[机器学习] SVM——Hinge与Kernel
Support Vector Machine
[学习、内化]——讲出来才是真的听懂了,分享在这里也给后面的小伙伴点帮助。
learn from:
https://www.youtube.com/watch?v=QSEPStBgwRQ&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49&index=29
台湾大学李宏毅教授,讲授课程很用心,能把我之前看过却不理解的知识很易懂、精彩的讲出来——respect
1、SVM
SVM是一个经典的二分类、监督学习算法。与logistic regression很像(需要先学此基础),主要独特之处有两点:
1.loss fuction 用 Hinge Loss。
2.模型 f(x) 使用了 kernel method。
下面依次理解这两个关键,来学习SVM。
2、Hinge Loss
2.1
SVM 算法结构与 logistic regression 或者 binary classification 基本一样:

在解决上面原L(f)不能做梯度下降时,与logistic regression使用 sigmoid + cross entropy不同,使用Hinge Loss,从而产生了Linear SVM。
Hinge:
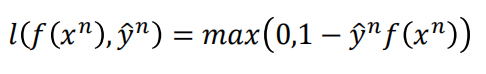
logistic regression 与 Linear SVM两个算法唯一的不同之处就是使用了不同的loss function,前者使用的sigmoid+cross,而后者用 hinge 。

2.2
下面讲讲 loss function 那些事,理解这些后,将对 SVM 的 HInge 有很深的理解。
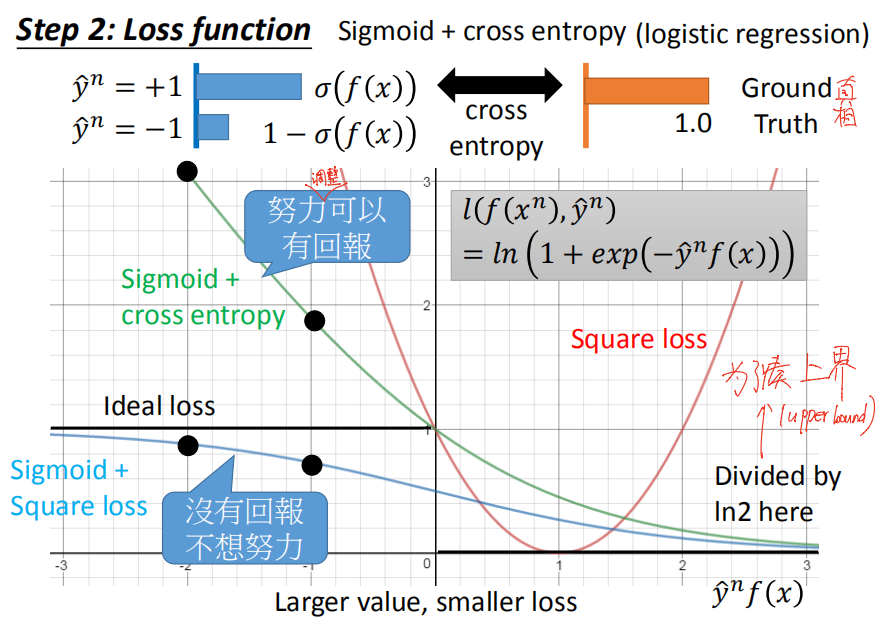
因为原本的loss fuction(下图中标①的loss function,下文简称L①)不能微分所以无法做梯度下降 ,所以我们要做的就是用一个可以微分的loss function(下文简称L②)来近似代替L①。我们知道L①的作用:当预测值与实际值相等时,L=0,不相等时,L=1(函数括号里成立时,函数值=0,否则为1,不清楚的可以查一下 kronecker 记号)。binary classification 中:
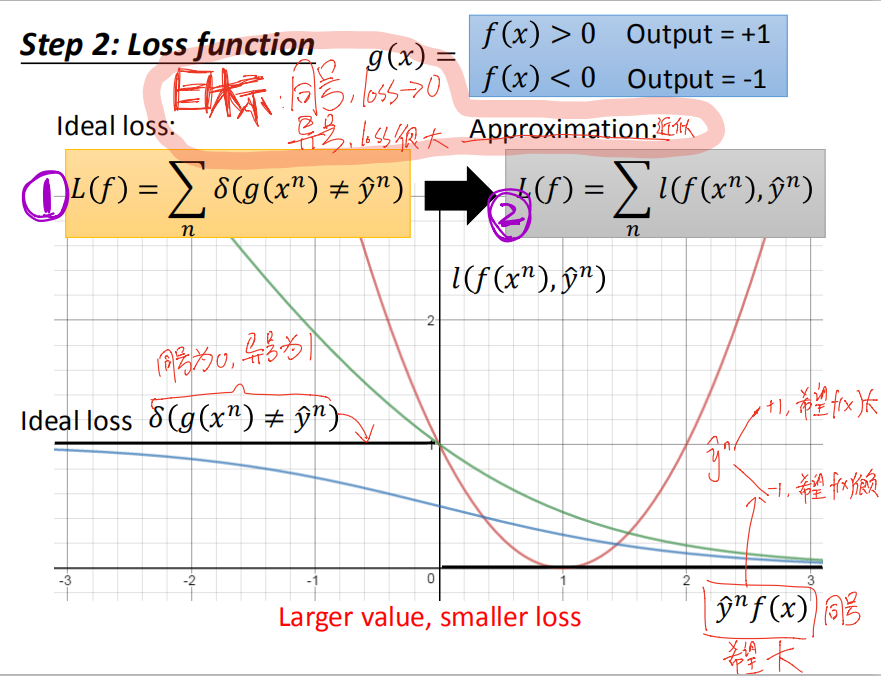
而y只等于+1或-1,所以预测正确时,即g(x)与y相等时,y一定与f(x)同号,预测错误时异号。(以0点为界,y·f(x)越大即就是预测正确,y·f(x)越小即为预测错误,下图中用yf(x)作图分析并说Larger value, smaller loss,应该是这样理解的)所以我们需要找这样一个L②来代替L①:当同号时,loss接近0;当异号时,loss很大。
