TensorFlow笔记-文件读取
小数量数据读取
这些只用于可以完全加载到内存中的小型数据集:
1,储存在常数中
2,储存在变量中,初始化后,永远不改变它的值
使用常量
training_data = ...
training_labels = ...
with tf.Session():
input_data = tf.constant(training_data)
input_labels = tf.constant(training_labels)
使用变量的方式,您就需要在数据流图建立后初始化这个变量。
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,
shape=training_data.shape)
label_initializer = tf.placeholder(dtype=training_labels.dtype,
shape=training_labels.shape)
input_data = tf.Variable(data_initalizer, trainable=False, collections=[])
input_labels = tf.Variable(label_initalizer, trainable=False, collections=[])
...
sess.run(input_data.initializer,
feed_dict={data_initializer: training_data})
sess.run(input_labels.initializer,
feed_dict={label_initializer: training_lables})
设定trainable=False 防止后面被数据流图给改变,也就是不会在训练的时候更新它的值。
设定collections=[]可以防止GraphKeys.VARIABLES收集后做为保存和恢复的中断点。设定这些标志,是为了减少额外的开销。
文件读取:
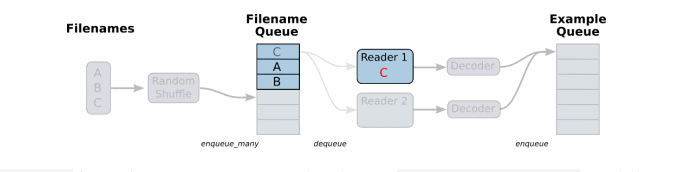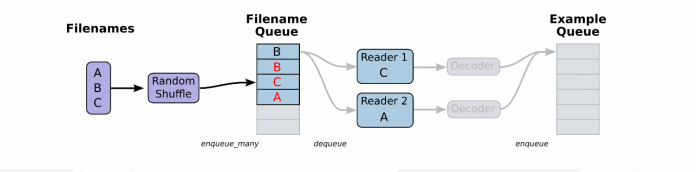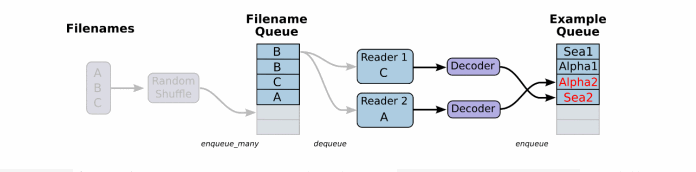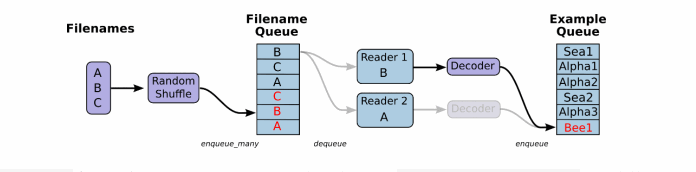
一般数据文件格式有文本、excel和图片数据。那么TensorFlow都有对应的解析函数,除了这几种。还有TensorFlow指定的文件格式。
标准TensorFlow格式
TensorFlow还提供了一种内置文件格式TFRecord,二进制数据和训练类别标签数据存储在同一文件。模型训练前图像等文本信息转换为TFRecord格式。TFRecord文件是protobuf格式。数据不压缩,可快速加载到内存。TFRecords文件包含 tf.train.Example protobuf,需要将Example填充到协议缓冲区
数据读取实现
文件队列生成函数
tf.train.string_input_producer(string_tensor, num_epochs=None, shuffle=True, seed=None, capacity=32, name=None)
产生指定文件张量
文件阅读器类
class tf.TextLineReader
阅读文本文件逗号分隔值(CSV)格式
tf.FixedLengthRecordReader
要读取每个记录是固定数量字节的二进制文件
tf.TFRecordReader
读取TfRecords文件
解码
由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
tf.decode_csv(records,record_defaults,field_delim = None,name = None)将CSV转换为张量,与tf.TextLineReader搭配使用
tf.decode_raw(bytes,out_type,little_endian = None,name = None) 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用
生成文件队列
将文件名列表交给tf.train.string_input_producer函数。
string_input_producer来生成一个先入先出的队列,文件阅读器会需要它们来取数据。string_input_producer提供的可配置参数来设置文件名乱序和最大的训练迭代数,QueueRunner会为每次迭代(epoch)将所有的文件名加入文件名队列中,如果shuffle=True的话,会对文件名进行乱序处理。
