https://www.cnblogs.com/yilezhu/p/9241261.html 官方地址 https://swagger.io/ 代码即接口文档,接口文档即代码 使用.ne ...
- Verilog语言框架
一.常用关键字
- Python股票历史数据的获取
获取股票数据的接口很多,免费的接口有新浪.网易.雅虎的API接口,收费的就是证券公司及相应的公司提供的接口.收费试用的接口一般提供的数据只是最近一年或三年的,限制比较多,除非money足够多.所以本文 ...
- 17.Java基础_初探类的private和public关键字
package pack1; public class Student { // 成员变量 private String name; private int age; // get/set方法 pub ...
- day57 choise字段与ajax
一.choice字段. 在django的orm中,创建如同性别,民.族等可选择的字段时,可以选择使用choice字段进行定义. 这样的定义可以使用简单的数字代替数据量大的字符,减少数据库的负担. ch ...
- postman(十二):发送携带md5签名、随机数等参数的请求
想起来之前在借助百度翻译接口做翻译小工具的时候,需要把参数进行md5加密后再传输. 而在平时的接口测试工作中难免会遇到类似这种请求参数,比如md5加密.时间戳.随机数等等.固然可以先计算出准确的参数, ...
- Codeforces Round #575 (Div. 3) D2. RGB Substring (hard version) 水题
D2. RGB Substring (hard version) inputstandard input outputstandard output The only difference betwe ...
- ubuntu18.04下安装无线网卡驱动心得
联想Lenovo的笔记本,装完系统wifi显示找不到适配器. lspci | grep Wireless 显示无线网卡类型为博通的BCM43162. 网上一查,果然有问题. apt install f ...