下面是尝试使用不同的L②:
square loss: 不行。
连我们上面分析L②应有的性质都不满足,而已早在 logistic regression 里就知道了 square loss 是不适用这种离散型任务的。
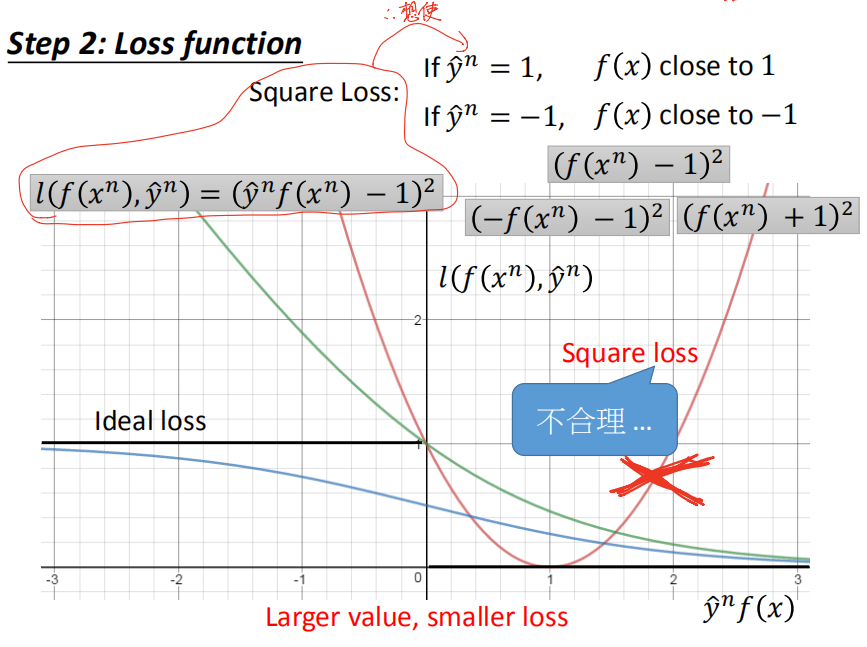
sigmoid+square
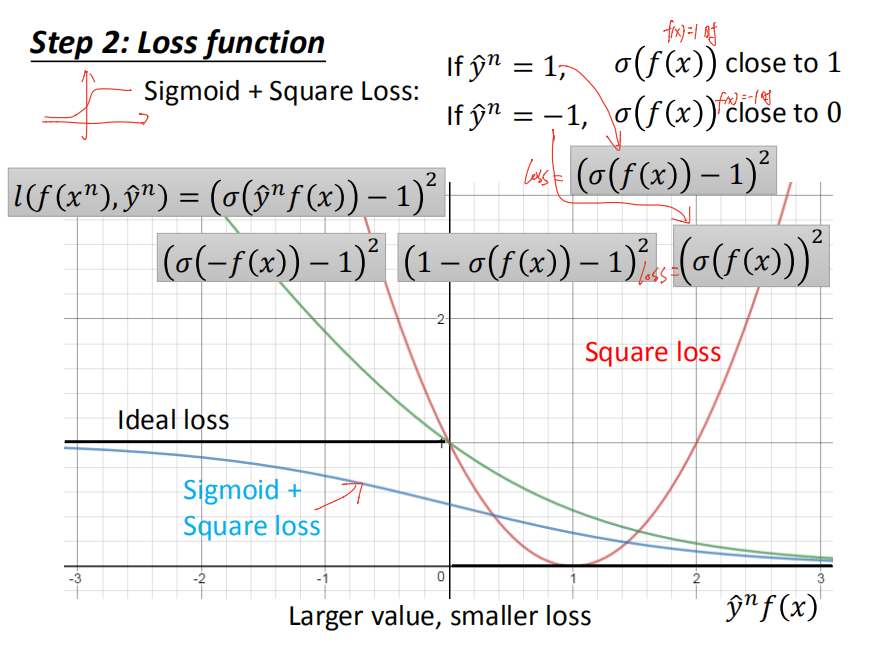
sigmoid+cross entropy
Hinge
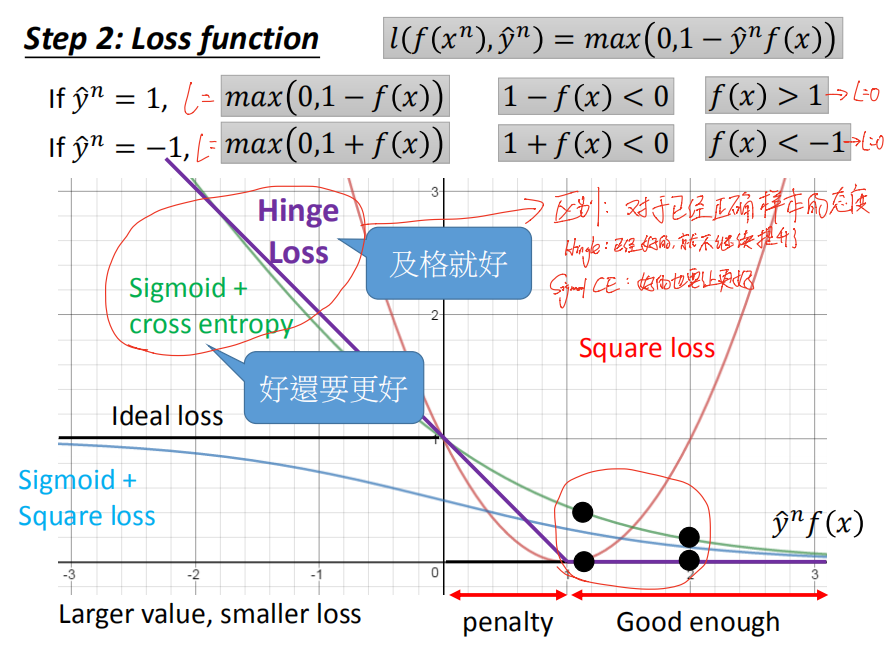
Hinge 与 sigmiod+cross entropy 这两个loss function的区别:对于结果已经正确的样本数据,hinge 就不再继续产生loss用于继续提升,而sigmiod+cross entropy 会继续产生loss 使其再继续远离刚刚能正确分类的点(不满足于刚刚超过阈值)。
2.3
确定好了loss function之后,就可以做梯度下降了。

c(w)有很多都为0,不=0的那些c(w)即为 support vector.