一过程是比较均匀的,因此它可以产生均衡的文件名队列。
这个QueueRunner工作线程是独立于文件阅读器的线程,因此乱序和将文件名推入到文件名队列这些过程不会阻塞文件阅读器运行。
根据你的文件格式,选择对应的文件阅读器,然后将文件名队列提供给阅读器的 read 方法。阅读器的read方法会输出一个键来表征输入的文件和其中纪录(对于调试非常有用),同时得到一个字符串标量,这个字符串标量可以被一个或多个解析器,或者转换操作将其解码为张量并且构造成为样本。
# 读取CSV格式文件
# 1、构建文件队列 # 2、构建读取器,读取内容 # 3、解码内容 # 4、现读取一个内容,如果有需要,就批处理内容
import tensorflow as tf
import os
def readcsv_decode(filelist):
"""
读取并解析文件内容
:param filelist: 文件列表
:return: None
""" # 把文件目录和文件名合并
flist = [os.path.join("./csvdata/",file) for file in filelist] # 构建文件队列
file_queue = tf.train.string_input_producer(flist,shuffle=False) # 构建阅读器,读取文件内容
reader = tf.TextLineReader() key,value = reader.read(file_queue) record_defaults = [["null"],["null"]] # [[0],[0],[0],[0]] # 解码内容,按行解析,返回的是每行的列数据
example,label = tf.decode_csv(value,record_defaults=record_defaults) # 通过tf.train.batch来批处理数据
example_batch,label_batch = tf.train.batch([example,label],batch_size=9,num_threads=1,capacity=9) with tf.Session() as sess: # 线程协调员
coord = tf.train.Coordinator() # 启动工作线程
threads = tf.train.start_queue_runners(sess,coord=coord) # 这种方法不可取
# for i in range(9):
# print(sess.run([example,label])) # 打印批处理的数据
print(sess.run([example_batch,label_batch])) coord.request_stop() coord.join(threads) return None if __name__=="__main__":
filename_list = os.listdir("./csvdata")
readcsv_decode(filename_list)
每次read的执行都会从文件中读取一行内容,注意,(这与后面的图片和TfRecords读取不一样),decode_csv操作会解析这一行内容并将其转为张量列表。
如果输入的参数有缺失,record_default参数可以根据张量的类型来设置默认值。在调用run或者eval去执行read之前,你必须调用tf.train.start_queue_runners来将文件名填充到队列。否则read操作会被阻塞到文件名队列中有值为止。
TensorFlow笔记-文件读取的更多相关文章
- TensorFlow从0到1之TensorFlow csv文件读取数据(14)
大多数人了解 Pandas 及其在处理大数据文件方面的实用性.TensorFlow 提供了读取这种文件的方法. 前面章节中,介绍了如何在 TensorFlow 中读取文件,本节将重点介绍如何从 CSV ...
- TensorFlow笔记-图片读取
回到上一篇文件的读取分这么几步: # 构造队列 # 1,构造图片文件的队列 file_queue = tf.train.string_input_producer(filelist) # 构造阅读器 ...
- 【学习笔记】tensorflow文件读取
目录 文件读取 文件队列构造 文件阅读器 文件内容解码器 开启线程操作 管道读端批处理 CSV文件读取案例 先看下文件读取以及读取数据处理成张量结果的过程: 一般数据文件格式有文本.excel和图片数 ...