SVM有很好的鲁棒性(robust),因为有很多数据(即那些c(w)=0的)不会影响结果,而 logistic regression 相比就没有这样的鲁棒性。
2.4 Linear SVM的另一种表示形式

3、kernel trick
下面是花书(Deep Learning)中关于SVM的部分,主要就是在说kernel,说的比较宏观比较笼统,先看一下有利于下面深入学习。

3.1
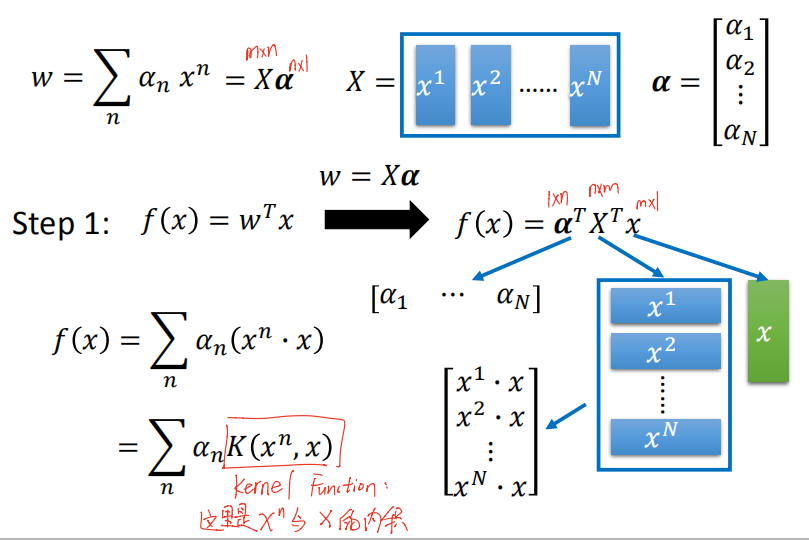
先概括一下我自己理解的kernel trick:利用很多机器学习算法的模型参数都能写成样本间内积的特点,利用核函数代替先转换空间(即非线性ϕ(x))再内积的方法,来学习非线性模型。
先知道一个事实:w是x的线性组合。
听起来可能难以相信:训练出的模型参数w是数据x的线性组合?解释一下:梯度下降更新参数w时,c(w)只能取0,±1,取0不用说了,取±1时,w就是在±学习率*x
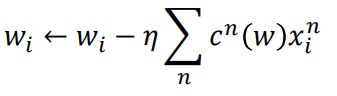
下面看直接看PPT式子就行了。


3.2 径向基函数
径向基函数是一个取值仅仅依赖于离原点距离的实值函数,也就是Φ(x)=Φ(‖x‖),或者还可以是到任意一点c的距离,c点称为中心点,也就是Φ(x,c)=Φ(‖x-c‖)。任意一个满足Φ(x)=Φ(‖x‖)特性的函数Φ都叫做径向基函数,标准的一般使用欧氏距离(也叫做欧式径向基函数),尽管其他距离函数也是可以的。在神经网络结构中,可以作为全连接层和ReLU层的主要函数。

3.3 与神经网络
3.3.1 sigmiod kernel 与神经网络

用sigmiod kernel就相当于一个只有一层hidden layer的神经网络。
每个神经元的参数就是一个输入的data。神经元的个数 = support vector的个数。
3.3.1 SVM 与神经网络
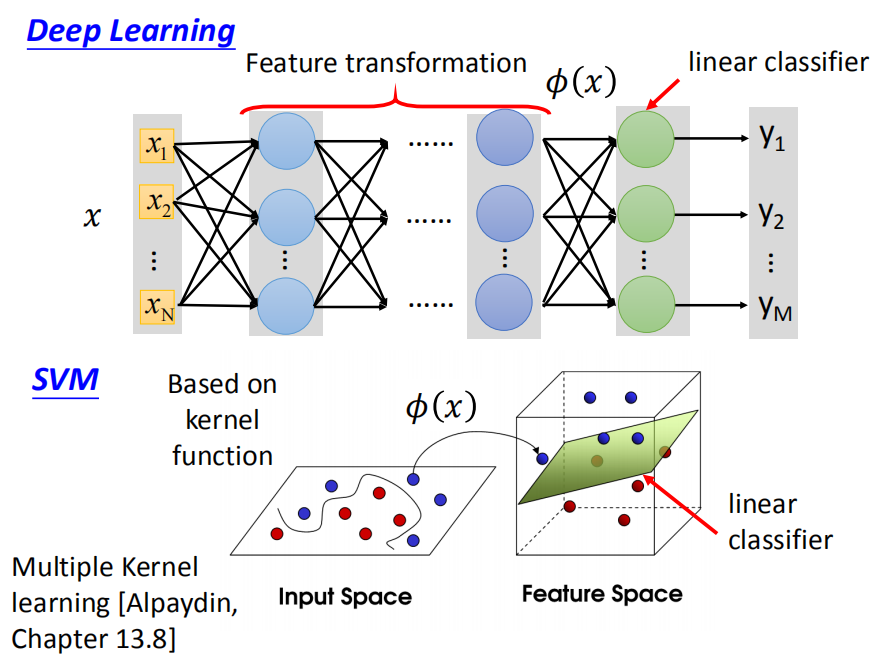
其实kernel是可学习的,但是可学习性没有神经网络参数强,只能给几点kernel然后学习出他们的组合。
只有一个kernel相当于只有一层隐藏层,由多个Kernel组合相当于由多个隐藏层。
[机器学习] SVM——Hinge与Kernel的更多相关文章
- [机器学习]SVM原理
SVM是机器学习中神一般的存在,虽然自深度学习以来有被拉下神坛的趋势,但不得不说SVM在这个领域有着举足轻重的地位.本文从Hard SVM 到 Dual Hard SVM再引进Kernel Trick ...