- tensorflow二进制文件读取与tfrecords文件读取
1.知识点 """ TFRecords介绍: TFRecords是Tensorflow设计的一种内置文件格式,是一种二进制文件,它能更好的利用内存, 更方便复制和移动,为 ...
- tensorflow文件读取
1.知识点 """ 注意:在tensorflow当中,运行操作具有依赖性 1.CPU操作计算与IO计算区别: CPU操作: 1.tensorflow是一个正真的多线程,并 ...
- (第二章第一部分)TensorFlow框架之文件读取流程
本章概述:在第一章的系列文章中介绍了tf框架的基本用法,从本章开始,介绍与tf框架相关的数据读取和写入的方法,并会在最后,用基础的神经网络,实现经典的Mnist手写数字识别. 有四种获取数据到Tens ...
- 《python核心编程》笔记——文件的创建、读取和显示
创建文件(makeTextFile.py)脚本提醒用户输入一个尚不存在的文件名,然后由用户输入文件每一行,最后将所有文本写入文本文件 #!/usr/bin/env python 'makeTextFi ...
- Python学习笔记——文件写入和读取
1.文件写入 #coding:utf-8 #!/usr/bin/env python 'makeTextPyhton.py -- create text file' import os ls = os ...
- Head First Python 学习笔记-Chapter3:文件读取和异常处理
第三章中主要介绍了简单的文件读取和简单的异常处理操作. 首先建立文件文件夹:HeadFirstPython\chapter3,在Head First Pythong官方站点下载须要使用的文件:sket ...
随机推荐
- tbox的项目:vm86(汇编语言虚拟机),tbox(类似dlib),gbox(c语言实现的多平台图形库)
https://github.com/tboox/tbox GBOX是一个用c语言实现的多平台图形库,支持windows.linux.mac.ios.android以及其他嵌入式系统. 现在这个项目, ...
- Delphi For Linux Compiler
Embarcadero is about to release a new Delphi compiler for the Linux platform. Here are some of the k ...
- QAbstractItemView为截断的项显示ToolTip(使用事件过滤)
在Qt中想要为QAbstractItemView中长度不够而使得内容被截断的项显示ToolTip,Qt官网有一篇文章介绍使用事件过滤器来显示太长的项,但是没有涵盖图标的情况.显示列头项太长的情况等等, ...
- C#抓取远程Web网页信息的代码
来自:http://www.jb51.net/article/9499.htm 通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析 ...
- 2019年5月23日 AY 程序员调侃语录
我是AY,杨洋,做wpf开发的,最近得了一种病,程序员患得患失综合征.同事说,我年纪在变大,技术跟不上.业余之间,我原创了写了一些语录,给大家中午休息,累疲惫的时候,开心放松下. 1.有很多公司找我谈 ...
- 远程控制卡配置和RAID基本知识
一.远程控制卡配置(戴尔R710)ctrl+eLAN Parameters ==>>远程连接IP地址配置LAN User Configuration ==>>远程连接账号密码配 ...
- 升级vue全家桶过程记录
背景 如果你使用了element-ui的el-tabs组件,并且想要单独升级element-ui至2.10.0,你会发现,使用了el-tabs组件的页面只要打开就卡死.原因是element-ui~2. ...
- happy machine learning(First One)
从前几天起我就开始了愉快的机器学习,这里记录一下学习笔记,我看的是吴恩达老师的视频,这篇博客将会按吴老师的教学目录来集合各优良文章,以及部分的我的个人总结 1. 监督学习与无监督学习 监督:给定一个 ...
- JS工具整理
1.获取今日日期:摘抄地址:https://www.cnblogs.com/carekee/articles/1678041.html getTodayFmt('yyyy-MM-dd') getTod ...
- webpack中添加px2rem-loader
在buid->util.js const px2remLoader = { loader: 'px2rem-loader', options: { remUnit: 75 } } // gene ...