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
- 机器学习——SVM详解(标准形式,对偶形式,Kernel及Soft Margin)
(写在前面:机器学习入行快2年了,多多少少用过一些算法,但由于敲公式太过浪费时间,所以一直搁置了开一个机器学习系列的博客.但是现在毕竟是电子化的时代,也不可能每时每刻都带着自己的记事本.如果可以掏出手 ...
- 机器学习——支持向量机(SVM)之核函数(kernel)
对于线性不可分的数据集,可以利用核函数(kernel)将数据转换成易于分类器理解的形式. 如下图,如果在x轴和y轴构成的坐标系中插入直线进行分类的话, 不能得到理想的结果,或许我们可以对圆中的数据进行 ...
- 程序员训练机器学习 SVM算法分享
http://www.csdn.net/article/2012-12-28/2813275-Support-Vector-Machine 摘要:支持向量机(SVM)已经成为一种非常受欢迎的算法.本文 ...
- 机器学习技法:05 Kernel Logistic Regression
Roadmap Soft-Margin SVM as Regularized Model SVM versus Logistic Regression SVM for Soft Binary Clas ...
- 机器学习--------SVM
#SVM的使用 (结合具体代码说明,代码参考邹博老师的代码) 1.使用numpy中的loadtxt读入数据文件 data:鸢尾花数据 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3 ...
- 机器学习—SVM
一.原理部分: 依然是图片~ 二.sklearn实现: import pandas as pd import numpy as np import matplotlib.pyplot as plt i ...
- logistic regression svm hinge loss
二类分类器svm 的loss function 是 hinge loss:L(y)=max(0,1-t*y),t=+1 or -1,是标签属性. 对线性svm,y=w*x+b,其中w为权重,b为偏置项 ...
随机推荐
- 每日一问:浅谈 onAttachedToWindow 和 onDetachedFromWindow
基本上所有 Android 开发都会接触到 onCreate().onDestory().onStart().onStop() 等这些生命周期方法,但却不是所有人都会去关注到 onAttachXXX( ...
- surging 微服务引擎 2.0 会有多少惊喜?
surging 微服务引擎从2017年6月至今已经有两年的时间,这两年时间有多家公司使用surging 服务引擎,并且有公司搭建了CI/CD,并且使用了k8s 集群,这里我可以说下几家公司的服务搭建情 ...
- Spark学习之路(十四)—— Spark Streaming 基本操作
一.案例引入 这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计.项目依赖和代码实现如下: <dependency> <groupId>org.apac ...
- 【Dubbo】Dubbo+ZK基础入门以及简单demo
参考文档: 官方文档:http://dubbo.io/ duboo中文:https://dubbo.gitbooks.io/dubbo-user-book/content/preface/backgr ...
- GO代码生成代码小思小试
推进需求 GO 项目,可整体生成一个运行文件到处跑,是极爽之事.但如果有资源文件要得带着跑,则破坏了这种体验. 例如下边这个项目结构,resource 目录下为资源文件,main.go 中会通过路径引 ...
- EXPLAIN说明
列名 类型 解释 id SELECT语句的ID编号,优先执行编号较大的查询,如果编号相同,则从上向下执行 select_type SIMPLE 一条没有UNION或子查询部分的SELECT语句 P ...
- java Http工具类
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ...
- 蓝桥杯:最大的算式(爆搜 || DP)
http://lx.lanqiao.cn/problem.page?gpid=T294 题意:中文题意. 思路:1.一开始想的是,乘号就相当于隔板,把隔板插入到序列当中,同一个隔板的就是使用加法运算, ...
- java中session和application的用法
Session的用法 首先创建2个jsp文件t1.jsp t2.jsp 在t1.jsp <% //设置session的键与值 session.setAttribute("abc&qu ...
- 不使用 ASR 将虚机还原到另一个数据中心
背景 在 Azure 上可能会遇到一个场景是将一台虚机搬到另一台数据中心,在不借助 ASR 的情况下我们该如何做? 因为 ASR 在云上更多的场景是用于灾备到异地.对于虚机的相关信息主要的是磁盘和网络 ...